Коэффициенты, основанные на модальном прогнозе
Формализуем понятие прогноза следующим образом. Выбирая произвольный объект и зная распределение рассматриваемого признака (условное или безусловное), считаем, что для выбранного объекта этот признак принимает то значение, которое имеет максимальную вероятность, встречается с максимальной частотой (т.е. модальное значение). Такой прогноз называется модальным. Чтобы стал ясен содержательный смысл рассматриваемого прогноза, приведем формулы соответствующих коэффициентов. Но сначала отметим, что таких коэффициентов три: два отражают возможные направленные связи, а третий является их усреднением. Эти коэффициенты обычно обозначаются буквами l с индексами: lr – отражающий “влияние” строкового признака на столбцовый; lс – отражающий "влияние" столбцового признака на строковый, l – усредненный коэффициент.
Рассмотрим формулу для lr, (для lс рассуждения совершенно аналогичны). Будем использовать те же обозначения, которые были задействованы выше.
 (2)
(2)
Выражение  означает наибольшую частоту в i - й строке.
означает наибольшую частоту в i - й строке.
Выражение 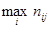 – наибольшую столбцовую маргинальную частоту.
– наибольшую столбцовую маргинальную частоту.
Поясним смысл формулы (2) на примере. Пусть частотная таблица имеет вид:
Таблица 13.
Пример частотной таблицы, использованный для расчета коэффициента lr
| X | Y | Итого | ||
| Итого |
Наибольшая частота в первой строке матрицы равна 30, во второй – тоже 30, в третьей – 40. Максимальный маргинал по столбцам – 65. Общее количество объектов в выборе – 150. Значит, имеет место равенство:

Рассмотрим безусловное распределение признака Y. Отвечающие ему частоты – это маргиналы по столбцам рассматриваемой матрицы: 45, 40, 65. Модальная частота – 65. Значит, выбрав случайным образом какой-либо объект, мы, прогнозируя для него значение Y, в соответствии с нашими представлениями о прогнозе, должны сказать, что упомянутое значение равно 3 (именно это значение является модой). Ясно, что, поступая так и перебирая последовательно всех респондентов, мы дадим правильный прогноз в 65 случаях и ошибемся в (150 - 65) случаях (заметим, что доля (вероятность) ошибки будет равна 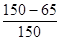 . Именно эта разность стоит в знаменателе нашей формулы.
. Именно эта разность стоит в знаменателе нашей формулы.
Итак, для безусловного распределения качество нашего прогноза можно оценить с помощью величины (150 - 65). Улучшится ли прогноз при переходе к условным распределениям того же признака? Попытаемся ответить на этот вопрос.
Пусть Х = 1. Соответствующее условное распределение Y определяется частотами первой строки нашей матрицы: числами 0, 20, 30. Значит, перебирая 50 респондентов с первым значением Х, и делая для каждого прогноз в соответствии с нашими правилами, мы не ошибемся в 30 случаях. При Х = 2 количество верных предположений тоже будет равно 30. При Х=3 – 40. Общее количество правильных прогнозов во всех условных распределениях будет равно (30+30+40). По сравнению с “безусловным” случаем оно возрастет на ((30+30+40) - 65) единиц. А это – числитель выражения для lr.
Итак, в числителе формулы (2) отражена величина того суммарного прироста количества правильных прогнозов, который возникает за счет перехода от перебора объектов, “сваленных в одну кучу” (“куча” отвечает безусловному распределению), к перебору последовательно по “слоям” (отвечающим условным распределениям). Эта величина отражает суть коэффициента. Знаменатель же формулы (2) использован для нормировки (знаменатель равен значению числителя, получающемуся, когда суммарный прогноз прогноз по условным распределениям будет стопроцентным). Потребность в таковой возникает в силу тех же причин, которые были обсуждены нами при рассмотрении критерия “хи-квадрат”: без нормировки величина коэффициента будет зависеть от размера выборки, значений конкретных частот и т.д.
Теперь, чтобы закончить вопрос о том, как в рассматриваемом случае формализуются естественные представления о связи, необходимо затронуть проблему “усреднения” всевозможных связей типа “альтернатива-альтернатива”. Способ усреднения очевиден. Он как бы двуступенчат. Рассматривая какое-либо из наших условных распределений, мы говорим о прогнозе, учитывая сразу все возможные значения Y, не анализируя отдельно, насколько зафиксированное значение Х может быть связано с тем или иным значением Y (в п. 2.3.2.3 мы увидим, как такая связь может быть прослежена).
Переходя к общей формуле, мы суммируем показатели качества прогноза для всех условных распределений, игнорируя то, что для одного значения Х этот прогноз может быть хорошим, а для другого – плохим.
В заключение обсуждения вопроса о lr опишем некоторые его свойства.
Имеют место неравенства: 0 £ lr£ 1. Коэффициент приближается к 1 по мере того, как в каждой строке объекты все более концентрируются в одной клетке, т.е. прогноз значения Y для условных распределений становится все лучше. Нетрудно проверить, что lr = 1, если
 ,
,
и что это, в свою очередь, может быть верным лишь в случае, когда в каждой строке частотной таблицы существует только одна отличная от нуля частота, т.е. когда по значению признака Х мы можем однозначно судить о значении признака Y (но не обратно!).Чем ближе значение lr к 1, тем лучше такое предсказание и сильнее связь (в рассматриваемом понимании) между переменными.
lr = 0, если максимальные частоты в строках приходятся на один и тот же столбец. Это имеет место даже в том случае, если все остальные элменты частотной таблицы близки к нулю, т.е. если фактически имеется “хорошая” связь (а отнюдь не отсутствие связи, как это должно было бы быть для нулевого значения хорошего коэффициента связи). И это является существенным недостатком рассматриваемого коэффициента.
Как мы уже отмечали, все приведенные рассуждения справедливы и для коэффициента l, служащего показателем связи, если зависимая и независимая переменные меняются местами, и вычисляющегося по формуле:

Для измерения по тому же принципу ненаправленной связи показатели рассматриваемых направленных связей усредняются. Это делается разными способами. Самый простой:

Итак, подведем итог обсуждению рассмотренных коэффициентов. Правила их построения определяют отвечающее модальному классу значение зависимого признака (Y) как оценку этого значения для произвольно взятого объекта. Если оценка делается без знания значения независимого признака (Х), то значением, предсказываемым для всех объектов, является модальное значение безусловного распределения зависимого. Если же оценка делается на основе знания значения Х, то прогноз осуществляется отдельно для объектов, обладающих этим значением, на основе выявления моды соответствующего условного распределения Y. Величина lr (lc) говорит об уменьшении (за счет осуществения перехода от безусловного распределения к набору условных) ошибки осуществленного с единичной вероятностью предсказания о том, что объект обладает модальным значением Y.
Приведем несколько утрированный пример. Рассмотрим, как может измеряться связь между национальностью (Х) и цветом волос (Y). Предположим, что Вы являетесь продавцом косметики и Вам для того, чтобы заранее подготовиться к общению с покупателем, желательно заранее знать цвет его волос. Представим себе, что вы арендовали помещение в вузе и к вам в комнату по очереди (в случайном порядке) входят за покупкой студенты. Допустим также, что Вы знаете безусловное распределение всех студентов рассматриваемого вуза по цвету волос, и в соответствии с этим распределением количество блондинов, брюнетов и шатенов примерно одинаково, но шатенов несколько больше, чем остальных. Вы пользуетесь правилом: перед входом покупателя приготавливаете товар, рассчитанный на модальное значение признака “цвет волос” (в нашем случае – на шатенов).
Теперь представим себе две ситуации.
В первой Вы ничего не знаете о национальности входящего к вам студента. Наверное, в таком случае, приготовив товар для шатенов, Вы в почти двух третях возможных случаев совершите ошибку: к Вам с одинаково вероятностью в любой момент может войти и блондин, и брюнет, и шатен. Торговля заведомо будет неэффективной.
А во второй ситуации Вы сумели организовать дело так, что сначала к Вам по очереди (снова в случайном порядке) входят учащиеся в вузе китайцы, затем - финны, потом - русские. Очевидно, эффективность Вашей торговли возрастет: зная, что сегодня к Вам придут китайцы, Вы готовите товар, рассчитанный только на брюнетов, если придут финны - на блондинов, если русские - на шатенов. Конечно, Вы и тут будете ошибаться, но уже в гораздо меньшей степени, чем раньше. Другими словами, Ваш прогноз улучшится. А это и означает наличие связи между национальностью и цветом волос. Чем в большей мере прогноз улучшился, тем сильнее связь.
Описанный прогноз называют модальным, или оптимальным. Коэффициенты чаще всего называют коэффициентами Гуттмана [Интерпретация и анализ ..., 1987; Статистические методы ..., 1979], Гудмена [Паниотто, Максименко, 1982] или l-коэффициентами [Рабочая книга, 1983].