Определение объема вероятностной выборки
Объем вероятностной выборки определяется по специальным формулам, в зависимости от заданной достоверности, точности исследования и дисперсии генеральной совокупности.
Теоретической основой возможности использования выборочного обследования для оценки характеристик генеральной совокупности является центральная предельная теорема.
Центральная предельная теорема гласит: для простых случайных выборок объемом n, выделенных из генеральной совокупности с истинным средним μ и дисперсией σ2, для больших n распределение выборочных средних 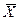 приближается к нормальному с центром, равным истинному среднему, и дисперсией, равной отношению дисперсии генеральной совокупности к объему выборки, то есть:
приближается к нормальному с центром, равным истинному среднему, и дисперсией, равной отношению дисперсии генеральной совокупности к объему выборки, то есть:
 .
.
Теорема верна для любого распределения частот в генеральной совокупности, однако чем ближе распределение в генеральной совокупности к нормальному, тем меньший объем выборки необходим для достижения эквивалентной достоверности и точности исследования.
На практике исследователь формирует только одну выборку из генеральной совокупности и ему необходимо знать, какой должен быть объем выборки для соблюдения заданных параметров достоверности и точности. Формула для определения объема выборки при оценке среднего может быть выведена, исходя из положений центральной предельной теоремы, и имеет вид:
 ,
,
где
n - необходимый объем выборки;
z - количество интервалов, характеризующих требование к достоверности исследования;
H - требуемая величина точности исследования;
σ2 - дисперсия генеральной совокупности.
Рассмотрим подробнее параметры правой части уравнения.
Достоверность характеризует вероятность того, что конкретная случайная выборка адекватно отражает характеристику генеральной совокупности.
Достоверность 99% означает, что в 99 выборках из 100 средняя генеральной совокупности будет входить в интервал средней, полученной в результате выборочного исследования.
Пример. Например, проведено три независимых выборочных исследования уровня доходов населения в конкретном регионе. Получены следующие данные о среднем уровне дохода: 300  10 грн., 310 10 грн., 305 10 грн., истинное среднее значение равно 302 грн.
10 грн., 310 10 грн., 305 10 грн., истинное среднее значение равно 302 грн.
Как видим, истинное среднее значение входит во все три интервала.
При достоверности 99% и заданной точности 10 грн. в 99 выборках из ста среднее выборки будет находиться в интервале от 292 до 312 грн. В одном случае из ста мы получим результат либо ниже 292 грн., либо больше 312 грн. Результаты такого исследования будут недостоверны, т.к. среднее генеральной совокупности не будет входить в коридор полученной в результате выборочного исследования средней величины.
В представленной формуле достоверность характеризуется величиной z, которая определяется по таблице z-распределения в зависимости от заданной достоверности в процентах.
Приведем соответствие только для некоторых типичных вероятностей: 68,26% (z=1), 95,45% (z=2), 99,73% (z=3).
z-распределение – Стандартное нормальное (Z) распределение
Значение z (z value) – количество стандартных ошибок, на которое точка удалена от среднего значения.
Вместо таблицы для вычисления вероятности попадания случайной величины в отмеченный (заштрихованный) диапазон

можно воспользоваться следующей формулой EXCEL:
=2*НОРМСТРАСП(z)-1
подставив в нее требуемое значение z. Например:
| z | Формула | Результат |
| =2*НОРМСТРАСП(1)-1 | 0,6827 | |
| =2*НОРМСТРАСП(2)-1 | 0,9545 | |
| =2*НОРМСТРАСП(3)-1 | 0,9973 |
Точность определяется исследователем, исходя из конкретной поставленной задачи.
Если исследуемая величина является абсолютной, то и точность должна быть представлена абсолютной, а не относительной величиной. При определении процентов (долей) точность определяется в процентах.
При определении точности исследователь должен учитывать возможное исследование динамики показателя.
Пример. Например, если при точности 10 грн. результаты исследования в прошлом году определили средний доход в 300 грн., а в текущем 305 грн., делать выводы об увеличении дохода некорректно, т.к. величина изменения входит в заданный интервал точности (менее 10 грн.).
Наиболее сложным при расчете объема выборки является определение дисперсии. При оценке среднего возникают два основных случая:
1) дисперсия генеральной совокупности известна на основании предыдущих исследований;
2) дисперсия генеральной совокупности неизвестна.
Возможность использования дисперсии, полученной в результате предыдущих исследований, основана на том, что этот параметр генеральной совокупности более инерционен, чем среднее. Другими словами, он изменяется медленнее и, следовательно, если вы, к примеру, ежегодно изучаете уровень дохода населения, то можете использовать величину дисперсии, полученную в прошлогодних исследованиях.
Пример расчета объема выборки.
Во-первых, на объем выборки влияет уровень доверительности α, по которому при помощи специальной таблицы определяется нормированное отклонение z. Например, для случая α = 99% по таблице найдем z = 2,58.
Во-вторых, оказывает влияние уровень (коэффициент) вариации. Примем, например, коэффициент вариации равным  = 50%.
= 50%.
В-третьих, на объем выборки влияет требуемая точность (допустимая ошибка).
Иногда точность определена в относительных, а не абсолютных показателях. Другими словами, может быть известно, что результат вычисления должен составить плюс-минус R% от среднего. Это означает, что H = R·μ, где μ – среднее совокупности.
Примем допустимую ошибку равной R = 6%.
Тогда с учетом того, что коэффициент вариации  , объем выборки составит:
, объем выборки составит:
=  =
=  = 462,25 ≈ 463 (округлено в большую сторону до ближайшего целого числа).
= 462,25 ≈ 463 (округлено в большую сторону до ближайшего целого числа).
Если об уровне генеральной Вам ничего неизвестно, то для оценки уровня дисперсии возможно применение правила трех сигм. При нормальном распределении 99% параметров характеристики должно находиться в интервале плюс-минус три сигмы от истинной средней. Проводя исследование, Вы должны оценить типичный верхний (b) и нижний (a) уровни параметра, интервал между которыми и составляет шесть сигм. Величина сигмы составит разницу уровней параметра деленную на 6.
Дисперсия  или вариация var:
или вариация var:
 ,
,
где b, a – соответственно верхнее и нижнее значение параметра.
Сигма – это среднеквадратическое отклонение (стандартное отклонение):
 .
.
Пример. Например, при исследовании уровня дохода нижнее значение параметра принимается на уровне 0 грн., а верхнее, предположим, на уровне 6000 грн. В этом случае значение среднеквадратичного (стандартного) отклонения составит: (6000-0)/6=1000.
Следует заметить, что если исследователь действительно готов к проведению исследования, то определение типичных нижней и верхней границы параметра не представляют особой сложности.
При работе с маркетинговыми шкалами принимаемая величина дисперсии зависит от количества точек шкалы и типа распределения частот.
Наихудшим в маркетинговых исследованиях (соответствующей максимальной дисперсии) считается равномерное распределение ответов между точками шкалы. Наилучшим – нормальное с максимальной частотой ответов в середине шкалы.
Таблица 5.1. Типовые диапазоны дисперсий в зависимости от количества точек шкалы
| Количество точек шкалы | Диапазоны дисперсий |
| 0,7-1,3 1,2-2,0 2,0-3,0 2,5-4,0 3,0-7,0 |
Нижние уровни диапазона соответствуют нормальному распределению частот, верхние – равномерному.
Рассмотренная выше формула определения объема выборки применяется при оценке средних величин.
Если исследователь работает с процентами или долями, то формула трансформируется в следующий вид:
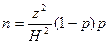 ,
,
где р - доля людей, положительно или отрицательно отвечающих на поставленный вопрос.
При работе с процентами в формулу вместо единицы подставляется 100.
Очевидно, что максимальное значение множителя (1-р)р имеет место при одинаковой доле положительных и отрицательных ответов и составляет при работе с долями 0,25, а при работе с процентами – 2500. Однако результат при работе с долями или процентами будет эквивалентен, так как численное значение квадрата точности, стоящее в знаменателе, также будет отличаться в 10000 раз.
Задача. При исследовании доли домохозяйств, которые имеют автомобили, заранее эта доля была оценена в 20%. Какой объем выборки необходим для обеспечения достоверности исследования на уровне 95% и точности 1%?
Решение. Дисперсия составит:  = (100-20)*20=1600. При заданной достоверности исследования 95% величина z ≈ 2. Тогда объем выборки:
= (100-20)*20=1600. При заданной достоверности исследования 95% величина z ≈ 2. Тогда объем выборки:
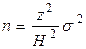 =
=  =
=  =6400.
=6400.
Малхотра, С.449:
Объем генеральной совокупности N не влияет на объем выборки напрямую, за исключением случаев, когда применяется коэффициент окончательной коррекции совокупности. Возможно, это кажется невероятным, но если подумать, в этом утверждении есть смысл. Например, если исследуемые характеристики всех элементов совокупности идентичны, то выборки, состоящей из одного элемента, вполне достаточно, чтобы рассчитать среднее. Это также правильно, если совокупность состоит из 50, 500, 5000 или 50000 элементов.
В то же время изменчивость характеристик совокупности напрямую влияет на объем выборки. Эта изменчивость учитывается при вычислении объема выборки с помощью дисперсии совокупности σ2 или дисперсии выборки s2.
Пример (Н.Б.Сафронова, И.Е.Корнеева). Проведем расчет выборки для маркетингового исследования, посвященного узнаваемости потребителями торговой марки. Значение вероятности P = 0,954, предельно допустимая ошибка данного исследования не должна превышать 5%. Какое количество респондентов необходимо опросить для решения этой проблемы в порядке случайной повторной выборки притом, что данные о распределении признаков отсутствуют?
Решение. Так как доля признака неизвестна, допустим, что 50% потребителей знают торговую марку, а 50% – нет. Используем формулу расчета выборки с учетом доли признака:
 =
=  =400 чел.
=400 чел.
Более сложные методы расчета объема выборки необходимы при использовании в процессе анализа двойной или тройной табуляции. Это связано с тем, что достоверность и точность, достигаемая при рассчитанном объеме выборки, для выборки в целом, не достигается для отдельных ее частей, на которые разбивается выборка в процессе табуляции.
Пример. Например, при определении среднего уровня дохода населения определенный объем выборки может быть достаточен, но он недостаточен для определения среднего уровня дохода мужчин и женщин (при заданных точности и достоверности). Это легко понять, потому что количество мужчин и женщин, принявших участие в опросе отдельно, меньше количества всех респондентов. Зная, однако, соотношение мужчин и женщин, легко определить, с какой точностью рассчитан уровень среднего дохода для каждой из рассматриваемых групп.