Обобщенная передача данных от одного процессора всем остальным процессорам сети
Общий случай передачи данных от одного процессора всем остальным процессорам сети состоит в том, что все рассылаемые сообщения являются различными (one-to-all personalized communication или single-node scatter). Двойственная операция передачи для данного типа взаимодействия процессоров – обобщенный прием сообщений (single-node gather) на одном процессоре от всех остальных процессоров сети (отличие данной операции от ранее рассмотренной процедуры сборки данных на одном процессоре состоит в том, что обобщенная операция сборки не предполагает какого-либо взаимодействия сообщений (например, редукции) в процессе передачи данных).
Трудоемкость операции обобщенной рассылки сопоставима со сложностью выполнения процедуры множественной передачи данных. Процессор – инициатор рассылки посылает каждому процессору сети сообщение размера m, и, тем самым, нижняя оценка длительности выполнения операции характеризуется величиной mtk(p–1).
Проведем более подробный анализ трудоемкости обобщенной рассылки для случая топологии типа гиперкуб. Возможный способ выполнения операции состоит в следующем. Процессор – инициатор рассылки передает половину своих сообщений одному из своих соседей (например, по первой размерности) – в результате исходный гиперкуб становится разделенным на два гиперкуба половинного размера, в каждом из которых содержится ровно половина исходных данных. Далее, действия по рассылке сообщений могут быть повторены, и общее количество повторений определяется исходной размерностью гиперкуба. Длительность операции обобщенной рассылки может быть охарактеризована соотношением:
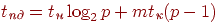
| (3.14) |
(как и отмечалась выше, трудоемкость операции совпадает с длительностью выполнения процедуры множественной рассылки).