Основные понятия
OLE
OPC
DCOM через интернет и решение проблемы XP SP2
В 2009 году DComLab опубликовал коммерческий продукт ComBridge. При использовании ComBridge для работы по DCOM через интернет не требуется CIS, не используется 135 порт, в локальной сети не требуются настройки dcomcnfg. ComBridge встраивается в транспортный уровень DCOM, полностью выделяя весь трафик созданного объекта и всех полученных из него объектов в отдельный поток.
OPC (OLE for Process Control) — семейство программных технологий, предоставляющих единый интерфейс для управления объектами автоматизации и технологическими процессами. Многие из OPC протоколов базируются на Windows-технологиях: OLE, ActiveX, COM/DCOM. Такие OPC протоколы, как OPC XML DA и OPC UA являются платформо-независимыми.
OLE (англ. Object Linking and Embedding, произносится как oh-lay [олэй] — Связывание и внедрение объекта) — технология связывания и внедрения объектов в другие документы и объекты, разработанные корпорацией Майкрософт.
OLE позволяет передавать часть работы от одной программы редактирования к другой и возвращать результаты назад. Например, установленная на персональном компьютере издательская система может послать некий текст на обработку в текстовый редактор, либо некоторое изображение в редактор изображений с помощью OLE-технологии.
Проблемы, решаемые с помощью технологии COM
Термин "СОМ" представляет собой сокращение фразы Competent Object Model - компонентная объектная модель. Сутью данной технологии является то, что программы строятся из компонент, которые состоят из объектов. Само по себе это обстоятельство не является последней новостью в области программостроения - модульная архитектура и объектно-ориентированный подход к построению программ давно являются признанными стандартами de facto. Новостью является то, что является этими компонентами и объектами - ими является непосредственно исполняемый двоичный код. Не "включаемые исходные тексты" компилируемые совместно с проектом, не "библиотеки стандартных программ", присоединяемые линкером, а непосредственно исполняемые файлы, которые никак не надо "связывать" со своим проектом - их достаточно зарегистрировать в операционной системе и они будут доступны любой программе исполняющейся на данной машине. Т.е. их использование в своей программе производится "без использования операций сборки модуля".
Конечно, такая технология не является новой и называется "динамическая загрузка", она давно известна и её преимущества очевидны. А модули, которые позволяют загружать себя таким образом, называются DLL. И в системе, именуемой Microsoft Windows такая технология известна от самого её рождения... А DLL и есть тот самый "двоичный исполняемый модуль", который может быть присоединен к программе лишь на стадии её выполнения.
Однако, если просто весь проект распределить по нескольким динамическим библиотекам, то "двоичные компоненты" не получатся? Действительно, важнейший признак "компонентности" уже появится - исполняемую программу можно будет собирать из отдельных частей без операций сборки модуля. Но вот DLL - не компонента, DLL есть, если можно так выразиться, только "место обитания компонент" используемых в программе. Ведь из программы-то вызываются вполне конкретные процедуры и функции, которые только расположены в DLL. Кроме того, вызовы процедур "из своего модуля" и "из DLL" - не одинаковые действия. Вызов процедуры, которая располагается внутри "своего" модуля требует знания только имени этой процедуры, а если процедура располагается в DLL, то нужно знать ещё и имя самой библиотеки. Модель же COMпозволяет этого "не знать", т.е. вызов объектов COM из своей программы осуществляется без знания того, где они расположены. Достаточно знать имя объекта.
Другое отличие COM, уже от привычных объектов в стиле объектно-ориентированного программирования (ООП), состоит в том, что объекты ООП известны только компилятору. Это - абстракции, в которых мыслит программист и которые компилятор превращает в двоичные структуры "данные + код". Объекты ООП существующие в разных единицах компиляции и, тем более, помещенные в разные двоичные модули, ничего не могут друг о друге "знать" просто потому, что их там нет и никогда не было. Не случайно заголовочные файлы, содержащие описания всех объектов проекта, подаются на вход именно компилятора - потом они уже никому не нужны. Объекты же COM - действительно существуют в двоичном виде как объекты. И в таком качестве известны всем, кто испытывает в них нужду.
Технология COM есть технология, которая переносит все преимущества ООП, доступные программисту на уровне исходного текста, на двоичный уровень. Если в исходном тексте программист волен использовать "те" объекты и не использовать "эти", но теряет всяческий контроль над тем, что он делал, как только исходный текст был скомпилирован, то при использовании COM эти возможности сохраняются на протяжении всего жизненного цикла программы. Дополнительно к этому добавляются возможности разделения проекта на отдельные, повторноиспользуемые, и двоичные компоненты. Т.е., если в результате непосильного труда у программиста получается что-то хорошее и нужное, хотя бы частично, кому-то другому, то, оформив это в виде COM-сервера, он смело может это распространять, не рискуя что-то потерять - ведь контроль за исходным текстом остается у него. В то же время все пользователи этого объекта будут его использовать так же, как и свой, "родной", объект.
Идея экспорта объектов заключается в том, что один модуль создает объект, а другой его использует посредством обращения к методам (сервисам). Конечно, в экспорте простейших объектов обычно не возникает необходимости - любой программист может создать их в рамках одного приложения. Однако предположим, что где-то и кем-то был реализован достаточно сложный алгоритм распознавания текста в файле *.bmp, получаемом при сканировании документов. Конечно же, производители сканеров захотят предоставить дополнительные возможности покупателям и пожелают включить такое программное обеспечение и свой пакет. При этом любая фирма будет стараться свести к минимуму число приложений в своем пакете: по возможности все сервисы должны вызываться из одного приложения.
На первый взгляд эта проблема решается достаточно просто, по крайней мере когда в качестве другого модуля используется динамически загружаемая библиотека - DLL. В этом случае оба модуля содержатся в одном и том же адресном пространстве. Казалось бы, создадим в DLL объект, вызовем его методы из основного приложения - и данная задача решена. Однако это не так. Если использовать традиционное объектно-ориентированное программирование, то нельзя создать объект в одном модуле, а вызывать его методы в другом.
Вторая проблема возникает при обобщении первой проблемы. Соответственно программисту, использующему эту библиотеку, потребуется иметь под рукой документацию - список методов и список их формальных параметров. Их реализация "вручную" неизбежно приведет к ошибкам. Для исправления ошибок потребуется время, и при этом нет никакой гарантии, что все они будут обнаружены. Соответственно хотелось бы, чтобы сам объект мог информировать среду разработки о том, какие методы ему доступны и каковы списки их формальных параметров.
Этим не ограничиваются сложности работы с различными модулями. Например, если в одном из модулей была зарезервирована память для хранения данных, то в другом модуле нельзя ни освободить ее, ни изменить ее размер. Это связано с тем, что различные модули имеют разные менеджеры памяти. Если один модуль выделяет память, то в менеджере памяти другого модуля это никак не фиксируется. Для таких операций необходимо, чтобы был общий менеджер памяти.
Еще одна проблема возникает при обращении к объекту, созданному другим приложением. В этом случае указатель на объект в памяти, созданный в одном приложении, является недействительным для другого приложения. При передаче указателя из одного приложения в другое (это можно сделать, скопировав его в Clipboard или используя метод PostMessage), другое приложение будет обращаться совсем не к тем ячейкам оперативной памяти компьютера, где реально находятся данные. В лучшем случае сразу же произойдет исключение, в худшем - при попытке записи данных - будет разрушено ядро Windows. Эту проблему можно представить более глобально, если рассматривать возможность создания объекта на одном из компьютеров, а использовать его с помощью сети на другом.
Следующая проблема возникает при передаче данных от одного приложения к другому - например, через двоичный файл. Предположим, имеются два приложения - одно написано на языке Фортран, другое - на Delphi. И в Фортране, и в Delphi имеются двухбайтовые целочисленные переменные со знаком и динамическим диапазоном -32768+32767. На первый взгляд для передачи данных достаточно считать данные из двоичного файла, созданного одним приложением, в другое приложение. Но при выполнении такой операции можно обнаружить, что данные оказываются искаженными. Причина заключается в различном представлении переменных в этих двух языках программирования. В Delphi битовое представление числа -1 выглядит следующим образом: 1000000000000001, а в Фортране 1111111111111110 (not 1). Эту проблему можно сформулировать так: в различных языках программирования допускается различное представление одних и тех же данных. Соответственно они по-разному обрабатываются. При сложении двух целых чисел компилятор Delphi генерирует команду процессора ADD, а компилятор Фортрана - AND.
Можно выделить еще одну проблему, которая встречается в традиционном программировании. Взаимодействие двух приложений подразумевает, что они выполняются одновременно. Это означает, что одно из приложений должно запустить другое или потребовать у пользователя запуск другого приложения. Эта ситуация прекрасно наблюдается при использовании обмена данными с помощью протокола DDE (Dynamic Data Exchange). Пользователь обязательно должен запустить DDE-сервер вручную - иначе клиентское приложение не сможет работать. Это требует дополнительных операций и вызывает естественную негативную реакцию пользователя, что отрицательно сказывается на маркетинге приложений, являющихся клиентами DDE. Все эти проблемы решаются с помощью СОМ-технологии. Проблемы вызова методов объектов, освобождения и резервирования памяти, унифицированного представления данных решаются с помощью интерфейсов. Проблема предоставления среде разработки информации о названиях методов объектов и списков формальных параметров решается при помощи библиотек типов. Проблема передачи указателя из адресного пространства одного приложения в адресное пространство другого приложения решается с помощью маршрутизации. Маршалинг используется и для работы с объектами, созданными на других компьютерах. И наконец, проблему автоматического запуска сервера решает использование фабрики класса и ее регистрация в системном реестре.
COM-объект - это объект, который доступен так же, как и "локальный" объект данного проекта, хотя, фактически, он не располагается в данном проекте, а есть уже готовый двоичный исполняемый ресурс, который может располагаться где угодно. Обычно это - некая DLL. Суровая правда состоит в том, что объект COM может располагаться действительно где угодно. И DLL - не единственная форма его существования. COM-объект может жить и внутри EXE-модуля, который может исполняться независимо (параллельно!) от модуля, который использует этот объект, и даже - этот самый модуль может исполняться совсем на другом компьютере! Вы где-нибудь видели подобное? И зачем это нужно?
Начнем с ответа на второй вопрос. Зачем это нужно и, если нужно, насколько это важно? Представьте себе ситуацию - у вас есть хороший, славный, удачный алгоритм. Скажем, сортировка или "вычисление средней температуры по больничной палате". Вообще говоря, этот алгоритм появился не как самостоятельная сущность, а в процессе разработки какой-то большой программы мониторинга этой средней температуры. Заказ был именно на неё, и работать эта программа должна была на компьютере дежурной медсестры. Только вот в процессе работы над этой программой выяснилось, что существует и значительно реже используемая и совсем не первоочередная задача подсчёта всевозможнейшей статистики, которая, может быть, будет отдана вам на реализацию позднее. А может быть - и не будет отдана. Во всяком случае, такую возможность вы видите, и при подсчёте этой самой статистики вы будете использовать тот же алгоритм. Ваши возможные действия? Оформить библиотечной процедурой? Дело хорошее, но в расчёте той статистики используются не только ваша программа, но и программы других разработчиков. И они - мыслят так же. Сколько отдельных библиотек они создадут? Сколько при этом образуется независимых "единиц поддержки"? И как будет жить тот, кто в этих условиях будет писать статистику? Вот если бы у вас была возможность объявить свою, находящуюся не в библиотеке, а прямо в исполняемом модуле, процедуру доступной для вызова из другого исполняемого модуля, то вы бы убили сразу двух зайцев: 1) вам не нужно поддерживать два файла вместо одного; 2) вам не нужно как-то специально тестировать вашу библиотеку. Есть еще и третье обстоятельство - эту процедуру из вашего модуля "не выковырять", и, если у вас есть какие-то алгоритмы, составляющие ваше know how, то вам не нужно их помещать в значительно более беззащитную объектную библиотеку, которая, к тому же, может распространяться отдельно от вашего модуля. И - отдельно от вашего гордого имени тоже.
Вместо всего этого кошмара вы просто объявляете COM-объект, находящийся внутри вашего исполняемого модуля. Объявляете как его вызвать - и всё. Более того, если компьютер статистика соединен с компьютером медсестры сетью, то - то статистику даже не нужно иметь ваш модуль на своей машине - он сможет его запустить (и получить доступ к функциональности вашего COM-объекта) на машине медсестры со своей машины. Если вы с уважением относитесь к авторскому праву, то знаете, что программы не продаются (ввиду очевидной глупости такого подхода), а лицензируются для использования. Платить приходится, фактически, по числу процессоров, которые могут исполнять программу. Запуск на машине медсестры не нарушает лицензионного соглашения, а запуск второй копии на машине статистика - нарушает его. Эта особенность программы становится выгодной, если программа, содержащая не часто используемую функцию, стоит дорого. Конечно, для вас обстоятельство, понуждающее клиента купить вашу программу еще раз, - выгодно. Но, подумайте, были бы вы в том же лагере, если бы уже вы писали бы ту же статистику с использованием функций из чужих программ?
Кроме того, обратите внимание на вскользь упомянутое обстоятельство. Ваша программа запускается на процессоре медсестры по команде процессора статистика. Т.е. в какой-то момент времени используются мощности двух процессоров. А суммарная мощность... В общем, с использованием COM возможна и такая специфическая область деятельности, как написание распределенных приложений. Это - программные комплексы специальной архитектуры и конструкции, которые, примитивно говоря, состоят из независимо, но синхронизируемо выполняемых на разных процессорах модулей. А со стороны - производят впечатление согласованной одной программы.
В этом - пожалуй, самое большое преимущество COM. Вы знаете, что практически никогда не встречается случай, когда бы ваша программа в момент ее окончания была бы именно тем, что вы представляли себе, когда начинали ее писать. Изменения технического задания, переделки во внутренней конструкции, изменение требований заказчика - да мало ли что может произойти, почему вдруг вашей программе понадобилось стать другой. Если вы работаете над большим проектом, то в какой-то момент времени это становится проклятием - вы не можете изменить что-то без того, чтобы не "поплыло" что-то другое. Если же ваш проект делается как "грамотный COM", то фактически, вы разбиваете его на много согласованно работающих, но самостоятельных частей. Причем - несущественно, работают ли эти части на одной машине или на нескольких... Конечно, и здесь не все так просто, но переконфигурирование безусловно проще переписывания и последующего полнообъёмного тестирования. Что делает COM очень удобной архитектурной платформой для проектов, масштаб которых заранее не очень понятен и впоследствии может измениться.
Кроме того, поскольку сопрягаются двоичные объекты, - не все ли равно на каком языке эти объекты написаны?! Кроссплатформенная совместимость - бич Божий, кроме обмена примитивными типами и вызова примитивных процедур, как правило, двинуться не удается - не знает компилятор Pascal или Visual Basic как вызывать класс из модуля, написанного на C++. А что такое COM-объект - все они прекрасно знают. Более того, пользователи VB могут с удовлетворением отметить, что все идентификаторы, которые они с любовью разделяют в тексте точками, обозначая цепочечную ссылку, фактически являются COM-объектами. Т.е. для того, чтобы в обиход VB ввести "свой" объект его нужно сделать COM-объектом. И - всё.
COM - многообещающая и перспективная технология, находящаяся в русле общего направления развития программных технологий. С помощью COM можно разрабатывать программы и программные комплексы разного масштаба, функциональности и назначения. COM - социально-ориентированная технология, поскольку она защищает как права разработчика, так и кошельки пользователей...
Ну просто не может быть, чтобы в такой бочке мёда не было хотя бы маленькой ложки дёгтя! И дёготь действительно есть...
Во-первых, технология COM - сложная технология. Сложная как в концепции, так и в реализации. Она - намного сложнее, чем технология С++, реализуемая компилятором. Эта сложность не должна пугать - к настоящему времени разработано достаточное количество инструментов и средств разработки, которые позволяют "легко писать" и "легко использовать" COM-компоненты. Но эта сложность есть. На её преодоление тратятся ресурсы компьютера во время выполнения, а слабо понимающий концепции COM программист, несмотря на все эти редакторы, не сможет создать что-то приемлемо работающее, большее, чем примитивный пример. К счастью, это стандартная проблема - умение программировать есть не умение писать код, а только умение мыслить соответствующими категориями и конструкциями. И на VB можно написать плохо работающую программу, хотя на C++ сделать это значительно легче :). Никакая технология не в состоянии предложить приемлемого решения этой проблемы - технические средства могут только избавить от рутины, но не от необходимости думать и понимать.
Во-вторых, технология COM - замкнутая технология. Её решения применимы пока только на платформе Microsoft. Нельзя сказать, что другие платформы не предлагают ничего подобного, но это - другие, несовместимые на двоичном уровне с COM технологии.
В-третьих, технология COM - неполна. Неполна в том смысле, что она разрабатывалась "снизу", как средство "склеивания модулей в единую конструкцию". И до полноценного проектирования распределенных приложений она пока еще не добралась. Так что для тех, кого интересует действительно изначально кроссплатформенное распределённое приложение, больше подойдет технология CORBA, которая как раз для этих целей и разрабатывалась "сверху".
В-четвертых... давайте остановимся на этом. Всякое решение имеет область своего определения, вне пределов которой его использование становится попыткой воспользоваться ластами на заснеженном склоне. Технология COM - не исключение. С использованием этой технологии можно решить немало задач уровня настольного приложения или уровня локальной сети на платформе Microsoft. Это получается очень удобно и практично - все решения Microsoft так или иначе эту технологию поддерживают, поэтому появляется возможность их интеграции в собственное изделие. Но на платформе COM нельзя решить всех задач.
Кстати, нужно где-то сказать и о том, что COM имеет большое множество ассоциированных с собой аббревиатур, технологий и торговых марок. То, что мы сейчас называем COM в момент своего рождения называлось совсем по другому, OLE - Object Linking Embedding - встраивание и связывание объектов. (что, после небольшой стилистической правки, соответствующей русскому языку, вполне можно перевести как ПиВО - привязывание и встраивание объектов)
"Чистая OLE" породила технологию OLE Automation - автоматизацию, а затем из OLE концептуально выкристаллизовалась технология самого нижнего уровня - COM. После этого Microsoft переименовала OLE в ActiveX и заявила, что COM является не частью OLE, а самостоятельной платформой. Платформой, на которой и располагаются все другие "компонентные" технологии. Поэтому ActiveX является производной технологией, выстроенной на платформе COM. От перемены названия суть технологий (да и большая часть кода) не изменилась - ActiveX и OLE являются преемственными технологиями, а OLE Automation вообще осталась почти в первозданном виде.
Нужно так же сказать, что долгое время OLE/COM существовала только в пределах одной машины. Но в какой-то момент времени появилась (весьма для компонентной технологии естественная) возможность разместить клиент и сервер на разных машинах в пределах одной сети. Чтобы подчеркнуть прорывность этого шага Microsoft особо выделила и название DCOM - Distributed COM. Ныне оно уже не актуально - в состав любой современной операционной системы Microsoft входят системные средства, поддерживающие что локальное, что распределённое создание объектов (ранее это был только option pack).
Впоследствии Microsoft разработала на платформе COM набор интерфейсов для доступа к базам данных и опубликовала его под названием OLE DB, а также предложила платформу промежуточного уровня Transaction Server - MTS. При разработке операционной системы Windows 2000 (NT 5.0) средства MTS были встроены в систему (ранее это был только option pack), и результирующая платформа получила название COM+. Это многообразие не должно сбивать с толку, все эти наименования относятся к одной и той же области понятий, база которой - COM.
Что нужно, чтобы уверенно понимать о чем дальше пойдет речь? Нуно знание некоторых базовых концепций программирования. Во-первых, следует хорошо представлять себе понятия "процесс", "поток" и "адресное пространство", а также концепцию мультизадачности в операционной системе. Весьма желательно знать, как именно загружается DLL и создаётся новый процесс в системе. Требуется в какой-то достаточной мере знать концепции объектно-ориентированного программирования, а для абсолютно прозрачного понимания механизмов технологии COM на нижнем уровне совершенно необходимо неплохо представлять себе конструкции, которые строит компилятор C++ в объектном коде. Во-вторых, требуется довольно четкое представление, что есть вычислительная сеть - хотя бы на уровне локальной сети, и представление каким образом компьютеры взаимодействуют друг с другом. В-третьих - требуется понимать концепцию архитектуры "клиент-сервер".
Начнем с концепции "клиент-сервер". Это словосочетание с некоторых пор стало привычным и связалось с контекстом доступа к базам данных. Точнее, "для широкой публики" оно стало означать "клиент - сервер базы данных". Хотя на самом деле - это совсем не так. Концепция "клиент-сервер" значительно мощнее, чем принято об этом думать. Идея концепции исходит из понятия "сервиса" - некоторого действия, совершить которое зачем-то требуется стороне A и которое она сама выполнять не умеет. Зато стороне B совершение этого действия не нужно, но как раз она-то и умеет его совершать. В таком случае сторона A каким-то образом вынуждает сторону B совершить это действие и предоставить стороне А результат. В таком взаимодействии сторона, которая умеет совершать действие, но не имеет никакой инициативы его совершения называется "сервером", а сторона, которая состоит только из инициативы - называется "клиентом". В этом взаимодействии "клиент" запрашивает, а "сервер" предоставляет "сервис".
Многие привычные случаи программного взаимодействия можно переосмыслить под этим углом, например внутри обычной программы "вызывающая процедура" очевидно является клиентом, а "вызываемая" - сервером. Просто о них не принято думать в таких терминах, хотя ничего некорректного в этом нет. И во взаимодействии каких либо машин, программ, объектов, когда один запрашивает у другого совершить какое-либо действие запрашивающий - всегда клиент, а исполняющий - всегда сервер.
Понятия клиента и сервера - динамические понятия. В диалоге объектов, т.е. когда они вызывают друг-друга попеременно, в разном взаимодействии каждый из них попеременно будет и клиентом и сервером - термин никоим образом не означает иной специализации, чем это требуется для самого взаимодействия.
Понятия "адресного пространства", "процесса", "потока" для тех, кто программирует на C/C++ являются одними из фундаментальных. Для программистов на VB можно сказать следующее.
Программу исполняет процессор - физическое устройство, которое одну за одной, как они записаны в программе, исполняет команды. Для программиста, который мыслит безлично (для него просто "программа исполняется") понятия процессора нет. Для него есть понятие "поток передачи управления", т.е. последовательность прохождения команд программы. Но поток и есть не что иное, как "внимание процессора", который выполняет последовательность команд программы. Дело в том, что в машине может быть более одного процессора, тогда, либо одна программа могла бы выполняться в несколько потоков, либо одновременно машина могла бы выполнять несколько программ. Последовательность выполнения команд нарушать нельзя, поэтому конечно дело не происходит так, что один процессор выполняет "только чётные", а другой - "только нечётные" строки программы. Для возможности выполняться более, чем в одном потоке, программа должна быть специально сконструирована! А вот две независимые программы каждую на своем процессоре - выполнить можно, каждая из них будет выполняться в своем потоке и ничего не знать о других.
Процессом традиционно называют совокупность всех ресурсов компьютера, отданных операционной системой для выполнения программы. Эти ресурсы включают в себя внимание процессора, память, объекты операционной системы и т.д. - важно понимать, что процесс это не только текст исполняющейся программы, но и всё, что она для своего исполнения требует. Понятно, что внутри процесса есть хотя бы один поток. Когда системе предлагают программу "запустить на исполнение" она создает один процесс и один поток в котором и запускает программу.
Эффекта наличия в системе нескольких процессоров можно достичь и не имея их физически, а просто переключая время от времени программы, исполняющиеся на процессоре. Если квант времени, в течение которого процессор занят одной программой, не очень велик, то будет создаваться иллюзия, что все программы исполняются системой одновременно. В этом - суть мультизадачности операционной системы. Точное положение вещей состоит, конечно, в том, что операционная система переключает на процессоре не программы, а - потоки, как вы теперь понимаете.
Ну и наконец, программа для своего исполнения требует памяти. Совокупность всех доступных для программы адресов памяти называется адресное пространство. В ранних системах каждому адресу соответствовал байт реальной памяти, поэтому надобности в такой абстракции не возникало - говорили просто "память". В современных системах это далеко не так и реальной памяти программа имеет куда меньше, чем диапазон доступных ей адресов. Почему и появилось такое понятие. Более того, в современных системах память устроена так, что по одному и тому же адресу памяти доступному из программы, расположены разные байты физической памяти разных процессов. Т.е. абсолютно физически невозможно одному процессу залезть в память другого процесса - по какому бы адресу он ни обращался, везде будет "его собственная" память.
Объект - это абстракция прямо отражающаяся в окружающей реальности. У любой сущности видимого мира есть состояние и поведение. В computer sciences состояние описывается данными, а поведение - процедурами. Объединив оба понятия в одну сущность получим объект - классика, начиная уже со времен Страуструпа! Является теоремой, но сейчас доказывать уже не нужно - любая программа может быть сконструирована как совокупность взаимодействующих объектов. Вот и посмотрим, как бы могли между собой взаимодействовать части такой единой программы. Соответствующая конфигурация показана на рисунке:
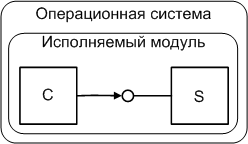
Конфигурация модуля, сконструированного в ООП
Здесь имеется два взаимодействующих объекта C и S которые располагаются в одном исполняемом модуле, а модуль, в свою очередь, располагается в среде операционной системы. Расположение в одном модуле позволяет им "по рождению" знать друг о друге все, что знал о них компилятор. Также, здесь и ниже под термином "взаимодействие С и S" мы имеем в виду, что C получил ссылку на S и вызывает его метод.
Разделим модуль, изображённый на рис.1 на два модуля, так чтобы в каждом оказалось по одному объекту. Этим мы разорвем их взаимодействие, но не уничтожим способность объектов взаимодействовать друг с другом - ведь сами-то объекты не изменились. Сделать это можно, если один из объектов поместить в DLL, а второй оставить в EXE. Получим конфигурацию, изображённую на рисунке:
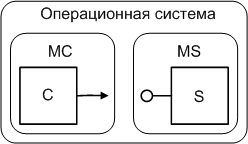
Конфигурация разделенных модулей
Рассмотрим возможный сценарий такого взаимодействия. Сразу оговоримся - сценарий "загрузки DLL по требованию" здесь невозможен - модуль MC ничего не знает о модуле MS. Это мы их наименовали так только для нашего рассмотрения. Очевидно так же, что модуль MC - загружен в память и выполняется, а иначе как бы объект C мог проявлять свои желания?
Итак, объект C имеет твёрдое намерение взаимодействовать с объектом S, а объект S - такого желания совершенно не испытывает и ведет себя пассивно: разыщут - исполнит. Более того, вообще говоря, С и вовсе неизвестно - есть ли "в живых" этот самый объект S. Пока они оба "жили" в одном модуле этой проблемы не было вовсе - и адресное пространство было одно и ссылки на объект из "своего" модуля создавались еще компилятором. А сейчас... сейчас объект С знает только, что где-то в природе должен существовать объект S и хочет его достать.
Что должен делать объект C? Что он вообще может сделать? Разумно предположить, что первое обращение последует от C к операционной системе - "я знаю, что в твоих недрах есть объект S, прошу выдать мне ссылку на него". Система в таком случае должна как-то вести учёт своего "объектного поголовья" и иметь средства отличать одни объекты от других. Без этой способности запросы такого рода не выполнить. Адрес, как характеристика объекта, здесь неприменим - адрес памяти известен только для заведомо существующих объектов, а C даже про существование S ничего не знает. Кроме того, система должна также знать, что объект S "живет" именно в модуле MS, а этот модуль - располагается во вполне определенном каталоге файловой системы. О том, какие модули составляют процесс, система знает и так.
Система, получив такой запрос из определенного процесса, должна просмотреть свой список "имя объекта - имя модуля", отыскать по имени объекта модуль, в котором тот обитает. После этого система, видимо, должна проверить - а есть ли такой модуль в числе составляющих процесс. Если такого модуля нет, то система его должна в этот процесс загрузить...
Как "сделать объект S" система, конечно, могла бы знать. Но - сколько модулей, столько и мнений, и - все их помнить? Поэтому гораздо разумнее, если система не будет пытаться что-то сделать сама, а совершенно стандартным образом запросит модуль MS - "выдать ссылку на объект S". Тут появляется уже некоторая возможность волюнтаризма со стороны модуля MS - система-то просила у него только ссылку. Как получается эта ссылка - создает ли модуль новый объект S всякий раз, как его запрашивают, имеет ли он объект S один на всех и всем выдает одну и ту же ссылку - дело модуля MS, а не системы.
Модуль MS "проворачивается" - он "делает объект S" в памяти, получает его адрес и возвращает этот адрес системе - "получите, что просили". Система же, зная, от кого поступил запрос, возвращает адрес тому, кто вызывал - объекту C. Поскольку объекты C и S раньше жили в одном модуле, то, как вызывать методы объекта S объект C знает! А ссылку он получил... Взаимодействие - состоялось.
Обратим внимание вот на что - в этом, нестрого изложенном сценарии взаимодействия, точно обозначены механизмы и понятия, необходимые, чтобы объекты, заведомо всё знающие о взаимодействии друг с другом могли "друг друга повстречать". Более того, эти механизмы и нужны только лишь для того, чтобы можно было "обеспечить встречу" - как взаимодействовать объекты и сами знают. И вот эту инфраструктуру мы изучим подробнее, поскольку "вызов метода по ссылке на объект" - совершенно стандартная возможность, предоставляемая любым языком программирования.
Итак, сценарий возможного взаимодействия объектов С и S потребовал некоторых специальных ресурсов:
1. Все потенциально доступные объекты должны быть уникально поименованы в системе, чтобы можно было отличать один объект от другого
2. Система должна знать, в каком исполняемом модуле "обитает" объект, так, чтобы по имени объекта можно было запустить модуль, его реализующий.
3. В системе должна быть специальная, доступная всем желающим функция "дать адрес "живого" объекта по его имени" и эта функция должна делать сравнительно много работы!
4. Исполняемые модули, реализующие объекты должны иметь особый "стандартный вход", посредством которого от операционной системы они будут получать запросы на создание объектов, ими реализуемых.
5. Объекты должны заранее знать, каким образом они взаимодействуют между собой - система не вмешивается в этот процесс.
Поскольку изложенный сценарий от реального сценария взаимодействия объектов COM отличается только в мелких деталях, рассмотрим эти этапы подробнее.
Прежде всего, отметим себе, что описанная последовательность действий возникает вследствие одного-единственного обстоятельства - мы захотели, чтобы объекты, которые находятся в физически разных, заранее неизвестно - в каких, модулях, взаимодействовали друг с другом так, как будто бы они находятся в едином модуле. В этом смысле требования к протоколу их взаимодействия - философские требования. Они не зависят ни от платформы, на которой реализуются, ни от программы, которая использует такие объекты. Иными словами - всякая программа/платформа, которая захочет поддержать взаимодействие объектов в физически разных модулях как если бы они были в модуле одном - должна будет выполнить эти действия.
Вот и вопрос - не дорого ли это? Этот вопрос часто задают программисты, для которых COM - ещё одна новая среди множества уже известных им технологий. Раньше они просто описывали объекты, строили их экземпляры используя оператор new, передавали указатели-ссылки между ними и не имели дополнительных хлопот. Ради чего все это?
На этот конкретный вопрос существует и не менее конкретный ответ, правда ответ этот лежит немного в стороне от "чистого программирования". COM-технология позволяет повторно использовать "абсолютный код", код для которого все затраты - уже в прошлом. Если вы распространяете библиотеку объектных модулей вам требуется программирование, сборка, распространение новой версии всего программного продукта в целом… да еще не одного продукта, а - всех, которые используют новую версию объектной библиотеки. А вот если у вас есть двоичные компоненты, то все эти проблемы на стороне пользователя вашего продукта исчезают. Вы просто предоставляете новую версию компоненты, которую только копируете и регистрируете в системе.
Конечно, соблюдение протокола COM - дополнительные затраты. И затраты программиста по написанию дополнительного кода для соблюдения протокола и затраты процессора по исполнению и этого и системного кода. Но ведь помимо "тактов процессора" существуют другие единицы измерения затрат, в частности - рубли, доллары, евро... Поскольку при индустриальном способе производства программ справедлив лозунг "написано однажды - работает везде", то оказывается, что затраты на собственно создание программы не идут ни в какое сравнение с затратами на её распространение и поддержку её функционирования у пользователя. Процессоры сейчас мощные, стоимость их такта невелика, а зарплата что менеджера по продажам, что инженера по сопровождению - существенно больше. Поэтому сокращение затрат на стороне пользователя, пусть даже ценой бОльших затрат ресурсов машины и программиста-создателя, - экономически оправданно.
Это иногда трудно понять программистам-разработчикам, которые сосредоточены на именно программировании. Однако это очень хорошо понимает пользователь, который понятия не имеет сколько стоит разработка программы, но который считает свои деньги, те, что тратит на покупку (содержание команды программистов) и сопровождение работы своего экземпляра программы. Бывает, что это трудно понять не только новичкам, но и опытным программистам - затраты на реализацию COM-обрамления к проекту, порой, достигают половины его размера (в виде исходных текстов и времени программирования). Вот только всякий проект COM - конечен по определению, в то время как "не COM-проект" может расширяться до бесконечности, до бесконечности же поглощая время программиста на его сопровождение и поддержание.
К счастью, многие проблемы разряда "написания служебного кода COM" в современных средствах разработки успешно решены, поэтому это замечание теперь больше курьёз, но и оно периодически возникает. И даже несмотря на то, что средства разработки COM-компонентов скрывают детали реализации, что их теперь не нужно "писать руками", для успешного и уверенного использования COM философию взаимодействия, детали, реализующие COM, их взаимную связь нужно знать очень хорошо.