Технологии Data Mining
В настоящее время элементы искусственного интеллекта активно внедряются в практическую деятельность менеджера. В отличие от традиционных систем искусственного интеллекта, технология интеллектуального поиска и анализа данных или "добыча данных" (Data Mining - DM), не пытается моделировать естественный интеллект, а усиливает его возможности мощностью современных вычислительных серверов, поисковых систем и хранилищ данных. Нередко рядом со словами "Data Mining" встречаются слова "обнаружение знаний в базах данных" (Knowledge Discovery in Databases).

Рис. 6.17.
Data Mining - это процесс обнаружения в сырых данных ранее неизвестных, нетривиальных, практически полезных и доступных интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности. Data Mining представляют большую ценность для руководителей и аналитиков в их повседневной деятельности. Деловые люди осознали, что с помощью методов Data Mining они могут получить ощутимые преимущества в конкурентной борьбе.
В основу современной технологии Data Mining (Discovery-driven Data Mining) положена концепция шаблонов (Patterns), отражающих фрагменты многоаспектных взаимоотношений в данных. Эти шаблоны представляют собой закономерности, свойственные выборкам данных, которые могут быть компактно выражены в понятной человеку форме. Поиск шаблонов производится методами, не ограниченными рамками априорных предположений о структуре выборки и виде распределений значений анализируемых показателей. На рис. 6.17 показана схема преобразования данных с использованием технологии Data Mining.

Рис. 6.18.
Основой для всевозможных систем прогнозирования служит историческая информация, хранящаяся в БД в виде временных рядов. Если удается построить шаблоны, адекватно отражающие динамику поведения целевых показателей, есть вероятность, что с их помощью можно предсказать и поведение системы в будущем. На рис. 6.18 показан полный цикл применения технологии Data Mining.
Важное положение Data Mining - нетривиальность разыскиваемых шаблонов. Это означает, что найденные шаблоны должны отражать неочевидные, неожиданные (Unexpected) регулярности в данных, составляющие так называемые скрытые знания (Hidden Knowledge). К деловым людям пришло понимание, что "сырые" данные (Raw Data) содержат глубинный пласт знаний, и при грамотной его раскопке могут быть обнаружены настоящие самородки, которые можно использовать в конкурентной борьбе.
Сфера применения Data Mining ничем не ограничена - технологию можно применять всюду, где имеются огромные количества каких-либо "сырых" данных!
В первую очередь методы Data Mining заинтересовали коммерческие предприятия, развертывающие проекты на основе информационных хранилищ данных (Data Warehousing). Опыт многих таких предприятий показывает, что отдача от использования Data Mining может достигать 1000%. Известны сообщения об экономическом эффекте, в 10-70 раз превысившем первоначальные затраты от 350 до 750 тыс. долларов. Есть сведения о проекте в 20 млн долларов, который окупился всего за 4 месяца. Другой пример - годовая экономия 700 тыс. долларов за счет внедрения Data Mining в одной из сетей универсамов в Великобритании.
Компания Microsoft официально объявила об усилении своей активности в области Data Mining. Специальная исследовательская группа Microsoft, возглавляемая Усамой Файядом, и шесть приглашенных партнеров (компании Angoss, Datasage, Epiphany, SAS, Silicon Graphics, SPSS) готовят совместный проект по разработке стандарта обмена данными и средств для интеграции инструментов Data Mining с базами и хранилищами данных.
Data Mining является мультидисциплинарной областью, возникшей и развивающейся на базе достижений прикладной статистики, распознавания образов, методов искусственного интеллекта, теории баз данных и др. (рис. 6.19). Отсюда обилие методов и алгоритмов, реализованных в различных действующих системах Data Mining. [Дюк В.А. www.inftech.webservis.ru/it/datamining/ar2.html]. Многие из таких систем интегрируют в себе сразу несколько подходов. Тем не менее, как правило, в каждой системе имеется какая-то ключевая компонента, на которую делается главная ставка.
Можно назвать пять стандартных типов закономерностей, выявляемых с помощью методов Data Mining: ассоциация, последовательность, классификация, кластеризация и прогнозирование.
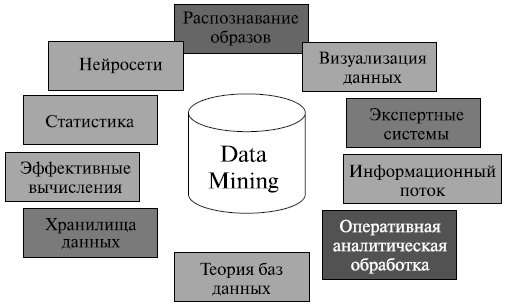
Рис. 6.19. Области применения технологии Data Mining
Ассоциация имеет место в том случае, если несколько событий связаны друг с другом. Например, исследование, проведенное в компьютерном супермаркете, может показать, что 55% купивших компьютер берут также и принтер или сканер, а при наличии скидки за такой комплект принтер приобретают в 80% случаев. Располагая сведениями о подобной ассоциации, менеджерам легко оценить, насколько действенна предоставляемая скидка.
Если существует цепочка связанных во времени событий, то говорят о последовательности. Так, например, после покупки дома в 45% случаев в течение месяца приобретается и новая кухонная плита, а в пределах двух недель 60% новоселов обзаводятся холодильником.
С помощью классификации выявляются признаки, характеризующие группу, к которой принадлежит тот или иной объект. Это делается посредством анализа уже классифицированных объектов и формулирования некоторого набора правил.
Кластеризация отличается от классификации тем, что сами группы заранее не заданы. С помощью кластеризации средства Data Mining самостоятельно выделяют различные однородные группы данных.