Многоуровневые индексы на основе В-дерева
Способы организации индексов
Существует множество способов организации индексов:
- В плотных индексах для каждого значения ключа имеется отдельная запись индекса, указывающая место размещения конкретной записи. Неплотные (разреженные) индексы строятся в предположении, что на каждой странице памяти хранятся записи, отсортированные по значениям индексируемого атрибута. Тогда для каждой страницы в индексе задаётся диапазон значений ключей хранимых в ней записей, и поиск записи осуществляется среди записей на указанной странице.
- Для больших индексов актуальна проблема сжатия ключа. Наиболее распространенный метод сжатия основан на устранении избыточности хранимых данных. Последовательно идущие значения ключа обычно имеют одинаковые начальные части, поэтому в каждой записи индекса можно хранить не полное значение ключа, а лишь информацию, позволяющую восстановить его из известного предыдущего значения. Такой индекс называется сжатым.
- Одноуровневый индекс представляет собой линейную совокупность значений одного или нескольких полей записи. На практике он используется редко. В развитых СУБД применяются более сложные методы организации индексов. Особенно эффективными являются многоуровневые индексы в виде сбалансированных деревьев (B-деревьев, balance trees).
B-дерево строится динамически по мере заполнения базы данными. Оно растёт вверх, и корневая вершина может меняться. Параметрами B-дерева являются порядок n и количество уровней. Порядок – это количество ссылок из вершины i-го уровня на вершины (i+1)-го уровня. Пример построения B-дерева порядка 3 приведён на рис. 4.5.
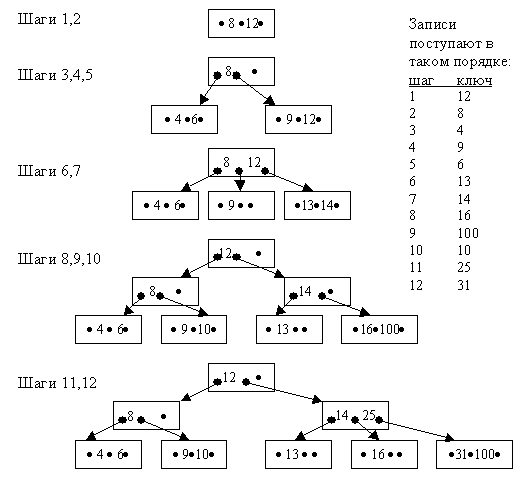
Рис.4.5. Пример построения B-дерева порядка 3
Каждое B-дерево должно удовлетворять следующим условиям:
- Все конечные вершины расположены на одном уровне, т.е. длина пути от корня к любой конечной вершине одинакова.
- Каждая вершина может содержать n адресных ссылок и (n-1) ключей. Ссылка влево от ключа обеспечивает переход к вершине дерева с меньшими значениями ключей, а вправо – к вершине с большими значениями.
- Любая неконечная вершина имеет не менее n/2 подчинённых вершин. (Для деревьев нечётного порядка значение n/2 округляется в большую сторону).
- Если неконечная вершина содержит k (k<n) ключей, то ей подчинена (k+1) вершина на следующем уровне иерархии.
Алгоритм формирования B-дерева порядка n предполагает, что сначала заполняется корневая вершина. Затем при появлении новой записи корневая вершина делится, образуются подчинённые ей вершины. При запоминании каждой новой записи поиск места для неё начинается с корневой вершины. Если в существующем на данный момент B-дереве нет места для размещения нового ключа, происходит сдвиг ключей вправо или влево, если это невозможно – осуществляется перестройка дерева.
В качестве конкретного примера рассмотрим индексирование в виде B-дерева, которое используется в СУБД Oracle (рис. 4.6).
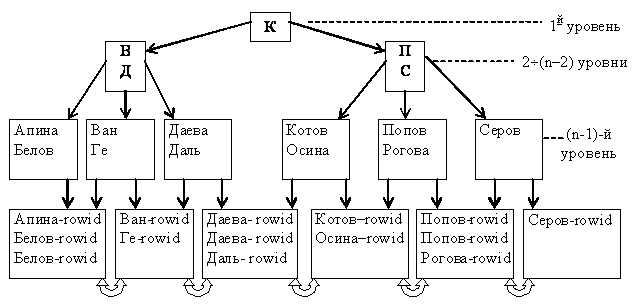
Рис.4.6. Пример индексного блока СУБД Oracle
Организация индексов в СУБД Oracle несколько отличается от рассмот-ренной выше классической организации B-дерева, но принцип остаётся тот же: одинаковое количество уровней на любом пути и автоматическая сбалансированность. Верхние блоки индекса содержат автоматически вычисляемые значения, которые позволяют осуществлять поиск данных. Предпоследний (n-1)-й уровень содержит значения индексируемого поля (атрибута) без повторов (т.е. каждое значение один раз). Самый нижний n-й уровень – блоки-листья, которые содержат индексируемые значения и соответствующие идентификаторы записей RowID (row identification, КБД), используемые для нахождения самих записей. Для неуникальных индексов значения идентификаторов строк (RowID) в блоках-листьях индекса также отсортированы по возрастанию. Блоки-листья связаны между собой двунаправленными ссылками.
Поиск по ключу осуществляется следующим образом. Блок верхнего уровня (уровень 1) содержит некоторое значение X и указатели на верхнюю и нижнюю части индекса. Если значение искомого ключа больше X, то происходит переход к верхней части индекса (по левому указателю), иначе – к нижней части. Блоки второго и последующих уровней (кроме двух последних) хранят начальное X0 и конечное значения Xк ключа, а также три указателя. Если значение искомого ключа меньше, чем X0, то происходит обращение по левому указателю; если оно больше, чем Xк, то происходит обращение по правому указателю; если оно попадает в диапазон X0÷Xк – по среднему указателю. Вершины, которые делят следующий уровень дерева на три поддерева, могут занимать несколько уровней. Это зависит от количества индексируемых записей и среднего размера индексируемых значений.
При обнаружении значения искомого ключа в блоке индекса происходит обращение к диску по RowID и извлечение требуемой записи (записей). Если же значение не обнаружено, результат поиска пуст.
Индекс в виде B-дерева автоматически поддерживается в сбалансированном виде. Это означает, что при переполнении какого-либо из блоков индекса происходит перераспределение значений ключей индекса (без физического перемещения записей данных). Например, если при добавлении новой записи с ключом "Горин" возникает переполнение соответствующего блока индекса (рис. 4.6), система может перестроить индекс так, как показано на рис. 4.7.

Рис.4.7. Пример перераспределения данных индексного блока СУБД Oracle
Если все блоки-листья индекса заполнены приблизительно на три четверти, то при добавлении новой записи осуществляется полная пере-стройка B-дерева путём введения дополнительного уровня. Всё это скрыто от пользователя и происходит автоматически.
Структура B-дерева имеет следующие преимущества: