
Математическое моделирование в управлении
Экономические процессы характеризует большое число параметров, взаимосвязь и взаимное влияние которых определяют состояние этой, с точки зрения системного анализа, сложной динамической системы и возможности перехода ее в другие состояния. В этой ситуации решения по оптимальному управлению необходимо принимать на основании многомерного статистического анализа стохастической, неполной информации. Всестороннее изучение деятельности предприятий дает возможность фиксировать значения таких показателей, как производительность труда, индекс снижения себестоимости, рентабельность одновременно с показателями, которые могут оказывать влияние на перечисленные результирующие показатели. К таким воздействующим показателям можно отнести трудоемкость единицы продукции, удельный вес рабочих в составе промышленно-производственного персонала, коэффициент сменности оборудования, премии, фондоотдача и другие. Однако следует учесть, что показатели могут быть взаимосвязаны и, следовательно, могут опосредствовано оказывать влияние на результирующие показатели.
Рассмотрение поведения подобных сложных систем, характерной особенностью которых является наличие управления, присуще системному подходу. Основным методом исследования систем в рамках системного подхода является метод математического моделирования, базирующийся на использовании средств компьютерной техники. Под математическим моделированием понимают способ исследования различных явлений, процессов путем исследования явлений, имеющих разное физическое содержание, но описываемых одинаковыми математическими соотношениями.
Математической моделью реальной системы называется ее описание на каком-либо формальном языке, позволяющее выводить суждения о некоторых чертах поведения этой системы при помощи формальных процедур. Математическая модель может представлять собой функциональные зависимости или графики, уравнения; таблицы или графики, описывающие движение систем и переходы их из одних состояний в другие. Другими словами, математическая модель – это отражение оригинала (системы) в виде функций, уравнений, неравенств, цифр и т.д. Математическая модель – это приближенное описание системы и ее поведения с помощью математической символики. Математическое моделирование – мощный метод познания, а также прогнозирования и управления. Математическое моделирование занимает ведущее место среди других методов исследования, особенно благодаря компьютерной технике, возможности которой позволяют исследование поведения системы осуществлять с помощью машинного эксперимента.
В настоящее время трудно представить себе исследование и прогнозирование экономических явлений, без использования эконометрического моделирования на основе статистических данных, регрессионного анализа и других методов, опирающихся на теорию вероятностей. Экономические законы все более усложняются и, следовательно, в соответствии с законами развития динамических систем должен усиливаться статистический характер законов, их описывающих, который позволяет учитывать влияние случайных факторов.
Таким образом, для выработки оптимального управления сложной системой, каковой является экономический процесс, необходим системный анализ и построение математической модели, которая должна отражать связи между отдельным зависимым параметром и группой влияющих на него показателей, а также связи внутри этой группы, что возможно осуществить методами множественного корреляционного и регрессионного анализа статистических данных. Итак, решение задачи оптимального управления состоит из таких этапов:
- многомерный экономико-статистический анализ показателей производственно–хозяйственной деятельности предприятий;
- составление математической модели задачи оптимизации управления деятельностью предприятий на основании корреляционного и регрессионного анализа статистических данных;
- решение задачи оптимизации, количественное обоснование прогнозируемого результата и рекомендации по его достижению.
Многомерный статистический анализ выполняется средствами надстройки Excel «Пакет анализа». Решение нелинейной задачи оптимизации выполняется средствами надстройки Excel «Поиск решения».
Для успешного выполнения задания приводятся необходимые сведения из теории вероятностей и математической статистики, и устанавливается связь между параметрами теоретического и статистического распределения изучаемых факторных и результативных признаков.
I. Статистический анализ в Excel
§ 1.1 Очистка информации от засорения
При статистическом анализе экономической информации принято считать, что экономические показатели подчиняются нормальному закону распределения. Однако на практике это не всегда верно. Наблюдаются отклонения как односторонние, так и двусторонние. Во избежание искажения значений характеристик распределения при обработке информации необходимо очистить ее от засорения случайными отклонениями. Метод выявления аномальных наблюдений и их удаления из совокупности при обработке многомерной статистической информации может привести к отбрасыванию слишком большого количества точек наблюдения. Известны более четко обоснованные методы обнаружения засорения: метод Смирнова–Граббса проверки максимального наблюдения, критерий Граббса для обнаружения одного экстремального наблюдения, критерий исключения нескольких грубых ошибок как обобщение критерия Граббса. Все они применяются к упорядоченной совокупности (вариационному ряду):
![]() (N
(N![]() 25).
25).
Для проверки максимального и минимального значений на наличие грубой ошибки используются критерии
 и
и 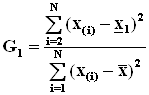 ,
,
где ![]() ,
, ![]() ,
, ![]() .
.
При N>25 экстремальные значения могут быть проверены по критерию S:
![]() ,
,
где ![]() – стандартное отклонение, определенное для всей выборки ;
– стандартное отклонение, определенное для всей выборки ;
![]() – предполагаемый выброс.
– предполагаемый выброс.
При Sрасч < Sкр гипотеза H0: ![]() – выброс отвергается, в противном случае экстремальное значение
– выброс отвергается, в противном случае экстремальное значение ![]() считается грубой ошибкой и из дальнейшего рассмотрения исключается. Критические значения критерия S определяются по таблице . При уровне значимости
считается грубой ошибкой и из дальнейшего рассмотрения исключается. Критические значения критерия S определяются по таблице . При уровне значимости ![]() Sкр так зависит от объема выборки N : значениям N = 30 ; 50 ; 100 ; 1000 соответствуют Sкр = 2,929 ; 3,082 ; 3,283 ; 3,884 .
Sкр так зависит от объема выборки N : значениям N = 30 ; 50 ; 100 ; 1000 соответствуют Sкр = 2,929 ; 3,082 ; 3,283 ; 3,884 .
Парный корреляционный и регрессионный анализ удобно выполнять средствами Excel и надстройки «Пакет анализа» (в меню – Сервис– Анализ данных ).
В данной работе я выполяю статистический анализ совокупности таких показателей производственно-хозяйственной деятельности предприятий (Приложение 1): производительность труда (среднегодовая выработка продукции на одного работника), тыс. грн. Y1, премии и вознаграждения на одного работника, % X8, среднегодовая численность ППП, чел.X11, среднегодовая стоимость основных производственных фондов(ОПФ), тыс. грн. X12, среднегодовой фонд заработной платы ППП, тыс. грн. X13, непроизводственные расходы, %X17.
Выполняю проверки статистических данных на «засорение»:
– копирую все значения показателей на чистый лист;
– упорядочиваю их по возрастанию, выделяю весь столбец без заголовка и нажимаю на панели кнопку сортировки ;
– устанавливаю курсор под последним значением и ввожу функцию Статистическая
– СРЗНАЧ, а затем СТАНДОТКЛ .
– вычисляю значение статистики Sрасч по найденным характеристикам для наибольшего значения, которое нужно подставить в формулу вместо x1 и проверить гипотезу H0 : наибольшее (последнее в столбце) значение – выброс;
– если Sрасч > Sкр (0,05; 50) = 3,082 , это значение является выбросом, и необходимо проверить предыдущее значение , только при этом следует заново определить среднее значение и стандартное отклонение, но уже исключив выброс, как это и выполнено в приведенной таблице;
– проверку на выброс продолжаю до первого значения, для которого гипотеза H0 окажется неправдоподобной, т.е. для которого значение Sрасч окажется меньше Sкр;
– такую же проверку выполняю начиная с наименьшего (первого в столбце) значения, помня о том, что критерий S имеет двустороннюю критическую область, и поэтому следует рассматривать модуль Sрасч.
Такие проверки выполняю для всех показателей. В итоге на новый лист переношу исходные статистические данные, и исключить полностью каждую строку, в которой есть выброс хотя бы одного из показателей. Весь последующий статистический анализ провожу только по очищенным данным. Данные сохраняю в Excel на листе под названием «Очистка от засорения».
§ 1.2 Проверка закона распределения
Предварительный анализ статистических данных заключается в проверке соответствия их предположению о нормальном распределении параметров, для чего строю гистограмму и определяю выборочные числовые характеристики. Для построения гистограммы выполняю такую последовательность действий:
размещаю на рабочем листе Excelстатистические данные наблюдений (без выбросов);
Сервис – Анализ данных – Гистограмма (рис.1);

Рис.1.Выбор инструмента анализа.
- в появившемся диалоговом окне Гистограмма ввожу в поле Входные данные интервал (диапазон) ячеек, содержащий исходные данные, и отмечаю поле Метки, т.к., таблица данных имеет заголовки;
- ввожу в поле Параметры выхода адрес ячейки, с которой должны размещаться выходные данные (выходной интервал) и щелкаю пункт Вывод графика;
- OK.
Гистограммы строю для всех признаков статистических данных и сравниваю их с кривой нормального распределения с целью убедиться, что закон распределения каждого признака близок к нормальному, как на приведенной гистограмме.
Числовые характеристики для всех признаков оцениваются по выборке с помощью инструмента анализа Описательная статистика., вызов которого осуществляется аналогично (см. рис.1 ). В появившемся диалоговом окне Описательная статистика ввожу таким же образом Входные данные и Параметры вывода, только вместо пункта Вывод графика отмечаю пункт Итоговая статистика.
Результаты применения инструмента Описательная статистика к данным наблюдений по результативному признаку Y1 и выбранным факторным признакамприведены на листе Excelпод названием «Проверка закона распределения».
Как видно, результаты Описательной статистики дают возможность оценить справедливость предположения о нормальном распределении признаков: эксцесс и асимметричность невелики, хотя и отличаются от 0. Нормальный закон распределения факторных признаков подтверждается еще и тем, что значения медианы и моды у них совпадают или близки.
§ 1.3 Корреляционный анализ
Предварительный анализ тесноты взаимосвязи параметров многомерной модели осуществляю по оценке корреляционной матрицы генеральной совокупности X по наблюдениям. Для этого использую инструмент Анализ данных в соответствии со следующим алгоритмом:
- размещаю на рабочем листе Excel статистические данные в столбцах с соответствующими заголовками (именами переменных);
- Сервис – Анализ данных – Корреляция;
- в появившемся диалоговом окне Корреляция в соответствующие поля ввожу с помощью мыши входные данные и параметры вывода (см. рис.3 );
- после щелчка мышью по кнопке OK на рабочем листе появится матрица, содержащая оценки парных коэффициентов корреляции.
Отбираю для дальнейшего анализа пары переменных, имеющие наибольшие значения парных коэффициентов корреляции
(![]() 0,4 ), учитывая, что чем меньше коэффициент rij , тем слабее их связь. Такими парами в приведенном примере (рис.3) являются: Y1–X11; Y1–X12; X11–X13; X12–X13; X17–X8.
0,4 ), учитывая, что чем меньше коэффициент rij , тем слабее их связь. Такими парами в приведенном примере (рис.3) являются: Y1–X11; Y1–X12; X11–X13; X12–X13; X17–X8.
Проверяю значимость коэффициентов корреляции на уровне ![]() = 0,05. Поскольку объем выборки для всех признаков одинаков и равен 53, критическое значение rкр для всех пар будет одинаково и в соответствии с таблицей Фишера–Иейтса rкр = rтабл (0,05;53)<rтабл(0,05;50) = 0,273. Поскольку для всех коэффициентов выполняется неравенство
= 0,05. Поскольку объем выборки для всех признаков одинаков и равен 53, критическое значение rкр для всех пар будет одинаково и в соответствии с таблицей Фишера–Иейтса rкр = rтабл (0,05;53)<rтабл(0,05;50) = 0,273. Поскольку для всех коэффициентов выполняется неравенство ![]() > rкр , коэффициенты корреляции всех отобранных пар признаков значимо отличаются от нуля, что подтверждает связь между ними.
> rкр , коэффициенты корреляции всех отобранных пар признаков значимо отличаются от нуля, что подтверждает связь между ними.
Дальнейший анализ статистических данных зависит от размерности принимаемой модели. Простейший вариант – двумерная модель. Учитывая, что в приведенном примере Y1 –результирующий признак, определяющий индекс производительность труда, входит в две пары , следует рассмотреть трехмерную модель Y1–X11–X12,
где X11 – среднегодовая численность ППП, а X12 – среднегодовая стоимость основных производственных фондов(ОПФ). В остальных парах следует определить зависимости между X11 и X13, X12 и X13 , X17 и X8. Здесь X5 –удельный вес рабочих в составе промышленно–производственного персонала, X6 –удельный вес покупных изделий, X7 – коэффициент сменности оборудования.
Таким образом, для математической модели задачи выбора оптимального управления деятельностью предприятия с учетом указанных показателей следует установить зависимости: Y2 = F( X4,X8) – целевая функция;
X6 = φ(X4); X8 = φ(X7); X5 = φ(X7) – ограничения.

Рис.3.Анализ парной корреляции.
§1.4 Регрессионный анализ двумерной модели
В среде Excel для двумерного случая линейной регрессии предусмотрено несколько инструментов : статистические функции (КОРРЕЛ, ЛИНЕЙН, ТЕНДЕНЦИЯ и др.) ; инструмент Регрессия надстройки Пакет анализа ; графические средства при работе с диаграммой – построение линии тренда.
С помощью Пакета анализа можно получить искомую информацию , следуя такому алгоритму:
- разместить на рабочем листе Excel в двух смежных столбцах с соответствующими заголовками статистические данные по двум признакам, подлежащим исследованию (например, X4 и X6);
- Сервис – Анализ данных – Регрессия ;
- в появившемся диалоговом окне Регрессия ввести входные данные в поля Входной интервал Y(X6)и Входной интервал X(X4)и щелкнуть по полю Метки, чтобы заголовки не вошли в интервалы данных;
- ввести параметры вывода в поле Выходной интервал : адрес левого верхнего угла таблицы результатов или щелкнуть поле Новый рабочий лист для вывода на другой лист (см. рис.4);
- для наглядности можно вывести график, щелкнув по полю График подбора ;
- OK.

Рис.4.Работа с диалоговым окном Регрессия.
Результат работы инструмента Регрессия приведен на рис.5. Итак, выборочное уравнение линейной регрессии X6 на X4 имеет вид:
![]()
Выходная таблица содержит коэффициент детерминации R2 = 0,368802, что означает, что полученная модель приблизительно на 37% отражает зависимость удельного веса покупных изделий от трудоемкости единицы продукции. Стандартная ошибка (отклонение результата) ![]() = 0,118415 означает, что 68% реальных значений результирующего признака x6 находится в диапазоне
= 0,118415 означает, что 68% реальных значений результирующего признака x6 находится в диапазоне ![]() 0,118415 от линии регрессии. Это следует из того, что условные распределения нормально распределенной генеральной совокупности при фиксировании различных подмножеств компонент являются нормальными.
0,118415 от линии регрессии. Это следует из того, что условные распределения нормально распределенной генеральной совокупности при фиксировании различных подмножеств компонент являются нормальными.
| ВЫВОД ИТОГОВ | |||||||
Регрессионная статистика | |||||||
| Множественный R | 0,607291 | ||||||
| R-квадрат | 0,368802 | ||||||
| Нормированный R-квадрат | 0,35592 | ||||||
| Стандартная ошибка | 0,118415 | ||||||
| Наблюдения | 51 | ||||||
| Дисперсионный анализ | |||||||
df | SS | MS | F | Значимость F | |||
| Регрессия | 1 | 0,401452 | 0,401452 | 28,63014 | 2,3E-06 | ||
| Остаток | 49 | 0,687078 | 0,014022 | ||||
| Итого | 50 | 1,088529 | |||||
Коэффициенты | Стандартная ошибка | t-статистика | P-Значение | Нижние 95% | Верхние 95% | ||
| Y-пересечение | 0,557512 | 0,051111 | 10,90789 | 1,04E-14 | 0,45480 | 0,66022 | |
| X4 | -0,85062 | 0,158973 | -5,35071 | 2,3E-06 | -1,1701 | -0,5312 | |