Индекс множественной корреляции R
Б) расчет модельных ошибок Е
Оценка достоверности модели: А) расчет модельных значений Т + S
Моделирование ряда
 - аддитивная модель
- аддитивная модель
Порядок построения модели:
1) Выравнивание исходного ряда;
2) Расчет сезонной компоненты S;
3) Устранение сезонной компоненты и получение ряда у – S = Т +Е;
4) Аналитическое выравнивание ряда Т + Е;
Задача: Смоделировать ряд потребления электроэнергии и оценить достоверность модели.
Таблица 1.
| № квартала | Потребление э\э, у | Итого за 4 квартала | Скользящая средняя за 4 квартала | Централизованная скользящая средняя | Оценка сезонной компоненты |
| 6,0 | - | - | - | - | |
| 4,4 | - | - | - | - | |
| 5,0 | 24,4 | 6,10 | 6,250 | -1,250 | |
| 9,0 | 25,6 | 6,40 | 6,450 | 2,550 | |
| 7,2 | 26,0 | 6,50 | 6,625 | 0,575 | |
| 4,8 | 27,0 | 6,75 | 6,875 | -2,075 | |
| 6,0 | 28,0 | 7,00 | 7,100 | -1,100 | |
| 10,0 | 28,8 | 7,20 | 7,300 | 2,700 | |
| 8,0 | 29,6 | 7,40 | 7,450 | 0,550 | |
| 5,6 | 30,0 | 7,50 | 7,625 | -2,025 | |
| 6,4 | 31,0 | 7,75 | 7,875 | -1,475 | |
| 11,0 | 32,0 | 8,00 | 8,125 | 2,875 | |
| 9,0 | 33,0 | 8,25 | 8,325 | 0,675 | |
| 6,6 | 33,6 | 8,40 | 8,375 | -1,775 | |
| 7,0 | 33,4 | 8,35 | |||
| 10,8 |
Рисунок 1.
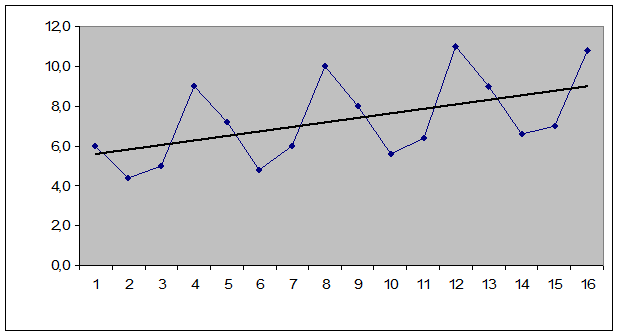
Амплитуда колебаний постоянна, поэтому можно применить аддитивную модель.
Значения выравниваются по 4 периодам, потому что сезонность имеет лаг = 4.
Таблица 2.
Цель: Рассчитать среднюю сезонность за квартал (среднюю сезонную компоненту).
| Показатели | Год | № квартала,i | |||
| Сезонная компонента за 4 квартала (ежеквартально) | - | - | -1,25 | 2,55 | |
| 0,575 | -2,075 | -1,1 | 2,7 | ||
| 0,55 | -2,025 | -1,475 | 2,875 | ||
| 0,675 | -1,775 | - | - | ||
| Итого за i квартал | 1,800 | -5,875 | -3,825 | 8,125 | |
| Средняя оценка сезонной компоненты для i квартала, Sср.i | 0,600 | -1,958 | -1,275 | 2,708 | |
| Скорректированная сезонная компонента, Si | 0,581 | -1,977 | -1,294 | 2,690 |
Сезонная компонента в среднем за весь период должна взаимопогашаться. Проверим данное утверждение:
1) 0,6 – 1,958 – 1,275 + 2,708 = 0,075
2) k = 0,075 / 4 = 0,019
3) Si1 = 0,600 – 0,019 = 0,581
Таблица 3. Расчет выровненных значений Т и ошибок Е в аддитивной модели.
| № квартала, t | Потребле- ние э/э, у | Si | Т+Е=у-Si | Т | Т+S | E=y-(T+S) | 
|  
| |
| 6,0 | 0,581 | 5,419 | 5,902 | 6,483 | -0,483 | 0,233 | -1,3 | 1,69 | |
| 4,4 | -1,977 | 6,377 | 6,088 | 4,111 | 0,289 | 0,083 | -2,9 | 8,41 | |
| 5,0 | -1,294 | 6,294 | 6,275 | 4,981 | 0,019 | 0,000 | -2,3 | 5,29 | |
| 9,0 | 2,690 | 6,310 | 6,461 | 9,151 | -0,151 | 0,023 | 1,7 | 2,89 | |
| 7,2 | 0,581 | 6,619 | 6,648 | 7,229 | -0,029 | 0,001 | -0,1 | 0,01 | |
| 4,8 | -1,977 | 6,777 | 6,834 | 4,857 | -0,057 | 0,003 | -2,5 | 6,25 | |
| 6,0 | -1,294 | 7,294 | 7,020 | 5,726 | 0,274 | 0,075 | -1,3 | 1,69 | |
| 10,0 | 2,690 | 7,310 | 7,207 | 9,897 | 0,103 | 0,011 | 2,7 | 7,29 | |
| 8,0 | 0,581 | 7,419 | 7,393 | 7,974 | 0,026 | 0,001 | 0,7 | 0,49 | |
| 5,6 | -1,977 | 7,577 | 7,580 | 5,603 | -0,003 | 0,000 | -1,7 | 2,89 | |
| 6,4 | -1,294 | 7,694 | 7,766 | 6,472 | -0,072 | 0,005 | -0,9 | 0,81 | |
| 11,0 | 2,690 | 8,310 | 7,952 | 10,642 | 0,358 | 0,128 | 3,7 | 13,69 | |
| 9,0 | 0,581 | 8,419 | 8,139 | 8,720 | 0,280 | 0,078 | 1,7 | 2,89 | |
| 6,6 | -1,977 | 8,577 | 8,325 | 6,348 | 0,252 | 0,063 | -0,7 | 0,49 | |
| 7,0 | -1,294 | 8,294 | 8,512 | 7,218 | -0,218 | 0,047 | -0,3 | 0,09 | |
| 10,8 | 2,690 | 8,110 | 8,698 | 11,388 | -0,588 | 0,346 | 3,5 | 12,25 | |
| Итого: | 116,8 | 116,800 | 1,098 | 67,12 |
Столбец 4 очищен от сезонных колебаний и содержит только тренд (тенденцию) и случайную компоненту.
С помощью функции ЛИНЕЙН найдем параметры линейного тренда
| ЛИНЕЙН | |
| 0,18641 | 5,7155 |
Уравнение тренда: уt = 5,715 + 0,186 · t
Параметры уравнения получены с помощью функции ЛИНЕЙН.
t – номер квартала (1й столбец).
С целью сравнить величину ошибки с дисперсией данных, найдем:
А) среднее значение ряда: 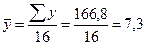
Б) квадраты отклонений от средних значений.
Рассчитаем точность модели: для этого сумму ошибок разделим на сумму квадратов отклонений: 
Ошибки составляют 1,6 в общей сумме квадратов отклонений. Это очень точная модель.
Тема 4. Выравнивание рядов динамики по мультипликативной модели
Таблица 1. Прибыль компании, тыс.долл. США
| Год | № квартала, i | |||
Рисунок 1.

По графику видны затухающие колебания, поэтому используем мультипликативную модель.
Порядок выравнивания аналогичен аддитивной модели.
Таблица 2.
| № квартала, t | Прибыль компании, у | Итого за 4 квартала | Скользящая средняя за 4 квартала | Централизованная скользящая средняя | Оценка сезонной компоненты |
| - | - | - | - | ||
| - | - | - | - | ||
| 326,0 | 81,5 | 81,25 | 1,108 | ||
| 324,0 | 81,0 | 80,00 | 0,800 | ||
| 316,0 | 79,0 | 77,75 | 0,900 | ||
| 306,0 | 76,5 | 75,75 | 1,215 | ||
| 300,0 | 75,0 | 74,00 | 1,081 | ||
| 292,0 | 73,0 | 71,50 | 0,811 | ||
| 280,0 | 70,0 | 68,50 | 0,905 | ||
| 268,0 | 67,0 | 65,75 | 1,217 | ||
| 258,0 | 64,5 | 63,25 | 1,075 | ||
| 248,0 | 62,0 | 59,50 | 0,807 | ||
| 228,0 | 57,0 | 54,75 | 0,950 | ||
| 210,0 | 52,5 | 50,25 | 1,194 | ||
| 192,0 | 48,0 | ||||
Оценим сезонную компоненту путем деления фактических значений на центрированную скользящую среднюю.
Таблица 3. Расчет сезонной компоненты в мультипликативной модели.
| Показатели | Год | № квартала,i | |||
| Сезонная компонента за 4 квартала (ежеквартально) | - | - | 1,108 | 0,800 | |
| 0,900 | 1,215 | 1,081 | 0,817 | ||
| 0,905 | 1,217 | 1,075 | 0,807 | ||
| 0,950 | 1,194 | - | - | ||
| Итого за i квартал | 2,755 | 3,626 | 3,264 | 2,42 | |
| Средняя оценка сезонной компоненты для i квартала, Sср.i | 0,918 | 1,209 | 1,088 | 0,808 | |
| Скорректированная сезонная компонента, Si | 0,913 | 1,201 | 1,081 | 0,803 |
В мультипликативных моделях сумма всех сезонных компонент должна составлять 4, т.е. сезонная компонента выступает «весом». В нашем случае сумма сезонных компонент = 4,023 (0,918 + 1,209 + 1,088 + 0,808 = 4,023), поэтому нужно найти корректирующий коэффициент: 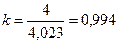 .
.
| ЛИНЕЙН | |
| -2,77514 | 90,57874 |

 Таблица 4. Расчет выровненных значений Т и ошибок Е в мультипликативной модели.
Таблица 4. Расчет выровненных значений Т и ошибок Е в мультипликативной модели.
| № квар-тала, t | Потре-бление э/э, | Si | Т+Е=у/Si | Т | Т·S | E=y/(T·S) | E'=y-(T·S) | |||
| у | ||||||||||
| 0,913 | 78,86 | 87,80 | 80,17 | 0,898 | -8,165 | 0,807 | 4,75 | 22,56 | ||
| 1,202 | 83,19 | 85,03 | 102,20 | 0,978 | -2,205 | 0,957 | 100,00 | 10000,00 | ||
| 1,082 | 83,18 | 82,25 | 89,00 | 1,011 | 1,001 | 1,023 | 90,00 | 8100,00 | ||
| 0,803 | 79,70 | 79,48 | 63,82 | 1,003 | 0,178 | 1,006 | 64,00 | 4096,00 | ||
| 0,913 | 76,67 | 76,70 | 70,03 | 1,000 | -0,031 | 0,999 | 70,00 | 4900,00 | ||
| 1,202 | 76,54 | 73,93 | 88,86 | 1,035 | 3,137 | 1,072 | 92,00 | 8464,00 | ||
| 1,082 | 73,94 | 71,15 | 76,99 | 1,039 | 3,011 | 1,080 | 80,00 | 6400,00 | ||
| 0,803 | 72,23 | 68,38 | 54,91 | 1,056 | 3,092 | 1,116 | 58,00 | 3364,00 | ||
| 0,913 | 67,91 | 65,60 | 59,90 | 1,035 | 2,104 | 1,071 | 62,00 | 3844,00 | ||
| 1,202 | 66,56 | 62,83 | 75,52 | 1,059 | 4,480 | 1,122 | 80,00 | 6400,00 | ||
| 1,082 | 62,85 | 60,05 | 64,98 | 1,047 | 3,022 | 1,095 | 68,00 | 4624,00 | ||
| 0,803 | 59,78 | 57,28 | 46,00 | 1,044 | 2,005 | 1,089 | 48,00 | 2304,00 | ||
| 0,913 | 56,96 | 54,50 | 49,76 | 1,045 | 2,238 | 1,092 | 52,00 | 2704,00 | ||
| 1,202 | 49,92 | 51,73 | 62,18 | 0,965 | -2,178 | 0,931 | 60,00 | 3600,00 | ||
| 1,082 | 46,21 | 48,95 | 52,97 | 0,944 | -2,968 | 0,891 | 50,00 | 2500,00 | ||
| 0,803 | 37,36 | 46,18 | 37,08 | 0,809 | -7,082 | 0,655 | 30,00 | 900,00 | ||
| Итого: | 1071,84 | 1,639 | 1008,75 |
Тема 5. Парная линейная регрессия
Виды регрессии: - парная y = f(x)
- множественная (зависит от множества факторов)
y = f(x1, x2, x3 … xn)
Большинство эконометрических моделей можно свести к парной регрессии, поэтому она получила широкое распространение.
Парная регрессия
Порядок распространения связи при парной регрессии:
1. Теоретическое обоснование связи.
Регрессия может быть парной, если существует доминирующий фактор, который влияет на результат у = ух + ε
ух – теоретические частоты;
ε – ошибка (возмущение).
Существует три рода ошибок:
1) Ошибки спецификации модели
Неверно подобрана функция или её параметры.
Методы устранения: оценка нескольких функций и выбор наилучшей.
2) Выборочный характер исходных данных
Совокупность исходных данных может быть неоднородна, тогда МНК не имеет смысла, т.к. он основан на расчете дисперсий. Поэтому из данных исключают наиболее выдающиеся в ту или иную сторону.
Методы устранения: расчет доверительных интервалов.
3) Особенности измерения переменных
Например, доход на душу населения не является точным, т.к. отсутствуют данные о сокрытых доходах.
Методы устранения: досчет на основе выборочных обследований; совершение операций сбора данных.
При анализе данных считают, что они однородны и точны, т.е. ошибки 2 и 3 рода устранены. Поэтому, уделяют наибольшее внимание устранению ошибок спецификации, т.е. подбору наиболее подходящего уравнения ух. Цель этого отбора – уменьшить ошибки.
2. Выбор математической функции.
Осуществляется 3 методами:
А) графический
Б) аналитический
В) экспериментальный (по min остаточной дисперсии)
!Если остаточная дисперсия одинакова для нескольких функций, то выбирают наиболее простую.
! Каждый параметр при х должен рассчитываться по 6-7 наблюдениям.
Легче всего поддаются интерпретации линейные модели, тем более они требуют меньшего числа наблюдений, поэтому линейные модели изучают подробно, а нелинейные – подлежат линеализации.
Парная линейная регрессия
1. Вид: у = а + bх + ε
ε – ошибка спецификации.
2. Графическая интерпретация МНК
Рисунок 1.

Т.е. находим min ∑(уi - yix)


Если разделим верхнюю часть на n, то:


 - альтернативный метод расчета дисперсии
- альтернативный метод расчета дисперсии
3. Интерпретация параметров a и b
b – коэффициент регрессии, показывающий на сколько в среднем изменилась функция, если изменить фактор на одну единицу.
а – значения функции при х = 0. Он не имеет экономического смысла, если оно отрицательно или х ни при каких условиях не равно 0.
Если а > 0 – вариация результата меньше, чем вариация фактора.
Если а < 0 - вариация результата больше, чем вариация фактора.
4. Измерение тесноты связи
Существует коэффициент парной линейной регрессии:

Если b > 0, то r > 0.
Если b < 0, то r < 0.
Если r ≈ 0 √ связи нет,
√ связь нелинейная.
5. Оценка качества модели
1)Осуществляется с помощью коэффициента детерминации:

Показывает, сколько процентов вариации у вы объяснили в вашей модели.
2)Критерий Фишера:
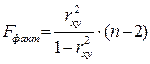
Показывает на сколько модель статистически значима.
3)Стандартные ошибки в уравнении регрессии
 - стандартная ошибка ля параметра b.
- стандартная ошибка ля параметра b.
Она зависит от Х. Они применяется для проверки существенности коэффициента регрессии b и расчета его доверительных интервалов.
Существенность: 
Если критерий Стьюдента меньше табличного при заданном значении степеней свободы, то гипотеза о несущественности параметра b принимается.
Для прогнозирования используют интервальные значения параметра b, т.е. доверительные интервалы: b ± t · mb
t – табличное значение критерия Стьюдента.

Стандартная ошибка для параметра а:


ta сравнивается с табличным значением при (n-2) степеней свободы.

 - критерий Стьюдента
- критерий Стьюдента
Т.о. проверка гипотез о значимости коэффициента регрессии и коэффициента корреляции проводится одинаково. Если коэффициент регрессии значимый, то коэффициент корреляции значимый.
6. Интервалы прогноза по уравнению регрессии
Чтобы понять, как определить величину стандартной ошибки, подставим в уравнение регрессии значение параметра а.
ух = а + bх


Заменим значение ух, 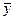 и b на значение их ошибок и получим:
и b на значение их ошибок и получим:

Из теории выборки известно, что средняя ошибка выборки: 
Используем вместо дисперсии σ2 остаточную дисперсию на 1 степень свободы:
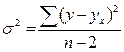
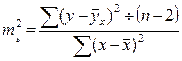
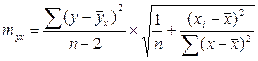
Хi - прогнозное значение фактора Х, при котором мы хотим получить значение У.
ух ± t · mух – формула для прогнозного значения У.
t – коэффициент Стьюдента при заданной степени вероятности.
В таблице приведены данные о потреблении и заработной плате по нескольким регионам Уральского Федерального округа.
Х – заработная плата;
У – потребление.
Задание: 1) выровнять модель методом линейной регрессии;
2) оценить надежность модели;
3) измерить тесноту связи и дать интерпретацию коэффициентам;
4) оценить уровень потребления при заданной заработной плате 65,0.
Таблица 1.
| № п/п | у | х | у·х | х2 | у2 | ух | у-ух | (у-ух)2 | А | 
|
| 68,8 | 45,1 | 3102,9 | 2034,0 | 4733,4 | 61,5 | 7,3 | 53,1 | 96,0 | ||
| 61,2 | 59,0 | 3610,8 | 3481,0 | 3745,4 | 56,4 | 4,8 | 23,3 | 3481,0 | ||
| 59,9 | 57,2 | 3426,3 | 3271,8 | 3588,0 | 57,0 | 2,9 | 8,2 | 3271,8 | ||
| 56,7 | 61,8 | 3504,1 | 3819,2 | 3214,9 | 55,3 | 1,4 | 1,9 | 3819,2 | ||
| 55,0 | 58,8 | 3234,0 | 3457,4 | 3025,0 | 56,4 | -1,4 | 2,1 | 3457,4 | ||
| 54,3 | 47,2 | 2563,0 | 2227,8 | 2948,5 | 60,7 | -6,4 | 41,4 | 2227,8 | ||
| 49,3 | 55,2 | 2721,4 | 3047,0 | 2430,5 | 57,8 | -8,5 | 71,8 | 3047,0 | ||
| Итого | 405,2 | 384,3 | 22162,3 | 21338,4 | 23685,8 | 201,8 | ||||
| Ср.знач. | 57,9 | 54,9 | 3166,0 | 3048,3 | 3383,7 | 28,8 |
1) Уравнение линейной регрессии у = а + bх

Вывод: потребление уменьшится на 0,37, если заработная плата увеличится на одну единицу.


Вывод: если а > 0, то вариация результата меньше вариации фактора.
а = 78,21% - уравнение регрессии ненадежно.
2) Оценим надежность модели и тесноту связи



Вывод: связь обратная, средняя. Совпадает связь при r и b.
3) Оценим качество модели
Рассчитаем ошибку аппроксимации и коэффициент детерминации
4)Рассчитаем среднюю ошибку аппроксимации
5) Рассчитаем критерий Фишера
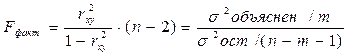

Вывод: чем больше Fфакт, тем надежнее уравнение.
m – количество переменных при х = степени свободы числителя.
n – количество измерений.
m-n-1 – степень свободы знаменателя.
Для σ2у соответствует степень свободы, равная (n-1).
Для σ2объяснен. соответствует степень свободы, равная m.
Для σ2ост. соответствует степень свободы, равная (n-m-1).
Если регрессия линейная, то n-1=1+(n-1-1)
n-1=1+(n-2)
Критерий Фишера представляет из себя таблицу.
Фрагмент таблицы: при ά = 0,05
| К1 | … | |||
| К2 | ||||
| … … | 161,45 18,51 10,13 … 6,61 … | 199,50 19,0 9,55 … | 215,72 19,16 9,28 … | … |
К1 – степень свободы чисоителя;
К2 – степень свободв знаменателя.
Для линейной регрессии К1 = 1.
ά – вероятность ошибки, т.е. можно ошибочно отвергнуть верную гипотезу с такой вероятностью.

К2 = n-m-1 = 5
При 5 критерий Фишера равен табличному 6,61.
Fфакт. < Fтабл => Уравнение статистически не значимо с вероятностью 0,95. Уравнение не значимо, т.е. коэффициенты уравнения регрессии были получены случайным образом.
6)
Уравнение объясняет 15,2% дисперсии.
7) - t-статистика.

После вычисления t-статистики фактической, её нужно сравнить с табличным значением t. t-критерий (критерий Стьюдента) является двухсторонним, т.е. если мы получили ta, tb, tr меньше 0, следовательно нужно взять 
Фрагмент таблицы.
| Число степеней свободы | ά | ||
| 0,10 | 0,05 | 0,01 | |
| … | 6,3 2,9 … 2,01 | 12,7 4,3 … 2,57 | 63,6 9,9 … 4,03 |
ά – вероятность ошибки.
Мы гарантируем результат вероятностью равной (1- ά).
Число степеней свободы для линейной регрессии d · f = n – 2


tbтабл. = 2,01 при ά = 0,1 => параметр b статистически не значим с вероятностью 0,9.
8) Вычисление прогноза
ух ± t · mух
mух рассчитывается из данных, а t берется из таблицы при соответствующей степени свободы в зависимости от того, какой уровень значимости мы хотим получить при определенной степени свободы.
Тема 6. Нелинейная регрессия
Различают два класса нелинейной регрессии:
Класс I : Регрессия нелинейная, относительно включенных в анализ объясняющих переменных, но линейная по оцениваемым параметрам.
Сюда входят: А) полиномы всех степеней
Б) равносторонние гиперболы 
Класс II : Регрессия нелинейная по оцениваемым параметрам.
Сюда входят: А) степенная функция 
Б) показательная функция 
В) экспоненциальная функция 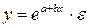
Г) другие функции 
Модели I класса
Цель при анализе моделей: определить параметры функции, тесноту связи и надежность.
Для этого класса можно использовать МНК.
1) Полином: √ второй степени 
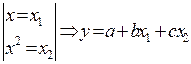
Процесс превращения нелинейных функций в линейный вид называется линеализацией.
√ k-той степени 

Параметры а, b, c,…, k можно определить МНК. Таким образом, полином любого порядка сводится к линейной регрессии.
Интерпретация параметров и использование в практике параболы
Парабола имеет следующий вид: у параболы существует точка перегиба. Это означает, что определенного предела функция ведет себя как возрастающая, а потом начинает убывать (наоборот).
На практике перечень таких явлений ограничен. Поэтому, во-первых, для выравнивания используют не всю параболу, а какой-либо её сегмент. Здесь надо помнить, что существует точка перегиба, после которой прогноз будет невозможен. Во-вторых, заменяют параболу на степенную функцию.
Система нормальных уравнений для определения параметров параболы

2) Равносторонняя гипербола 

Система нормальных уравнений для определения параметров равносторонней гиперболы

Интерпретация уравнения:
- если b > 0 , х →  => у → а - если b < 0 , х → => у → а
=> у → а - если b < 0 , х → => у → а
функция убывает функция возрастает


Все другие модели, которые приводятся к линейному виду путем замены переменных на соответствующие линейные.
Модели второго класса
1) Внутренне-линейные модели
Могут быть приведены к линейному виду путем логарифмирования или других преобразований.
а) Степенная функция


Решаем уравнение, применяя МНК.
После нахождения параметров a' и b проводим потенцирование и возвращаем уравнение к исходному виду.
б) экспоненциальная функция


К этому уравнению применим МНК.
2) Внутренне-нелинейные модели
Не могут быть приведены к линейному виду.

Для оценки их параметров используют метод подбора, т.к. нельзя использовать МНК.
Таким образом, в эконометрике к линейным моделям относят:
1. Модели, линейные по переменным и параметрам (например, у = а + вх)
2. Модели, так или иначе, сводимые к линейным, т.е. нелинейные внешне, но линейные внутренне.
Тема 7. Коэффициент эластичности


Коэффициент показывает, на сколько процентов изменится У при изменении Х на один процент.
Найдем коэффициент эластичности для степенной функции у = а ∙ хb ∙ ε

Для линейной функции:
у = а + вх 

Коэффициент эластичности зависит от значения Х, что неудобно.
Поэтому рассчитывают средний коэффициент эластичности, и работают с этим коэффициентом:

Интерпретация коэффициента эластичности: возможны случаи, когда коэффициент эластичности не имеет экономического смысла (например, х – стаж, у – заработная плата. При изменении стажа на 1% зарплата изменяется. Или х – срок кредита, у – ставка), тогда используют более простые способы интерпретации.
Оценка надежности модели
1) Теснота связи
 - индекс корреляции
- индекс корреляции
Изменяется от 0 до 1.
R = 1 – связь тесная. R = 0 – связь слабая.
 - индекс детерминации
- индекс детерминации
Показывает долю объясненной дисперсии в общей дисперсии результата.
 коэффициент Фишера
коэффициент Фишера
Проверка гипотезы о линейности
Если r2ху и R2ху равны, или их разность меньше, чем 0,1, то нет смысла усложнять работу и можно использовать линейную функцию.
Оценку надежности проводят с помощью критерия Стьюдента


Если tф > tтабл, то различие R2 и r2 существенны и замена функции на линейную невозможна.
Пример: По 7 территориям Уральского региона известны следующие данные
| № | Расх. на покупку продовол. т-ров,% | Ср.днев.з/п 1 раб.,руб. | У = lg y | Х = lg х | У ∙Х | Х^2 | Ух | у - Ух | (у-Ух)^2 | х∙у | (х - хср.)^2 |
| 68,8 | 45,1 | 1,8376 | 1,6542 | 3,0397 | 2,7363 | 7,8 | 60,8 | 3102,9 | 96,0 | ||
| 61,2 | 1,7868 | 1,7709 | 3,1641 | 3,1359 | 56,3 | 4,9 | 24,0 | 3610,8 | 16,8 | ||
| 59,9 | 57,2 | 1,7774 | 1,7574 | 3,1236 | 3,0884 | 56,8 | 3,1 | 9,6 | 3426,3 | 5,3 | |
| 56,7 | 61,8 | 1,7536 | 1,7910 | 3,1406 | 3,2076 | 55,5 | 1,2 | 1,4 | 3504,1 | 47,6 | |
| 58,8 | 1,7404 | 1,7694 | 3,0794 | 3,1307 | 56,3 | -1,3 | 1,7 | 3234,0 | 15,2 | ||
| 54,3 | 47,2 | 1,7348 | 1,6739 | 2,9040 | 2,8021 | 60,2 | -5,9 | 34,8 | 2563,0 | 59,3 | |
| 49,3 | 55,2 | 1,6928 | 1,7419 | 2,9488 | 3,0344 | 57,4 | -8,1 | 65,6 | 2721,4 | 0,1 | |
| 405,2 | 384,3 | 12,3234 | 12,1587 | 21,4002 | 21,1354 | 403,5 | 1,7 | 198,0 | 22162,3 | 240,3 |
Задание: 1) построить степенную функцию, рассчитать её параметры;
2) оценить с помощью критерия Фишера надежность модели и проверить гипотезу о линейности;
3) рассчитать коэффициенты эластичности; проверить гипотезу о линейности.
Степенная модель имеет вид: у = а ∙ хв
lgy= lga + b ∙ lgx
У = lgy; A = lga; X = lgx
У = A + bx



У = 2,278 – 0,298 ∙ х
у = 102,278 ∙ х-0,298 = 189,7 ∙ х-0,298
Рассчитаем критерий Фишера:

Доля объясненной дисперсии составляет 14%.

Fтабл = 6,61
Fфакт < Fтабл => с вероятностью 95% уравнение статистически не значимо. Это означает, что а и b получены случайным образом, и по такому уравнению нельзя делать прогноз.



Тема 8. Множественная регрессия
Спецификация модели
Парная регрессия дает хороший результат, если выявлен Олин фактор, очень сильно влияющий на результат, а влиянием всех остальных факторов можно пренебречь.
Такие зависимости характерны для химических, физических и биологических исследований, когда существует возможность постановки эксперимента.
Поставить эксперимент – организовать среду, когда все остальные факторы, кроме одного, будут зафиксированы на одном уровне.
В экономике такие зависимости встречаются редко, и отсутствует возможность проведения эксперимента. Поэтому для экономики характерны многофакторные зависимости.
Спецификация модели заключается в решении двух вопросов:
1) отбор факторов из множества существующих у = f (х1, х2, …, хn)
у = f (xi, xi+1, …, xk), где k < n
2) выбор вида уравнения регрессии
Отбор факторов при построении уравнения множественной регрессии
Факторы должны удовлетворять условиям:
1. Они должны быть количественно измеримы.
Если факторы качественные, нужно придать им количественную оценку ( например, проранжировать, присвоить рейтинг, т.п.).
2. Факторы не должны быть взаимозависимыми (интеркоррелированными), т.е. факторы не должны быть в функциональной связи между собой.
Если факторы интеркоррелированны, то невозможно определить их индивидуальное влияние на результат. Т.о. параметры уравнения невозможно интерпретировать.
3. Факторы должны объяснять корреляцию независимой переменной (результат), т.е. каждый следующий фактор, включенный в модель, должен увеличивать r2.
Т.е. при включении дополнительного фактора r2 должно возрастать существенно.
Существенно – если изменяется первый или второй знак после запятой.
R2n = 0,852
R2n+1 = 0,903 (нужно включить)
R2n+2 = 0,904 (несущественное изменение) (не нужно включать)
Если в модели есть «лишние» факторы, то модель может стать статистически не значимой.
Т.о. отбор факторов проводится в два этапа:
1) подбирают факторы исходя из существенности проблемы;
2) отбирают факторы по какому-нибудь алгоритму.
Тема 9. Мультиколлинеарность
Считают, что факторы коллинеарны, если rxixj ≥ 0,7, т.е факторы хi и xj тесно связаны между собой и находятся в линейной зависимости => хi и xj друг друга дублируют и один из них рекомендуется исключить из регрессии.
Оставляют в уравнении фактор, имеющий: 1) тесную связь с результатом;
2) наименьшую тесноту связи с другими факторами.
Для оценки мультиколлинеарности нужно построить матрицу парных линейных коэффициентов корреляции:
MS Excel: Сервис → Анализ данных → Корреляция → Выбор диапазона
В результате выходит таблица
| у | х1 | х2 | х3 | |
| у | ||||
| х1 | 0,8 | |||
| х2 | 0,7 | 0,8 | ||
| х3 | 0,6 | 0,5 | 0,2 |
Rx1x2 = 0,8 > 0,7 => х1 и x2 коллинеарны.
у = f (х2, х3) фактор х3 наиболее независим в данной системе, т.к. его линейные коэффициенты корреляции наименьшие (0,2).
Существуют случаи, когда нужно включить в модель факторы, имеющие сильную связь между собой, тогда используют следующие подходы для преодоления сильной межфакторной корреляции:
1. Исключение факторов;
2. Преобразование факторов, чтобы уменьшить корреляцию между ними:
А) переход к первым разностям
х1; х2; х3
х2 → х2 - х1; х3 → х3 – х2 и т.д.
Каждый уровень ряда заменяем на абсолютный прирост, соответствующий этому уровню. Используется в рядах динамики.
Б) метод главных компонент
Переход от исходных переменных к их линейным комбинациям.
3. Совмещенное уравнение регрессии
Отражает не только зависимость результата от фактора, но и совместное влияние факторов на результат.
у = f (х1, х2, х3)
ух = а+в1х1+в2х2+в3х3+в12х1∙х2+ в13х1∙х3+ в23х2∙х3+в123 х1∙х2∙х3
Ограничения для каждого параметра при х – нужно 6-7 измерений. Для данного уравнения нужно 42-49 измерений, что не всегда доступно.
4. Переход к уравнениям приведенной формы
Выражаем фактор из другого уравнения и подставляем в исходное уравнение.
Тема 10. Выбор формы уравнения регрессии
1) Линейная функция y = a + b1x1 + b2x2 + b3x3 + … + bnxn
«+»: - сравнительно просто отыскать параметры уравнения;
- сравнительно просто интерпретировать.
Результат увеличивается на величину b1 при изменении фактора х1 на единицу и всех остальных факторов, зафиксированных на среднем уровне.
2) Степенная функция y = a ∙ x1b1 ∙ x2b2 ∙ … ∙ xnbn
Интерпретация: b1, b2, bn - коэффициенты эластичности. Показывают, на сколько изменился результат в среднем при изменении соответствующего фактора на 1 %.
Другие функции используются редко.
Тема 11. Оценка параметров уравнения множественной регрессии
Отыскание параметров уравнения
Параметры уравнения множественной регрессии оцениваются МНК.
Для отыскания параметров сроится система нормальных уравнений.
y = a + b1x1 + b2x2 + b3x3 + … + bnxn
Тогда система нормальных уравнений принимает следующий вид:
∑y = na + b1∑x1 + b2∑x2 + b3∑x3 + … + bn∑xn
∑y ∙ x1 = a∑x1 + b1∑x12 + b2∑x1∙ x2 + b3∑ x1∙x3 + … + bn∑ x1∙xn
∑y ∙ x2 = a∑x2 + b1∑x1∙ x2 + b2∑x22 + b3∑ x2∙x3 + … + bn∑ x2∙xn
…
∑y ∙ xn = a∑xn + b1∑x1∙ xn + b2∑x2∙ xn + b3∑ x2∙x3 + … + bn∑xn2
Эту систему можно записать в следующем виде:
А = (a; b1; b2; bn)


Х = А ∙ У А = У ∙ Х-1
Если функция степенная, или другая нелинейная, то её сначала линеализуют, а затем применяют МНК.
Тема 12. Частные уравнения регрессии
Есть линейное уравнение вида y = a + b1x1 + b2x2 + b3x3 + … + bnxn, то можно найти частное уравнение регрессии вида 
Эти уравнения регрессии показывают связь между результатом и соответствующим фактором при закреплении других слагаемых на среднем уровне, т.е. позволяют точно оценить влияние фактора на результат.


Эти уравнения позволяют определить частные коэффициенты эластичности, которые показывают, на сколько процентов изменился результат под воздействием одного фактора изолированно в процентах.
Коэффициенты эластичности определяются точно также как для уравнения парной линейной регрессии:

Тема 13. Множественная корреляция
После отыскания параметров уравнение множественной регрессии нужно проверить на статистическую значимость и надежность.
Для этого используются: 1) Индекс множественной корреляции
2) Частные коэффициенты корреляции
3) F – критерий Фишера
4) t – статистика

σ2у – общая дисперсия результативного признака;
σ2ост – остаточная дисперсия для уравнения.


Этот индекс показывает, на сколько тесная связь между факторами и результатом.
Если модель построена правильно, то индекс множественной корреляции существенно отличается от максимального индекса парной корреляции.
Rx1x2…xn > max (rxy)
Индекс линейной корреляции может служить индикатором необходимости включения в модель дополнительного признака.
Если при включении дополнительного признака изменяется второй знак, то включение этого признака оправдано.
R2х1,х2,…,хn показывает процент объясненной регрессии с помощью данного уравнения.
2)Частные коэффициенты корреляции – это коэффициенты линейной корреляции, характеризующие тесноту связи между результатом и соответствующим фактором при устранении влияния всех других факторов, входящих в уравнение.

R2 в числителе = R2 всего уравнения
R2 в знаменателе = коэффициент детерминации при исключении фактора Хi
Порядок расчета: 1. Составляется матрица парных коэффициентов корреляции;
2. Находятся частные коэффициенты корреляции первого порядка (частные коэффициенты корреляции между У и двумя другими факторами).
х1 и х2: 
х1, х2, х3: ryx1x2 ryx2x3 ryx1x3
Далее проводим анализ, включение какого фактора оказывает сильное влияние на результат.
3) Критерий Фишера

Дфактор – факторная сумма квадратов, деленная на одну степень свободы.
Дост – остаточная сумма квадратов, деленная на одну степень свободы.
k – количество факторов или независимых переменных.
Коэффициент Фишера показывает значимость уравнения регрессии.
Если Fфакт > Fтабл – то уравнение регрессии статистически значимо.
4) t – статистика рассчитывается стандартным образом, и показывает статистическую значимость того или иного параметра.
Тема 14. Фиктивные переменные во множественной регрессии
Задача: Включить в модель качественный признак.
y = f (х1; х2)
y – частота потребления кофе;
х1 – личный доход;
х2 – пол.
х2 – переменная качественная, её нужно заменить на количественную. Для этого введем фиктивную переменную z.
Количество фиктивных переменных z должно соответствовать количеству значений, принимаемых признаком.
х2 → z: 

Составим уравнение: у = a + b1x1 + c1z1 + c2z2 + ε и решаем его стандартным способом (МНК).
Интерпретация уравнения регрессии: коэффициент при х1 имеет стандартную интерпретацию, коэффициенты при z1 и z2 нужны для составления частных уравнений регрессии.
В данном случае интерпретации подлежат частные коэффициенты корреляции.
Разность между коэффициентами при фиктивных переменных показывает относительное влияние качественного признака.