Модели представления данных в СУБД
Системы управления базами данных (СУБД)
Для хранения и обработки данных можно использовать различные компьютерные программные средства, например рассмотренную выше программу Excel. Однако по мере усложнения задач хранения и обработки данных, увеличения объемов хранимой и обрабатываемой информации стали разрабатываться специальные программные средства. Вначале в качестве программных средств для разработки баз данных использовались программы общего назначения, такие как паскаль, бейсик, фортран и другие. Но постепенно, по мере роста востребованности такого рода программного обеспечения стали создаваться специальные инструментальны для разработки и работы с данными. Такие специализированные программы получили название системы управления базами данных (СУБД).
История развития СУБД насчитывает более 40 лет. В 1968 году была введена в эксплуатацию первая промышленная СУБД система IMS фирмы IBM. В 1975 году появился первый стандарт ассоциации по языкам систем обработки данных — Conference of Data System Languages (CODASYL), который определил ряд фундаментальных понятий в теории систем баз данных, которые и до сих пор являются основополагающими для сетевой модели данных. В дальнейшее развитие теории баз данных большой вклад был сделан американским математиком Э. Ф. Коддом, который является создателем реляционной модели данных.
Первый этап развития СУБД связан с организацией баз данных на больших машинах типа IBM 360/370, ЕС-ЭВМ и мини-ЭВМ типа PDP11 (фирмы Digital Equipment Corporation — DEC), разных моделях HP (фирмы HewlettPackard). Базы данных хранились во внешней памяти центральной ЭВМ, пользователями этих баз данных были задачи, запускаемые в основном в пакетном режиме. Интерактивный режим доступа обеспечивался с помощью консольных терминалов, которые не обладали собственными вычислительными ресурсами (процессором, внешней памятью) и служили только устройствами ввода-вывода для центральной ЭВМ. Программы доступа к БД писались на различных языках и запускались как обычные числовые программы. Мощные операционные системы обеспечивали возможность условно параллельного выполнения всего множества задач. Эти системы можно было отнести к системам распределенного доступа, потому что база данных была централизованной, хранилась на устройствах внешней памяти одной центральной ЭВМ, а доступ к ней поддерживался от многих пользователей-задач.
Появление персональных компьютеров произвело настоящую революцию в создании систем управления данными. Постоянное снижение цен на персональные компьютеры сделало их доступными не только для организаций и фирм, но и для отдельных пользователей. Компьютеры стали инструментом для ведения документации и собственных учетных функций. Это все сыграло как положительную, так и отрицательную роль в области развития баз данных. Кажущаяся простота и доступность персональных компьютеров и их программного обеспечения породила множество дилетантов. Эти разработчики, считая себя знатоками, стали проектировать недолговечные базы данных, которые не учитывали многих особенностей объектов реального мира. Много было создано систем-однодневок, которые не отвечали законам развития и взаимосвязи реальных объектов. Однако доступность персональных компьютеров заставила пользователей из многих областей знаний, которые ранее не применяли вычислительную технику в своей деятельности, обратиться к ним. И спрос на развитые удобные программы обработки данных заставлял поставщиков программного обеспечения поставлять все новые системы, которые принято называть настольными (desktop) СУБД. Значительная конкуренция среди поставщиков заставляла совершенствовать эти системы, предлагая новые возможности, улучшая интерфейс и быстродействие систем, снижая их стоимость. Наличие на рынке большого числа СУБД, выполняющих сходные функции, потребовало разработки методов экспорта-импорта данных для этих систем и открытия форматов хранения данных.
На сегодняшний день на рынке программного обеспечения имеются десятки разнообразных СУБД (сноска 2). Все крупные компании, разрабатывающие программное обеспечение, как правило, имеют в своем активе одну или несколько СУБД. В качестве примера можно назвать такие распространенные системы как Paradox, dBase, Clipper,Access, Clarion, Oracle, FoxPro, SQL и целый ряд аналогичных продуктов.
Современные СУБД как правило многопользовательские и предназначены для работы в локальной сети. По технологии обработки данных БД подразделяют на централизованные и распределенные.
Централизованная БД хранится в памяти одной вычислительной системы. Такой способ часто применяют в локальных сетях.
Распределенная БД состоит из нескольких, возможно пересекающихся или дублирующих друг друга частей, хранимых на разных ЭВМ. Работа с такой БД осуществляется с помощью системы управления распределенной БД.
По способу доступа к данным БД разделяются на БД с локальным доступом и БД с удаленным (сетевым) доступом.
Системы централизованных БД с сетевым доступом предполагают различные архитектуры подобных систем:
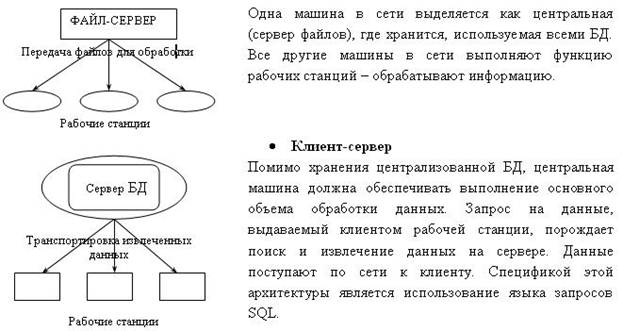 • Легко и удобно работать с большими объемами информации
• Легко и удобно работать с большими объемами информации
• осуществлять быстрый поиск и сортировку данных
• представлять данные в различных видах
• Вносить изменения в данные, добавлять, удалять записи, менять структуру базы
• обмениваться информацией с другими базами
• выводить на принтер или другие носители информацию из БД
• оформление почтовой корреспонденции, получение готовых форм различной отчетной документации
Прежде всего попробуем разобраться, что такое модель и какие модели используются в системах управления базами данных?
Модель - это некоторое упрощенное подобие реального объекта, которое в определенных условиях может его заменить. Модели по своей природе могут быть самые разные, например физические модели, математические, информационные. Примером физической модели может служить модель автомобиля или здания. Математические формулы, описывающие поведение некоторых реальных объектов являются математическими моделями этих объектов. Нас же прежде всего будут интересовать информационные модели.
Информационная модель - это информация (знания, сведения) о реальном объекте, процессе, явлении. Или другое определение: Информационная модель - это набор величин, содержащих всю необходимую информацию об исследуемых объектах (процессах, явлениях).
В любой базе данных данные должны быть определенным образом структурированы. Т.е. должна существовать информационная модель, определяющая порядок организации данных в базе. На сегодня наибольшее распространение получили три модели организации данных: иерархическая, сетевая, реляционная.
Сначала стали использовать иерархические модели. Такая модель может быть представлена направленным графом. Иерархическая модель данных строится по принципу иерархии типов объектов, то есть один тип объектов является главным, а остальные, находящиеся на низших уровнях иерархии подчинёнными.

Рисунок 1.3 - Иерархическая модель организации данных
Между главным и подчинёнными объектами устанавливается взаимосвязь «один ко многим». Для каждого подчинённого типа объекта может быть только один исходный. Наивысший в иерархии узел называется корневым. Иерархическая модель позволяет строить базы данных с иерархической древовидной структурой. Например, на рисунке 1.4 объект "Организация" - предок для объектов "Отделы" и "Филиалы".
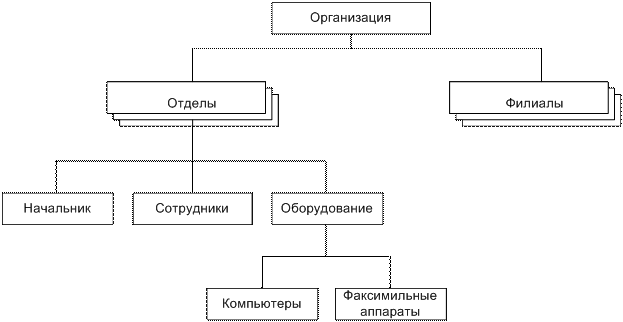
Рисунок 1.4 - Пример иерархической древовидной структуры БД
Основное достоинство иерархической модели - простота описания иерархических структур реального мира.
В сетевой модели данных понятие главного и подчинённых объектов несколько расширены. Любой объект может быть и главным и подчинённым. В сетевой модели главный объект обозначается термином «член набора». Один и тот же объект может одновременно выступать и в роли владельца, и роли члена набора. Это означает, что любой объект может участвовать в любом числе взаимосвязей.

Рисунок 1.5 - Сетевая модель представления данных
При разработке сетевых моделей было выдумано множество "маленьких хитростей", позволяющих увеличить производительность СУБД, но существенно усложнивших последние. Прикладной программист должен знать массу терминов, изучить несколько внутренних языков СУБД, детально представлять логическую структуру базы данных для осуществления навигации среди различных экземпляров, наборов, записей и т.п. Один из разработчиков операционной системы UNIX сказал "Сетевая база – это самый верный способ потерять данные".
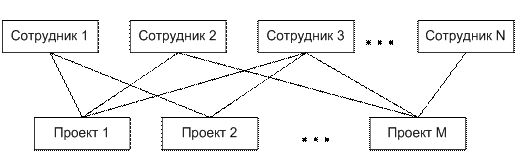
Рисунок 1.6 – Пример сетевой структуры
В настоящее время наибольшее распространение получили реляционные базы данных. СУБД реляционного типа являются наиболее распространенными на всех классах ЭВМ, а на ПК занимают доминирующее положение.
Реляционной называется СУБД, в которой средства управления БД поддерживают реляционную модель данных. Концепция реляционной модели была предложена в 1970 Г. Е. Коддом и имеет большое значение в деле организации работы с БД.
В реляционной модели данных объекты и взаимосвязи между ними представляются с помощью таблиц. Каждая из таблиц представляет собой один объект и состоит из строк и столбцов. В реляционной базе данных каждая таблица должна иметь первичный ключ (ключевой элемент) – поле или комбинацию полей, которые единственным образом идентифицируют каждую строку в таблице. За счёт ключевых полей имеется возможность установить связи между таблицами. В целом вся БД представляет собой набор взаимосвязанных между собой таблиц.
С созданием реляционных баз данных был начат новый этап в эволюции СУБД. Простота и гибкость модели привлекли к ней внимание разработчиков и снискали ей множество сторонников. Несмотря на некоторые недостатки, реляционная модель данных стала доминирующей, а реляционные СУБД стали промышленным стандартом "де-факто".
Рассмотрим последний вопрос этого раздела, а именно вопрос о пользователях баз данных и их основным функциям по отношению к базам данных..
Пользователями БД являются четыре основные категории потребителей ее информации и поставщиков информации для нее:
· конечные пользователи;
· программисты и системные аналитики;
· персонал поддержки БД в актуальном состоянии;
· администратор БД.
Конечным пользователям для обеспечения доступа к информации БД предоставляется графический интерфейс, как правило, в виде системы окон с функциональными меню, позволяющими легко получать необходимую информацию на экран и/или принтер в виде удобно оформленных отчетов.
Программисты и системные аналитики используют БД совершенно в ином качестве, обеспечивая разработку новых БД-приложений, поддерживая и модифицируя (при необходимости) уже существующие. Для данной группы пользователей БД требуются средства, обеспечивающие указанные функции (создание, отладка, редактирование и т.д.).
Пользователи третьей категории нуждаются в интерфейсе, как правило, графическом для обеспечения задач поддержания БД в актуальном состоянии. Эти пользователи состоят в штатах подразделений функциональных и/или обработки информации, обеспечивающих прикладную область, и отвечают за актуальное состояние соответствующей ей БД (контроль текущего состояния, удаление устаревшей информации, добавление новой и т.д.).
Особую и ответственную роль выполняет администратор, отвечающий как за актуальность находящейся в БД информации, так и за корректность функционирования и использования БД.
Литература по разделу:
| № | Литература | Раздел |
| Кузнецов С.Д. Основы баз данных: Учебное пособие / С.Д.Кузнецов.- 2-е изд. испр.- М.:Интернет-Университет Информационных технологий; БИНОМ.Лаборатория знаний, 2010.- 484 с.: ил. | Лекция 1. стр.15- 36 | |
| Хомоненко А.Д., Цыганков В.М., Мальцев М.Г. Базы данных: Учебник для высших учебных заведений/ Под ред. Проф. А.Д.Хомоненко.- 6-е изд.- СПб.:КОРОНА-Век, 2010.-736 с. | Стр. 9- 47 | |
| Голицына О.Л., Максимов Н.В., Попов И.И. Базы данных:учеб.пособие.-2-е изд. испр. и доп.- М.:ФОРУМ: ИНФРА-М, 2009.- 400 с.:ил. | Стр. 47- 87 |
Вопросы для самопроверки:
Для каких целей создаются базы данных и в каких областях?
Приведите пример использования баз данных в области экономики?
Возможно ли создание базы данных в программе Excel ?
Какие модели организации данных используют современные базы данных?
В чем отличие файл-серверных баз данных и баз данных на основе клиент-сервера?
В чем разница централизованных и децентрализованных баз данных ?
Как по вашему сказалось появление персональных компьютеров на развитие баз данных ?
Какова роль администратора баз данных?
Приведите пример серверных СУБД?
К какому классу СУБД относится Access ?
(сноска1 Восприятие реального мира можно соотнести с последовательностью разных, хотя иногда и взаимосвязанных, явлений. С давних времен люди пытались описать эти явления (даже тогда, когда не могли их понять). Такое описание называют данными. Традиционно фиксация данных осуществляется с помощью конкретного средства общения (например, с помощью естественного языка или изображений на конкретном носителе на камне, бумаге и т.д.). Обычно данные (факты, явления, события, идеи или предметы) и их интерпретация (семантика) фиксируются совместно, так как естественный язык достаточно гибок для представления того и другого. Примером может служить утверждение "Стоимость авиабилета 128". Здесь "128" – данное, а "Стоимость авиабилета" – его семантика. Нередко данные и интерпретация разделены. Например, "Расписание движения самолетов" может быть представлено в виде таблицы, в верхней части которой (отдельно от данных) приводится их интерпретация. Такое разделение затрудняет работу с данными (попробуйте быстро получить сведения из нижней части таблицы).
| Интерпретация | |||||||
| Номер рейса | Дни недели | Пункт отправления | Время вылета | Пункт назначения | Время прибытия | Тип самолета | Стоимость билета |
| Данные | |||||||
| 2_4_7 | Баку | 21.12 | Москва | 0.52 | ИЛ-86 | 115.00 | |
| 3_6 | Ереван | 7.20 | Киев | 9.25 | ТУ-154 | 92.00 | |
| 1 по 7 | Москва | 9.05 | Киев | 11.05 | ТУ-154 | 57.00 | |
| 1_3_5 | Рига | 21.53 | Таллин | 22.57 | АН-24 | 21.50 | |
| 3_6 | Сочи | 18.25 | Баку | 20.12 | ТУ-134 | 44.00 |
Применение ЭВМ для хранения и обработки данных обычно приводит к еще большему разделению данных и интерпретации. ЭВМ имеет дело главным образом с данными как таковыми. Большая часть интерпретирующей информации вообще не фиксируется в явной форме (ЭВМ не "знает", является ли "21.50" стоимостью авиабилета или временем вылета). Почему же это произошло?
Существует по крайней мере две исторические причины, по которым применение ЭВМ привело к отделению данных от интерпретации:
· Во-первых, ЭВМ не обладали достаточными возможностями для обработки текстов на естественном языке – основном языке интерпретации данных.
· Во-вторых, стоимость памяти ЭВМ была первоначально весьма велика. Память использовалась для хранения самих данных, а интерпретация традиционно возлагалась на пользователя. Пользователь закладывал интерпретацию данных в свою программу, которая "знала", например, что шестое вводимое значение связано с временем прибытия самолета, а четвертое – с временем его вылета. Это существенно повышало роль программы, так как вне интерпретации данные представляют собой не более чем совокупность битов на запоминающем устройстве.
Первичными компонентами данных являются цифры и символы естественного языка или их кодированное представление в виде строки двоичных битов. Наименьшей семантически значимой поименованной единицей данных является элемент данных.
Поименованная совокупность элементов данных, рассматриваемая в программе обработки данных как единое целое, носит название агрегата данных. Агрегатами данных могут являться, например, дата, фамилия, имя, отчество.
Упорядоченная совокупность значений взаимосвязанных элементов данных называется логической записью.
Жесткая зависимость между данными и использующими их программами создает серьезные проблемы в ведении данных и делает использования их менее гибкими. Нередки случаи, когда пользователи одной и той же ЭВМ создают и используют в своих программах разные наборы данных, содержащие сходную информацию. Иногда это связано с тем, что пользователь не знает (либо не захотел узнать), что в соседней комнате или за соседним столом сидит сотрудник, который уже давно ввел в ЭВМ нужные данные. Чаще потому, что при совместном использовании одних и тех же данных возникает масса проблем.
Разработчики прикладных программ (написанных, например, на Бейсике, Паскале или Си) размещают нужные им данные в файлах, организуя их наиболее удобным для себя образом. При этом одни и те же данные могут иметь в разных приложениях совершенно разную организацию (разную последовательность размещения в записи, разные форматы одних и тех же полей и т.п.). Обобществить такие данные чрезвычайно трудно: например, любое изменение структуры записи файла, производимое одним из разработчиков, приводит к необходимости изменения другими разработчиками тех программ, которые используют записи этого файла.
В условиях автоматизированного управления централизованной базой данных все такие изменения связаны с функциями управляющей программы базы данных. Программы, не использующие значения почтового индекса, не нуждаются в модификации - в них, как и прежде, в соответствии с запросами посылаются те же элементы данных. В таких случаях внесенное изменение неощутимо. Модифицировать необходимо только те программы, которые пользуются новым элементом данных.
Ведение (сопровождение, поддержка) данных – термин, объединяющий действия по добавлению, удалению или изменению хранимых данных.
Выводы:
Используя понятие «данные» не следует забывать, что оно включает две составляющие – непосредственно данные и их интерпретацию. Одно без другого эти составляющие не представляют для пользователя ценности их необходимо использовать совместно.
(сноска 2) В качестве основных классификационных признаков можно использовать следующие: вид программы, характер использования, модель данных. Названные признаки существенно влияют на целевой выбор СУБД и эффективность использования разрабатываемой информационной системы.
Классификация СУБД. В общем случае под СУБД можно понимать любой программный продукт, поддерживающий процессы создания, ведения и использования БД. Рассмотрим, какие из имеющихся на рынке программ имеют отношение к БД и в какой мере они связаны с базами данных.
К СУБД относятся следующие основные виды программ:
•полнофункциональные СУБД;
• серверы БД;
•клиенты БД;
• средства разработки программ работы с БД.
Полнофункциональные СУБД (ПФСУБД) представляют собой традиционные СУБД, которые сначала появились для больших машин, затем для мини-машин и для ПЭВМ. Из числа всех СУБД современные ПФСУБД являются наиболее многочисленными и мощными по своим возможностям. К ПФСУБД относятся, например, такие пакеты, как Сlarion, dВаsе IV, Мiсгоsoft Ассеss, Microsoft FoxPro, Paradox, rBase.
Обычно ПФСУБД имеют развитый интерфейс, позволяющий с помощью команд меню выполнять основные действия с БД: создавать и модифицировать структуры таблиц, вводить данные, формировать запросы, разрабатывать отчеты, выводить их на печать и т. п. Для создания запросов и отчетов не обязательно программирование, а удобно пользоваться языком QBE (формулировки запросов по образцу). Многие ПФСУБД включают средства программирования для профессиональных разработчиков.
Некоторые системы имеют в качестве вспомогательных и дополнительные средства проектирования схем БД или САSЕ-подсистемы. Для обеспечения доступа к другим БД или к данным SQL-серверов полнофункциональные СУБД имеют факультативные модули.
Серверы БД предназначены для организации центров обработки данных в сетях ЭВМ. Эта группа БД в настоящее время менее многочисленна, но их количество постепенно растет. Серверы БД реализуют функции управления базами данных, запрашиваемые другими (клиентскими) программами обычно с помощью операторовSQL. Примерами серверов БД являются следующие программы: NetWare SQL, Novell, MS SQL, Server Microsoft, InterBase (Borland), SQL Base Server.
В роли клиентских программ для серверов БД в общем случае могут использоваться различные программы: ПФСУБД, электронные таблицы, текстовые процессоры, программы электронной почты и т. д. При этом элементы пары «клиент — сервер» могут принадлежать одному или разным производителям программного обеспечения.
В случае, когда клиентская и серверная части выполнены одной фирмой, естественно ожидать, что распределение функций между ними выполнено рационально. В остальных случаях обычно преследуется цель обеспечения доступа к данным «любой ценой». Примером такого соединения является случай, когда одна из полнофункциональных СУБД играет роль сервера, а вторая СУБД (другого производителя) — роль клиента. Так, для сервера БД SQL Server в роли клиентских (фронтальных) программ могут выступать многие СУБД, такие как dВАSЕ IV, Paradox и др.
Средства разработки программ работы с БД могут использоваться для создания разновидностей следующих программ:
• клиентских программ;
• серверов БД и их отдельных компонентов;
• пользовательских приложений.
Программы первого и второго вида довольно малочисленны, так как предназначены, главным образом, для системных программистов. Пакетов третьего вида гораздо больше, но меньше, чем полнофункциональных СУБД.
К средствам разработки пользовательских приложений относятся системы программирования, напримерClipper, разнообразные библиотеки программ для различных языков программирования, а также пакеты автоматизации разработок (в том числе систем типа клиент-сервер). В числе наиболее распространенных можно назвать следующие инструментальные системы: Delphi, Power Builder, Visual Basic, Erwin. Кроме перечисленных средств, для управления данными и организации обслуживания БД используются различные дополнительные средства, к примеру мониторы транзакций.
По характеру использования СУБД делят на персональные и многопользовательские.
Персональные СУБД обычно обеспечивают возможность создания персональных БД и недорогих приложений, работающих с ними. Персональные СУБД или разработанные с их помощью приложения зачастую могут выступать в роли клиентской части многопользовательской СУБД. К персональным СУБД, например, относятся Visual FохРго, Рагаdox, Clipper, Access и др.
Многопользовательские СУБД включают в себя сервер БД и клиентскую часть и, как правило, могут работать в неоднородной вычислительной среде (с разными типами ЭВМ и операционными системами). К многопользовательским СУБД относятся, например, СУБД Огасlе и Informix.
По используемой модели данных СУБД (как и БД), разделяют на иерархические, сетевые, реляционные, объектно-ориентированные и другие типы. Некоторые СУБД могут одновременно поддерживать несколько моделей данных.