Примеры решения типовых заданий
Пример 3.1.По статистическим данным, приведенным в таблице 3.3, построить корреляционное поле зависимости спроса 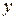 на товар от его цены
на товар от его цены 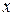 и определить форму связи между результирующим признаком и фактором .
и определить форму связи между результирующим признаком и фактором .
Таблица 3.3. Статистические данные примера 3.1
| Цена товара | Спрос на товар |
| 27,5 |
Решение:
Из вида корреляционного поля (рисунок 3.8) можно сделать вывод о том, что между результирующим признаком и фактором существует обратная зависимость, т.е. с ростом цены спрос на товар уменьшается. Такое поведение спроса в зависимости от цены согласуется с выводами экономической теории. Можно предположить также, что форма связи между результирующим признаком и фактором является линейной.

Рис. 3.8. Корреляционное поле статистической зависимости
между спросом и ценой
Пример 3.2. В таблице 3.4 представлена информация по семи территориям некоторого региона о значениях процентной доли расходов на покупку продовольственных товаров в общих расходах ( ) и значениях среднедневной заработной платы одного работающего ( ).
Таблица 3.4. Статистические данные примера 3.2
| Расходы на покупку продовольственных товаров в общих расходах
(в процентах, )
| Среднедневная заработная плата одного работающего
(в денежных единицах, )
|
| 68,8 | 45,1 |
| 61,2 | 59,0 |
| 59,9 | 57,2 |
| 56,7 | 61,8 |
| 55,0 | 58,8 |
| 54,3 | 47,2 |
| 49,3 | 55,2 |
1. Для характеристики зависимости у от храссчитать параметры следующих регрессий:
а) линейной;
б) степенной;
в) показательной;
г) гиперболической.
2. Оценить каждую модель через среднюю ошибку аппроксимации  , индекс корреляции
, индекс корреляции  и
и  -критерий Фишера.
-критерий Фишера.
Решение:
1а) Для расчета параметров  и
и  линейной модели
линейной модели  решаем систему уравнений (3.2) относительно и .
решаем систему уравнений (3.2) относительно и .
Соответствующие вычисления сведем в таблицу 3.5.
Таблица 3.5. Вычисление параметров и
|
|
| 
| 
| 
| 
| 
| 
| |
| 68,8 | 45,1 | 3102,88 | 2034,01 | 4733,44 | 61,3 | 7,5 | 10,9 | |
| 61,2 | 59,0 | 3610,80 | 3481,00 | 3745,44 | 56,5 | 4,7 | 7,7 | |
| 59,9 | 57,2 | 3426,28 | 3271,84 | 3588,01 | 57,1 | 2,8 | 4,7 | |
| 56,7 | 61,8 | 3504,06 | 3819,24 | 3214,89 | 55,5 | 1,2 | 2,1 | |
| 55,0 | 58,8 | 3234,00 | 3457,44 | 3025,00 | 56,5 | -1,5 | 2,7 | |
| 54,3 | 47,2 | 2562,96 | 2227,84 | 2948,49 | 60,5 | -6,2 | 11,4 | |
| 49,3 | 55,2 | 2721,36 | 3047,04 | 2430,49 | 57,8 | -8,5 | 17,2 | |
| Сумма | 405,2 | 384,3 | 22162,34 | 21338,4 | 23685,76 | 405,2 | 0,0 | 56,7 |
| Среднее | 57,89 | 54,90 | 3166,05 | 3048,34 | 3383,68 | - | - | 8,1 |

| 5,74 | 5,86 | - | - | - | - | - | - |

| 32,92 | 34,34 | - | - | - | - | - | - |
Теперь по формулам (3.3) находим:

Уравнение линейной регрессии имеет вид  . С увеличением среднедневной заработной платы на одну денежную единицу доля расхода на покупку продовольственных товаров снижается в среднем на 0,35 %-ных пункта. Рассчитаем линейный коэффициент парной корреляции:
. С увеличением среднедневной заработной платы на одну денежную единицу доля расхода на покупку продовольственных товаров снижается в среднем на 0,35 %-ных пункта. Рассчитаем линейный коэффициент парной корреляции:

Связь умеренная, обратная.
Определим коэффициент детерминации: 
Изменения результата на 12,7% объясняются влиянием фактора  .
.
Подставляя в уравнение регрессии фактические значения ,определим теоретические (расчетные) значения  . Найдем величину средней ошибки аппроксимации :
. Найдем величину средней ошибки аппроксимации :

В среднем расчетные значения отклоняются от фактических на 8,1%.
Рассчитываем наблюдаемое значение -критерия:  =
=  . По таблице значений -критерия при уровне значимости
. По таблице значений -критерия при уровне значимости  находим
находим  . Так как
. Так как  , то следует принять гипотезу
, то следует принять гипотезу  о случайной природе выявленной зависимости и статистической незначимости параметров уравнения и показателя тесноты связи.
о случайной природе выявленной зависимости и статистической незначимости параметров уравнения и показателя тесноты связи.
1б) Построению уравнения  степенной регрессии предшествует процедура линеаризации переменных. В данном примере линеаризация производится путем логарифмирования обеих частей уравнения:
степенной регрессии предшествует процедура линеаризации переменных. В данном примере линеаризация производится путем логарифмирования обеих частей уравнения:
 ,
,
 ,
,
где 
Все расчеты сведем в таблицу 3.6.
Рассчитаем  и :
и :


Получим линейное уравнение  .
.
Выполнив его потенцирование, получим уравнение регрессии: 
Таблица 3.6. Вычисление параметров и

| 
| 
| 
|
|
|

|
| |
| 1,8376 | 1,6542 | 3,0398 | 2,7364 | 61,0 | 7,8 | 60,8 | 11,3 | |
| 1,7868 | 1,7709 | 3,1642 | 3,1361 | 56,3 | 4,9 | 24,0 | 8,0 | |
| 1,7774 | 1,7574 | 3,1236 | 3,0885 | 56,8 | 3,1 | 9,6 | 5,2 | |
| 1,7536 | 1,7910 | 3,1407 | 3,2077 | 55,5 | 1,2 | 1,4 | 2,1 | |
| 1,7404 | 1,7694 | 3,0795 | 3,1308 | 56,3 | -1,3 | 1,7 | 2,4 | |
| 1,7348 | 1,6739 | 2,9039 | 2,8019 | 60,2 | -5,9 | 34,8 | 10,9 | |
| 1,6928 | 1,7419 | 2,9487 | 3,0342 | 57,4 | -8,1 | 65,6 | 16,4 | |
| Сумма | 12,3234 | 12,1587 | 21,4003 | 21,1355 | 403,5 | 1,7 | 197,9 | 56,3 |
| Среднее | 1,7605 | 1,7370 | 3,0572 | 3,0194 | - | - | 28,27 | 8,0 |

| 0,0425 | 0,0484 | - | - | - | - | - | - |

| 0,0018 | 0,0023 | - | - | - | - | - | - |
Подставляя в данное уравнение фактические значения х, получаем теоретические значения результата . По ним рассчитываем показатели тесноты связи: индекс корреляции  и среднюю ошибку аппроксимации :
и среднюю ошибку аппроксимации :
 ,
, 
Значения показателей и степенной модели указывают, что она несколько лучше линейной регрессии описывает взаимосвязь.
1в) Построению уравнения показательной регрессии  предшествует процедура линеаризации путем логарифмирования обеих частей уравнения:
предшествует процедура линеаризации путем логарифмирования обеих частей уравнения:

 ,
,
где  .
.
Все расчеты сведем в таблицу 3.7.
Вычислим значения параметров регрессии  и
и  :
:


Полученное линейное уравнение принимает вид 
Произведем потенцирование полученного уравнения, получим уравнение регрессии: 
Таблица 3.7. Вычисление параметров и
|
|
| 
| 
|
|
|
|
| |
| 1,8376 | 45,1 | 82,8758 | 2034,01 | 60,7 | 8,1 | 65,61 | 11,8 | |
| 1,7868 | 59,0 | 105,4212 | 3481,00 | 56,4 | 4,8 | 23,04 | 7,8 | |
| 1,7774 | 57,2 | 101,6673 | 3271,84 | 56,9 | 3,0 | 9,00 | 5,0 | |
| 1,7536 | 61,8 | 108,3725 | 3819,24 | 55,5 | 1,2 | 1,44 | 2,1 | |
| 1,7404 | 58,8 | 102,3355 | 3457,44 | 56,4 | -1,4 | 1,96 | 2,5 | |
| 1,7348 | 47,2 | 81,8826 | 2227,84 | 60,0 | -5,7 | 32,49 | 10,5 | |
| 1,6928 | 55,2 | 93,4426 | 3047,04 | 57,5 | -8,2 | 67,24 | 16,6 | |
| Сумма | 12,3234 | 384,3 | 675,9974 | 21338,4 | 403,0 | -1,8 | 200,78 | 56,3 |
| Среднее | 1,7605 | 54,9 | 96,5711 | 3048,34 | - | - | 28,68 | 8,0 |
|
| 0,0425 | 5,86 | - | - | - | - | - | - |
|
| 0,0018 | 34,33 | - | - | - | - | - | - |
Тесноту связи оценим через индекс корреляции  :
:

Связь умеренная. Средняя ошибка аппроксимации в допустимых пределах:  . Показательная функция чуть хуже, чем степенная, описывает изучаемую зависимость.
. Показательная функция чуть хуже, чем степенная, описывает изучаемую зависимость.
1г) Уравнение гиперболической регрессии  линеаризуется заменой
линеаризуется заменой  . Тогда
. Тогда 
Все расчеты сведем в таблицу 3.8.
Вычислим значения параметров регрессии и :


Получим уравнение регрессии  Вычислим индекс корреляции
Вычислим индекс корреляции 
Таблица 3.8. Вычисление параметров и
|
| 
| 
| 
|
|
| 
|
| |
| 68,8 | 0,0222 | 1,5255 | 0.000492 | 61,8 | 7,0 | 49,00 | 10,2 | |
| 61,2 | 0,0169 | 1,0373 | 0.000287 | 56,3 | 4,9 | 24,01 | 8,0 | |
| 59,9 | 0,0175 | 1,0472 | 0,000306 | 56,9 | 3,0 | 9,00 | 5,0 | |
| 56,7 | 0,0162 | 0,9175 | 0,000262 | 55,5 | 1,2 | 1,44 | 2,1 | |
| 0,0170 | 0,9354 | 0,000289 | 56,4 | -1,4 | 1,96 | 2,5 | ||
| 54,3 | 0,0212 | 1,1504 | 0,000449 | 60,8 | -6,5 | 42,25 | 12,0 | |
| 49,3 | 0,0181 | 0,8931 | 0,000328 | 57,5 | -8,2 | 67,24 | 16,6 | |
| Сумма | 405,2 | 0,1291 | 7,5064 | 0,002413 | 405,2 | 0,0 | 194,90 | 56,5 |
| Среднее | 57,9 | 0,0184 | 1,0723 | 0,000345 | - | - | 27,84 | 8,1 |
|
| 5,74 | 0,002145 | - | - | - | - | - | - |
|
| 32,9476 | 0,000005 | - | - | - | - | - | - |
Средняя ошибка аппроксимации в допустимых пределах:  . Для гиперболического уравнения регрессии получена наибольшая оценка тесноты связи
. Для гиперболического уравнения регрессии получена наибольшая оценка тесноты связи  (по сравнению с линейной, степенной и показательной регрессиями).
(по сравнению с линейной, степенной и показательной регрессиями).
2. Для гиперболической регрессии вычислим наблюдаемое значения критерия Фишера:

Тогда при имеем, что  Следовательно, принимается гипотеза о статистически незначимых параметрах уравнения гиперболической регрессии. Поэтому общее качество и этой модели следует признать невысоким.
Следовательно, принимается гипотеза о статистически незначимых параметрах уравнения гиперболической регрессии. Поэтому общее качество и этой модели следует признать невысоким.
Полученные результаты можно объяснить сравнительно невысокой теснотой зависимости между результирующим признаком и фактором , а также небольшим числом наблюдений (  ).
).
Пример 3.3.По данным таблицы 3.9 построить линейное уравнение регрессии, отражающее зависимость стоимости квартиры от ее жилой площади.
Для построенного уравнения вычислить:
1) коэффициент корреляции,
2) коэффициент детерминации;
3) наблюдаемое значение критерия Фишера;
4) стандартные ошибки коэффициентов регрессии;
5) доверительные интервалы коэффициентов регрессии.
Осуществить точечный и интервальный прогнозы по построенной модели в случае, когда площадь квартиры составляет 41 кв. м.
Таблица 3.9. Статистические данные примера 3.3
| № п/п | Стоимость (доллары) | Жилая площадь (кв. м.) |
| 30,2 | ||
| 39,5 |
Решение:
По формулам  ,
,  находим коэффициенты регрессии:
находим коэффициенты регрессии:  ,
,  . Поэтому построенная линейная модель
. Поэтому построенная линейная модель
имеет вид  .
.
Коэффициент регрессии модели показывает, что в среднем увеличение жилой площади квартиры на 1 кв. метр приводит к увеличению ее стоимости на 170,24 доллара.
Расчет линейного коэффициента корреляции и коэффициента детерминации дает  ,
,  . Связь между факторами является высокой, поэтому стоимость квартиры существенно зависит от ее жилой площади. Величина
. Связь между факторами является высокой, поэтому стоимость квартиры существенно зависит от ее жилой площади. Величина  показывает, что изменения стоимости квартиры на 72,81% объясняется размером жилой площади.
показывает, что изменения стоимости квартиры на 72,81% объясняется размером жилой площади.
Расчет дисперсионного отношения Фишера дает значение  . Сравнивая наблюдаемое значение -критерия Фишера с критическим
. Сравнивая наблюдаемое значение -критерия Фишера с критическим  при , получаем, что
при , получаем, что  Таким образом, уравнение регрессии значимо и построенная модель адекватна выборочным данным.
Таким образом, уравнение регрессии значимо и построенная модель адекватна выборочным данным.
Расчет стандартных ошибок коэффициентов регрессии осуществляется по формулам (3.4). В нашем случае имеем 
 ,
,  .
.
Доверительные интервалы для каждого коэффициента регрессии имеют вид:  ,
,  . Зная точечные оценки коэффициентов регрессии, их стандартные ошибки и критическое значение
. Зная точечные оценки коэффициентов регрессии, их стандартные ошибки и критическое значение  -статистики Стьюдента
-статистики Стьюдента  , находим, что
, находим, что  ,
,  .
.
Для вычисления точечного прогноза подставим значение xp=41 в полученное уравнение линейной регрессии  . Получим:
. Получим:  . Таким образом, прогнозируемая по построенной модели стоимость квартиры площадью 41 квадратный метр составляет 7242,65 доллара.
. Таким образом, прогнозируемая по построенной модели стоимость квартиры площадью 41 квадратный метр составляет 7242,65 доллара.
Для построения доверительного интервала прогноза вычислим стандартную ошибку прогноза  по формуле
по формуле  , где
, где  – стандартная ошибка регрессии. В нашем случае
– стандартная ошибка регрессии. В нашем случае  . Поэтому
. Поэтому  . Теперь нижняя и верхняя границы интервала прогноза при и определяются по формулам
. Теперь нижняя и верхняя границы интервала прогноза при и определяются по формулам  и
и  . Окончательно находим, что доверительный интервал прогноза стоимости квартиры имеет вид
. Окончательно находим, что доверительный интервал прогноза стоимости квартиры имеет вид  . Таким образом, значение цены квартиры площадью 41 квадратный метр с вероятностью 0,95 находится в пределах от 6266,78 до 8218,51 доллара.
. Таким образом, значение цены квартиры площадью 41 квадратный метр с вероятностью 0,95 находится в пределах от 6266,78 до 8218,51 доллара.
Пример 3.4.По данным проведенного опроса восьми групп семей (таблица 3.10) о расходах на питание и душевом доходе построить и исследовать линейную регрессионную модель. Найти прогнозное значение результативного фактора при значении фактора, составляющем 110% от среднего уровня душевого дохода семьи.
Таблица 3.10. Статистические данные примера 3.4
| Расходы на продукты питания (тыс. ден. ед.) | 0,9 | 1,2 | 1,8 | 2,2 | 2,6 | 2,9 | 3,3 | 3,8 |
| Душевой доход семьи (тыс. ден. ед.) | 1,2 | 3,1 | 5,3 | 7,4 | 9,6 | 11,8 | 14,5 | 18,7 |
Решение:
Предположим, что связь между доходами семьи и расходами на продукты питания линейная. Для подтверждения нашего предположения построим корреляционное поле (рисунок 3.9) и проанализируем расположение точек наблюдений.

Рис. 3.9. Корреляционное поле примера 3.4
Из графика видно, что точки группируются возле некоторой прямой линии.
Рассчитаем параметры линейного уравнения  парной регрессии. Для этого воспользуемся формулами (3.3):
парной регрессии. Для этого воспользуемся формулами (3.3):

Получили уравнение  . Таким образом, с увеличением душевого дохода семьи на 1000 денежных единиц расходы на питание увеличиваются на 169 денежных единиц.
. Таким образом, с увеличением душевого дохода семьи на 1000 денежных единиц расходы на питание увеличиваются на 169 денежных единиц.
Как было указано выше, уравнение линейной регрессии всегда дополняется показателем тесноты связи – линейным коэффициентом корреляции rxy. В нашем случае  Близость коэффициента корреляции к 1 указывает на тесную линейную связь между признаками. По шкале Чеддока теснота этой связи характеризуется как весьма высокая.
Близость коэффициента корреляции к 1 указывает на тесную линейную связь между признаками. По шкале Чеддока теснота этой связи характеризуется как весьма высокая.
Коэффициент детерминации  показывает, что уравнением регрессии объясняется 98,2% дисперсии результативного признака, а на долю прочих факторов приходится лишь 1,8%.
показывает, что уравнением регрессии объясняется 98,2% дисперсии результативного признака, а на долю прочих факторов приходится лишь 1,8%.
Оценим качество уравнения регрессии в целом с помощью F -критерия Фишера. Рассчитаем наблюдаемое значение F -критерия:
 .
.
Критическое значение F -статистики  при уровне значимости равно 4,6.
при уровне значимости равно 4,6.
Так как  , то признается статистическая значимость уравнения в целом.
, то признается статистическая значимость уравнения в целом.
Для оценки статистической значимости коэффициентов регрессии и доверительных интервалов по формулам (3.4) вычислим стандартные ошибки коэффициентов регрессии. В нашем случае имеем  ,
,  .
.
Вычислим наблюдаемые значения t-статистики Стьюдента:
 ,
,  .
.
Критическое значение t-статистики Стьюдента при уровне значимости α = 0,05 равно 2,447. Так как неравенство  выполняется для обоих коэффициентов регрессии, то признается их статистическая значимость.
выполняется для обоих коэффициентов регрессии, то признается их статистическая значимость.
Доверительные интервалы для каждого коэффициента регрессии имеют вид:
, .
Зная точечные оценки коэффициентов регрессии, их стандартные ошибки и критическое значение -статистики Стьюдента  , находим, что
, находим, что
 ,
,  .
.
Средняя ошибка аппроксимации  говорит о хорошей точности уравнения регрессии, т.е. свидетельствует о хорошей подгонке модельных (теоретических) данных к исходным данным.
говорит о хорошей точности уравнения регрессии, т.е. свидетельствует о хорошей подгонке модельных (теоретических) данных к исходным данным.
Итак, качество модели является высоким, а значит, уравнение регрессии пригодно для практического использования (для прогнозирования).
Найдем прогнозное значение результативного фактора при значении признака-фактора, составляющем 110% от среднего уровня дохода семьи. Так как  , то
, то  . Следовательно, необходимо определить прогноз расходов на питание, если душевой доход семьи составляет 9,845 тысяч денежных единиц.
. Следовательно, необходимо определить прогноз расходов на питание, если душевой доход семьи составляет 9,845 тысяч денежных единиц.
Для вычисления точечного прогноза подставим значение  в полученное уравнение линейной регрессии . Получим:
в полученное уравнение линейной регрессии . Получим:  (тысяч денежных единиц). Значит, если душевой доход семьи составляет 9845 денежных единиц, то расходы на питание будут 2489 денежных единиц.
(тысяч денежных единиц). Значит, если душевой доход семьи составляет 9845 денежных единиц, то расходы на питание будут 2489 денежных единиц.
Для построения доверительного интервала прогноза вычислим стандартную ошибку прогноза по формуле ,
где – стандартная ошибка регрессии. В нашем случае  . Поэтому
. Поэтому  . Теперь нижняя и верхняя границы интервала прогноза при и определяются по формулам и . Окончательно находим, что доверительный интервал прогноза имеет вид
. Теперь нижняя и верхняя границы интервала прогноза при и определяются по формулам и . Окончательно находим, что доверительный интервал прогноза имеет вид  . Таким образом, при душевом доходе, равном 9,845 тысяч денежных единиц, значение расходов на питание с вероятностью 0,95 находится в пределах от 2,114 до 2,864 тысяч денежных единиц.
. Таким образом, при душевом доходе, равном 9,845 тысяч денежных единиц, значение расходов на питание с вероятностью 0,95 находится в пределах от 2,114 до 2,864 тысяч денежных единиц.
В заключение на одном графике (рисунок 3.10) изобразим исходные данные и линию регрессии. Из графика видно, что построенная линейная модель достаточно качественно описывает взаимосвязь исследуемых показателей.

Рис. 3.10. Исходные данные и линия регрессии примера 3.4
Пример 3.5.Применив экспериментальный метод, на основе статистических данных (таблица 3.11) о розничной торговле в Республике Беларусь исследовать зависимость розничного товарооборота от числа объектов розничной торговой сети .
Требуется:
1) С помощью вкладки «Мастер диаграмм» по заданным статистическим данным построить точечный график (корреляционное поле) и произвести визуальный анализ эмпирических данных.
2) Среди экспоненциальной, логарифмической, степенной, полиномиальной и линейной регрессионных парных моделей с помощью инструмента «Линия тренда» выбрать уравнение регрессии, которое наилучшим образом соответствует расположению точек корреляционного поля.
3) По выбранному уравнению определить точечный коэффициент эластичности, предполагая, что число объектов сети равно 42 тысячи.
4) По построенной модели выполнить точечный прогноз розничного товарооборота при прогнозном значении числа объектов розничной торговой сети, равном 44 тысячам.
Таблица 3.11. Статистические данные примера 3.5
| Год | Число объектов розничной торговой сети, тыс. | Розничный товарооборот в фактически действовавших ценах, млрд руб. |
| 30,8 | ||
| 29,7 | ||
| 29,6 | ||
| 31,1 | ||
| 32,8 | ||
| 34,2 | ||
| 35,4 | ||
| 36,1 | ||
| 41,0 | ||
| 43,4 |
Решение:
1) С помощью вкладки «Мастер диаграмм» по заданным статистическим данным построим точечный график (рисунок 3.11). Из вида корреляционного поля можно сделать вывод о том, что между результирующим признаком и фактором существует прямая зависимость, т.е. с ростом числа объектов розничной торговой сети розничный товарооборот увеличивается.
2) С помощью инструмента «Линия тренда» (методика применения этого инструмента описана в главе 6) построим различные выдыуравнений регрессии, указав индекс детерминации.

Рис. 3.11. Корреляционное поле примера 3.5
Уравнение экспоненциальной регрессии отображено на рисунке 3.12. Оно имеет вид  , при этом
, при этом  .
.

Рис. 3.12. Точечный график с экспоненциальным трендом
Уравнение логарифмической регрессии отображено на рисунке 3.13. Оно имеет вид  , при этом
, при этом  .
.
Уравнение степенной регрессии отображено на рисунке 3.14. Оно имеет вид  , при этом
, при этом  .
.
Уравнение полиномиальной регрессии отображено на рисунке 3.15. Оно имеет вид  , при этом
, при этом  .
.
Уравнение линейной регрессии отображено на рисунке 3.16. Оно имеет вид  , при этом
, при этом  .
.

Рис. 3.13. Точечный график с логарифмическим трендом

Рис. 3.14. Точечный график со степенным трендом

Рис. 3.15. Точечный график с полиномиальным трендом

Рис. 3.16. Точечный график с линейным трендом
Сравнение индексов детерминации для всех построенных моделей позволяет сделать вывод о том, что наиболее качественной является полиномиальное уравнение регрессии .
3) Для вычисления точечного коэффициента эластичности воспользуемся формулой  , где
, где  производная функции
производная функции  ,
,  . В нашем случае
. В нашем случае  ,
,  . Значит,
. Значит,  ,
,  ,
,  . Поэтому
. Поэтому  . Следовательно, при изменении на 1% от уровня значение изменится от уровня
. Следовательно, при изменении на 1% от уровня значение изменится от уровня  на 2,1%.
на 2,1%.
4) Для нахождения по выбранному уравнению регрессии точечного прогноза розничного товарооборота при прогнозном значении числа объектов розничной торговой сети  подставим в уравнение значение . Получим значение, равное 57363,8 млрд руб.
подставим в уравнение значение . Получим значение, равное 57363,8 млрд руб.
Реализация с помощью ППП Excel
Расчет и анализ показателей парной линейной регрессии может быть осуществлен с помощью «Пакета анализа» табличного процессора Excel. Основную информацию о линейной модели дает программа «Регрессия». Эта информация содержится в четырех таблицах: «Регрессионная статистика», «Дисперсионный анализ» (две таблицы) и «Вывод остатка».
В таблице «Регрессионная статистика» приводятся значения:
1. Множественный  – линейный коэффициент корреляции
– линейный коэффициент корреляции  .
.
2. -квадрат– коэффициент детерминации  .
.
3. Нормированный – скорректированный с поправкой на число степеней свободы.
4. Стандартная ошибка – стандартная ошибка регрессии  .
.
5. Наблюдения – число наблюдений  .
.
В первой таблице «Дисперсионный анализ» приведены:
1. Столбец df – число степеней свободы, равное:
 для строки Регрессия;
для строки Регрессия;
 для строки Остаток;
для строки Остаток;
для строки Итого.
2. Столбец SS– сумма квадратов отклонений, равная:
 для строки Регрессия;
для строки Регрессия;
 для строки Остаток;
для строки Остаток;
 для строки Итого.
для строки Итого.
3. Столбец MS – дисперсии, определяемые по формуле  :
:
факторная для строки Регрессия;
остаточная для строки Остаток.
4. Столбец F – наблюдаемое значение F-критерия Фишера  .
.
5. Столбец Значимость F – значение уровня значимости, соответствующее вычисленной F-статистике.
Если значимость F меньше заданного уровня значимости  , то статистически значим.
, то статистически значим.
Во второй таблице «Дисперсионный анализ» указаны:
1. Коэффициенты – значения коэффициентов а и b.
2. Стандартная ошибка – стандартные ошибки коэффициентов регрессии а и b.
3. t-статистика – наблюдаемые значения  -статистики
-статистики  для коэффициентов регрессии а и b.
для коэффициентов регрессии а и b.
4. P-Значение – значение уровня значимости, соответствующее вычисленной -статистике.
Если P-значениеменьше заданного уровня значимости , то соответствующий коэффициент регрессиистатистически значим.
5. Нижние 95% и Верхние 95% – нижние и верхние границы 95%-ных доверительных интервалов для коэффициентов уравнения линейной регрессии.
В таблице «Вывод остатка» указаны:
1. Наблюдение – номер наблюдения.
2. Предсказанное – расчетные (теоретические) значения  .
.
3. Остатки – разность  между наблюдаемыми и расчетными значениями зависимой переменной.
между наблюдаемыми и расчетными значениями зависимой переменной.
Методику вычисления ключевых показателей парной линейной регрессии проиллюстрируем на примере следующей задачи (при этом будем опираться на статистические данные, находящиеся в таблице 3.12, и исходить из того, что объем выборки равен 20).
Задача.Для прогноза возможного объема экспорта на основе ВНП построить и исследовать парную линейную регрессионную модель  зависимости объема экспорта (y, усл. ед.) от ВНП (x, усл. ед.) Использовать построенную модель для прогноза при xp=2500.
зависимости объема экспорта (y, усл. ед.) от ВНП (x, усл. ед.) Использовать построенную модель для прогноза при xp=2500.
Требуется:
1) ввести данные;
2) построить корреляционное поле зависимости экспорта от ВНП ;
3) установить тесноту и вид связи между указанными показателями, т.е. рассчитать ковариацию и корреляцию и проанализировать их;
4) найти точечные и интервальные оценки для коэффициентов регрессии a и b;
5) оценить коэффициент детерминации и провести анализ общего качества уравнения регрессии;
6) указать стандартную ошибку регрессии;
7) оценить статистическую значимость коэффициентов регрессии a и b при уровне значимости  , при необходимости получить новое уравнение регрессии со значимыми коэффициентами;
, при необходимости получить новое уравнение регрессии со значимыми коэффициентами;
8) выяснить, выполняются ли условия теоремы Гаусса-Маркова; для этого оценить разброс точек на графике остатков, построить гистограмму остатков, проанализировать их числовые характеристики;
9) дать точечный и интервальный прогнозы объема экспорта по заданному значению ВНП.
Результаты вычислений и анализа оформить в виде отчета (форма отчета прилагается ниже).
Порядок выполнения:
1) В ячейку А1 введите название ВНП, в ячейку В1 – название Экспорт. В ячейки А2, А3, …, А21 введите данные первого столбца выбранного варианта задания, в ячейки В2, В3, …, В21 – данные второго столбца выбранного варианта.
Присвойте листу 1 название «Исходные данные».
2) На листе «Исходные данные» выполните следующие действия:
– на панели инструментов активизируется кнопка Мастер диаграмм (шаг 1 из 4), в одноименном диалоговом окне (рисунок 3.17) среди стандартных типов выбирается Точечная и верхний левый вид диаграммы и нажимается кнопка Далее>;
– открывается диалоговое окно Мастер диаграмм (шаг 2 из 4), в котором во вкладке Диапазон данных в поле Диапазон вводится ссылка на диапазон ячеек A2:В21; нажимается кнопка Далее>;
– открывается диалоговое окно Мастер диаграмм (шаг 3 из 4), в котором во вкладке Заголовки в поле Ось Х(категорий) вводится название «ВНП», в поле Ось Y(значений) – название «Экспорт»; во вкладке Легенда снимается флажок Добавить легенду и нажимается кнопка Далее>;
– открывается диалоговое окно Мастер диаграмм (шаг 4 из 4) в поле имеющемся устанавливается флажок и нажимается кнопка Готово.

Рис. 3.17. Диалоговое окно «Мастер диаграмм (шаг 1 из 4)»
3) В меню Сервис выберите дополнение Анализ данных, в предложенных инструментах анализа выделите Ковариация, нажмите кнопку ОК. Установите значения параметров в появившемся диалоговом окне (рисунок 3.18) следующим образом:

Рис. 3.18. Диалоговое окно «Ковариация»
· Входной интервал – введите ссылки на ячейки А1:В21 (курсор установите в поле «Входной интервал», указатель мыши поместите в ячейку А1, удерживая нажатой левую клавишу, протяните указатель мыши до ячейки В21);
· Группирование – флажок по столбцам устанавливается автоматически;
· Метки в первой строке – установите флажок щелчком левой кнопки мышки;
· Параметры вывода – установите флажок на Новый рабочий лист, поставив курсор в поле напротив, введите название «Ковариация».
Нажмите ОК.
Вернитесь на лист «Исходные данные». В меню Сервис выберите опцию Анализ данных и выделите Корреляция. Установите в диалоговом окне (рисунок 3.19) следующим образом значения параметров:

Рис. 3.19. Диалоговое окно «Корреляция»
· Входной интервал – введите ссылки на ячейки, содержащие исходные данные А1:В21 (курсор установите в поле «Входной интервал», указатель мыши поместите в ячейку А1, удерживая нажатой левую клавишу, протяните указатель мыши до ячейки В21);
· Группирование – установите флажок по столбцам;
· Метки в первой строке – установите флажок;
· Параметры вывода – установите флажок на Новый рабочий лист, введите название «Корреляция».
Нажмите ОК.
Значение линейного коэффициента корреляции находится на листе «Корреляция» в ячейке В3.
4) Вернитесь на лист «Исходные данные». В меню Сервис выберите дополнение Анализ данных укажите Регрессия. Нажмите кнопку ОК. Установите в диалоговом окне (рисунок 3.20) следующим образом значения параметров:
· Входной интервал Y – введите ссылки на ячейки В1:В21;
· Входной интервал X – введите ссылки на ячейки А1:А21;
· Метки – установите флажок;
· Уровень надежности – установите флажок;
· Константа ноль – не активизируйте;
· Параметры вывода – установите флажок на Новый рабочий лист и в поле напротив введите имя «Регрессия»;
· Остатки – установите флажок;
· Стандартизованные остатки – оставьте пустым;
· График остатков – установите флажок;
· График подбора – установите флажок;
· График нормальной вероятности – оставьте пустым.
Нажмите ОК.

Рис. 3.20. Диалоговое окно «Регрессия»
Расположите диаграммы рядом (на поле диаграммы нажмите левую кнопку мыши, затем поместите курсор на белое поле и при нажатой левой кнопке передвигайте диаграмму вниз) и растяните их (на поле диаграммы нажмите левую кнопку мыши, нижнюю линию границы диаграммы при нажатой левой клавише протяните вниз).
Точечные оценки коэффициентов регрессии a и b находятся на листе «Регрессия» в ячейках В17 и В18 соответственно. Нижняя и верхняя границы доверительного интервала вычислены на листе «Регрессия» в ячейках F17 и G17 для коэффициента a и в ячейках F18 и G18 для коэффициента b.
5) Значение коэффициента детерминации находится на листе «Регрессия» в ячейке В5. Наблюдаемое значение F-критерия Фишера
находится на листе «Регрессия» в ячейке E12.
Вычислите критическое значение Fкрв свободной ячейке E15 следующим образом:
– нажмите на fx (вставка функций);
– в поле Категория окна Мастер функций выберите статистические, из предложенных ниже функций выделите FРАСПОБР и нажмите ОК.
Откроется окно Аргументы функций. Заполните поля так:
· Вероятность – наберите значение 0,05;
· Степени свободы 1 – установите курсор в поле и выделите ячейку В12 столбца df таблицы «Дисперсионный анализ»;
· Степени свободы 2 – установите курсор в поле и выделите ячейку В13 столбца df таблицы «Дисперсионный анализ».
Нажмите ОК.
6) Значение стандартной ошибки регрессии находятся на листе «Регрессия» в ячейке В7.
7) Наблюдаемые значения -статистики коэффициентов регрессии a и b находятся на листе «Регрессия» в ячейках D17 и D18 соответственно.
Вычислите критическое значение tкр в свободной ячейке D19 следующим образом:
– нажмите на fx (вставка функций);
– в поле «Категория» окна Мастер функций выберите статистические, из предложенных ниже функций выделите СТЬЮДРАСПОБР и нажмите ОК. Откроется окно «Аргументы функций». Заполните поля:
· Вероятность – наберите значение 0,05;
· Степени свободы – введите 20–1–1, где 20 – число наблюдений, 1 – число факторов (x) в уравнении регрессии, 1 – число свободных членов ( ) в уравнении регрессии.
Нажмите ОК.
8) На листе регрессия в меню Сервис выберите Анализ данных, укажите Гистограмма. Нажмите кнопку ОК. Значения параметров в появившемся диалоговом окне (рисунок 3.21) установите следующим образом:
· Входной интервал – введите ссылки на ячейки С24:С44 (столбец Остатки с названием);
· Интервал карманов – не заполняйте;
· Метки – установите флажок;
· Выходной диапазон – введите ссылку на новый рабочий лист «Гистограмма»;
· Парето – оставьте пустым;
· Интегральный процент – оставьте пустым;
· Вывод графика – установите флажок.
Нажмите ОК. Растяните диаграмму вниз.

Рис. 3.21. Диалоговое окно «Гистограмма»
Вернитесь на лист «Регрессия». Выберите в опциях меню Сервис → Анализ данных → Описательная статистика, нажмите ОК. Значения параметров в диалоговом окне (рисунок 3.22) установите следующим образом:

Рис. 3.22. Диалоговое окно «Описательная статистика»
· Входной интервал – введите ссылки на ячейки С24:С44 (столбец Остатки с названием);
· Группирование – установите флажок по столбцам;
· Метки – установите флажок в первой строке;
· Выходной диапазон – установите флажок на Новый рабочий лист и в поле напротив введите название «Статистика остатков»;
· установите флажки Итоговая статистика, уровень надежности (95%).
Нажмите ОК.
9) Вернитесь на лист «Регрессия» и в пустой ячейке E22 листа введите формулу
= В17+В18*2500 – точечный прогноз.
На листе «Регрессия» в пустой ячейке E23 вычислите значение по формуле , где – стандартная ошибка регрессии.
В пустых ячейках E24 и F24 введите формулы
=E22–D19*E23 – левый конец интервала прогноза;
=E22+D19*E23 – правый