Производительность процессоров и архитектурные способы
её повышения
Производительность является одной из наиболее важных характеристик процессора. Согласно /1/, в общем случае она определяется количеством вычислительной работы, выполняемой в единицу времени. К важнейшим факторам, влияющим на производительность, относятся тактовая частота, число команд программы, среднее время выполнения отдельной команды. Для упрощённой оценки производительности процессора часто используют показатель, указывающий число команд, выполняемых за секунду КС (команд за секунду). КС определяется как частное от деления тактовой частоты на среднее время выполнения процессором отдельной команды и измеряется в MIPS (Meg Insruction Per Second) для целочисленных задач и MFLOPS (Meg Floating Point Operations Per Second) для вычислений с плавающей точкой. При этом оценки показателя КС проводят для операций с регистровыми операндами, не привязываясь к быстродействию основной памяти. Однако показатель КС не учитывает особенности архитектуры конкретных процессоров. Поэтому для сравнительных характеристик различных процессоров используются относительные оценки производительности, для получения которых используются специальные тестовые программы.
В соответствии с /1/, повышение производительности процессоров в большинстве случаев достигается за счёт применения специальных технологических и архитектурных решений. Технологические подходы (совершенствование технологий производства ИС, увеличение степени интеграции) были рассмотрены ранее, во второй лекции. Поэтому подробнее остановимся на архитектурных способах повышения производительности процессоров. Совершенствование архитектуры процессоров, обеспечивающее повышение его производительности, в настоящее время связано, прежде всего, с развитием средств параллельной обработки данных. Здесь можно выделить следующие направления:
1) Увеличение «естественного» параллелизма – повышение разрядности обработки и передачи данных (разрядность процессоров повысилась с 4 до 32 и 64 разрядов).
2) Конвейерная (многофазная) обработка данных – вычислительный процесс делится на несколько фаз, для каждой из которых используются свои средства и буфер для хранения результата (ступень конвейера).
3) Многоэлементная обработка данных - параллельная обработка данных в нескольких операционных блоках (ОУ) процессора.
Способы параллельной обработки могут сочетаться. Например, в одном процессоре можно организовать несколько операционных блоков, в каждом из которых использовать конвейеризацию.
Рассмотрим более детально два последних направления.
При многофазной обработке, как показано на рисунке 4.3, процесс обработки данных разбивается на несколько стадий (фаз), выполняемых последовательно.

Рисунок 4.3 – Многофазная обработка данных
Между фазами имеются буферы для хранения промежуточных результатов. После выполнения первой фазы результат запоминается в буфере и начинается обработка второй фазы. Средства выполнения первой фазы освобождаются, и на них поступает следующая порция данных. Если длительность фаз обработки одинакова и составляет T/n, то при таком способе производительность системы увеличится в n раз. Этот способ соответствует конвейерной обработке.
Рассмотрим организацию конвейера на уровне исполнения машинной команды /1/. Каждый блок в конвейерной цепочке осуществляет только один этап исполнения команды. Полная обработка команды занимает несколько тактов.
Типовые этапы выполнения команды: 1) выборка команды IF (Instruction Fetch), 2) дешифрация команды ID (Instruction Decode), 3) чтение операндов RD (Read Memory), 4) исполнение заданной в команде операции EX (Execute), 5) запись результата WB (Write Back). В ходе выполнения команда продвигается по конвейеру, освобождая очередную ступень для следующей команды. Содержимое буферов, которые используются для хранения информации, передаваемой по ступеням конвейера, обновляется в каждом такте по завершению этапа исполнения очередной команды. Промежуточные буферы обеспечивают параллельную независимую работу блоков конвейерной цепочки: в то время, когда последующий блок начинает выполнять этап очередной команды, предыдущий блок может приступать к обработке следующей команды, что демонстрирует рисунок 4.4.
| Такты работы процессора | ||||||||||
| Команда i | IF | ID | RD | EX | WB | |||||
| Команда i+1 | IF | ID | RD | EX | WB | |||||
| Команда i+2 | IF | ID | RD | EX | WB | |||||
| Команда i+3 | IF | ID | RD | EX | WB | |||||
| Команда i+4 | IF | ID | RD | EX | WB | |||||
| Команда i+5 | IF | ID | RD | EX | WB |
Рисунок 4.4 – Конвейерная обработка команд
Следует отметить, что конвейерная обработка команд не уменьшает время выполнения отдельной команды, которое в конвейерном процессоре остаётся таким же, как и в обычном неконвейерном. Однако благодаря тому, что при конвейерной обработке большая часть вычислительного процесса в режиме одновременного выполнения команд, скорость выдачи результатов последовательно выполняемых команд увеличивается пропорционально числу ступеней конвейера. Продолжительность выполнения отдельных этапов исполнения команды в общем случае зависит от типа команды и места размещения операндов. Конвейерная обработка команд наиболее эффективна в том случае, если длительность всех фаз выполнения команды приблизительно одинаковая. К сожалению, обеспечить непрерывную работу конвейера не всегда удаётся из-за различных конфликтов: по ресурсам, по данным, по управлению. Более подробно о конфликтах – в /1/.
Процессор, в котором процесс выполнения команды разбивается на 5-6 ступеней, называется обычным конвейерным процессором. Если увеличить количество ступеней конвейера, то каждая отдельная ступень будет выполнять меньшую работу, а, следовательно, содержать меньше аппаратной логики. Благодаря более коротким задержкам распространения сигналов в каждой отдельно взятой ступени конвейера достигается повышение частоты работы и соответствующее повышение производительности процессора. Процессор, имеющий конвейер существенно глубже 5-6 ступеней, называется суперконвейерным. Например, Pentium II содержит 12 ступеней, UltraSPARC III – 14 ступеней, Pentium 4 – 20 ступеней.
Как показано на рисунке 4.5 /1/, многоэлементная обработка осуществляется на нескольких параллельно работающих ОУ. Каждый элемент выполняет свою работу, осуществляя обработку порции данных от начала до конца.
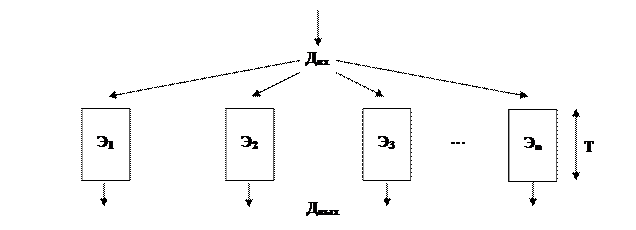
Рисунок 4.5 – Многоэлементная параллельная обработка данных
Если время выполнения работы на отдельном элементе составляет T и в системе используется n элементов, то при определённой идеализации можно ожидать, что среднее время выполнения такой работы составит T/n (реально - меньше). В современных процессорах такой способ обработки связан с понятием суперскалярной архитектуры.
Простейшим примером вычислительного параллелизма является выполнение двух команд, операнды которых не связаны между собой:
A = B + C; D = E + F.
Поэтому обе команды можно выполнять одновременно. Для выполнения несвязанных операций в состав процессора включают набор арифметических устройств, каждое из которых обычно имеет конвейерную организацию.
Процессор, содержащий несколько ОУ, которые обеспечивает одновременное выполнение более одной скалярной команды, называется суперскалярным процессором. Команда называется скалярной, если её входные операнды и результат являются числами (скалярами). Традиционные процессоры с одним ОУ называются скалярными. В суперскалярном процессоре обработка команд распараллелена не только во времени (конвейер), но и в пространстве (несколько конвейеров). Производительность такого процессора оценивается темпом схода исполненных команд со всех его конвейеров.
В настоящее время используются два способа суперскалярной обработки. Первый способ базируется на чисто аппаратном механизме выборки несвязанных команд программы из памяти (кэш-памяти, буфера предвыборки) и параллельном запуске их на исполнение. Ответственность за эффективность загрузки параллельно функционирующих конвейеров возлагается на аппаратные средства процессора, что является основным достоинством этого способа суперскалярной обработки. В этом случае процесс трансляции программ для суперскалярного процессора ничем не отличается от трансляции программ для традиционного скалярного процессора. В соответствии с этим способом, сравнительно легко реализуются суперскалярные микропроцессоры различных семейств программно совместимые между собой. При этом не возникает проблем с использованием ранее созданного программного обеспечения. Все процессоры семейства Pentium реализованы по этому способу.
В процессорах, реализующих второй способ суперскалярной обработки, планирование параллельного исполнения нескольких команд возлагается на распараллеливающий компилятор. Сначала он анализирует исходную программу в целях выявления команд, которые могут выполняться одновременно. Затем компилятор группирует такие команды в пакеты команд – длинные командные слова (VLIW), причём, число простых команд в команде VLIW принимается равным числу исполнительных блоков процессора. Поскольку всю работу по подготовке к исполнению VLIW-команд выполняет компилятор, конфликтные ситуации при их исполнении исключаются. Такой способ суперскалярной обработки реализуется в VLIW-процессорах, имеющих статическую сперскалярную архитектуру. К сожалению, для таких процессоров требуется специальное программное обеспечение. Кроме того, программы, скомпилированные для одного поколения микропроцессоров, могут выполняться неэффективно без перекомпиляции на процессорах следующего поколения. Это требует от разработчиков программного обеспечения разработки модифицированных версий исполняемых файлов своего продукта для разных поколений процессоров. Идеи VLIW предложены российскими инженерами и учёными во главе с профессором Б.А. Бабаяном при разработке отечественной супер-ЭВМ «Эльбрус-3» (1990). В настоящее время VLIW-технология реализована в процессоре Эльбрус Е2К отечественной компании «Эльбрус Интернешнл», процессорах Crusoe фирмы Transmeta, а также в семействе сигнальных процессоров (для цифровой обработки сигналов) TMS320C60xx фирмы Texas Instruments.
Далее рассмотрим вопросы, посвящённые организации работы процессоров и их взаимодействия с другими устройствами вы числительных машин.