Алгоритми і протоколи маршрутизації
Тема 4. Маршрутизація трафіку в ОС FreeBSD
Література
1. Стивенс У., UNIX: Разработка сетевых приложений. – СПб.: Питер, 2004. – 880 с.
2. W. R. Stevens, S. A. Rago, Advanced Programming in the UNIX® Environment: Second Edition, Addison Wesley Professional, 2005. – 720 с.
3. Мельник В.М., Стешенко Л.І. Основи операційної системи UNIX / Луцьк. – 2012. – 280 с.
4. Рочкинд М. Программирование для UNIX. 2-е изд. и перераб. и доп. – Пер. с англ. – СПб.; БХВ-Петербург, 2005. – 704 с.: ил.
5. Олифер В. Г., Олифер Н. А. Компьютерные сети. Принципы, технологии, протоколы: Учебник для вузов = Computer Networks. Principles, Technologies and Protocols for Network Design. – 3-е изд. – СПб.: Издательский дом «Питер», 2006. – С. 572-576. – 958 с. – ISBN 5-469-00504-6
Протокол маршрутизації – мережевий протокол, який використовується маршрутизаторами для визначення можливих маршрутів прямування даних в комп'ютерній мережі. Застосування протоколу маршрутизації дозволяє уникнути ручного введення всіх допустимих маршрутів, що, у свою чергу, знижує кількість помилок, забезпечує узгодженість дій усіх маршрутизаторів в мережі і полегшує працю адміністраторів.
Протоколи маршрутизації діляться на два види, що залежать від типів алгоритмів, на яких вони засновані (або можуть бути гібридними – поєднувати обидва підходи):
- Дистанційно-векторні протоколи, засновані на Distance Vector Algorithm (DVA);
- Протоколи стану каналу зв'язку, засновані на Link State Algorithm (LSA).
Так само протоколи маршрутизації діляться на два види залежно від сфери застосування:
- Міждоменна маршрутизація;
- Внутрішньодоменна маршрутизація.
Більшість протоколів маршрутизації, які застосовуються у сучасних мережах з комутацією пакетів, ведуть своє походження від мережі Інтернет і її попередниці – мережі ARPANET. Для того щоб зрозуміти їхнє призначення й особливості, корисно спочатку познайомитися зі структурою мережі Інтернет, що наклала відбиток на термінологію й типи протоколів.
Інтернет споконвічно будувалася як мережа, що поєднує велику кількість існуючих систем. Із самого початку в її структурі виділяли магістральну мережу (core backbone network), а мережі, приєднані до магістралі, розглядалися як автономні системи (autonomous systems, AS). Магістральна мережа й кожна з автономних систем мали своє власне адміністративне управління й власні протоколи маршрутизації. Необхідно підкреслити, що автономна система й домен імен Інтернет – це різні поняття, які служать різним цілям. Автономна система поєднує мережі, у яких під загальним адміністративним керівництвом однієї організації здійснюється маршрутизація, а домен об'єднує комп'ютери (які, можливо, належать різним мережам), у яких під загальним адміністративним керівництвом однієї організації здійснюється призначення унікальних символьних імен. Природно, області дії автономної системи й домена імен можуть в окремому випадку збігатися, якщо одна організація виконує обидві указані функції.
Загальна схема архітектури мережі Інтернет показана на рисунку 4.1. Далі маршрутизатори ми будемо називати шлюзами, щоб залишатися в руслі традиційної термінології Інтернет.
Шлюзи, які використовуються для утворення мереж і підмереж усередині автономної системи, називаються внутрішніми шлюзами (interior gateways), а шлюзи, за допомогою яких автономні системи приєднуються до магістралі мережі, називаються зовнішніми шлюзами (exteriorgateways). Магістраль мережі також є автономною системою. Всі автономні системи мають унікальний 16-розрядний номер, що виділяється організацією, яка заснувала нову автономну систему, InterNIC.
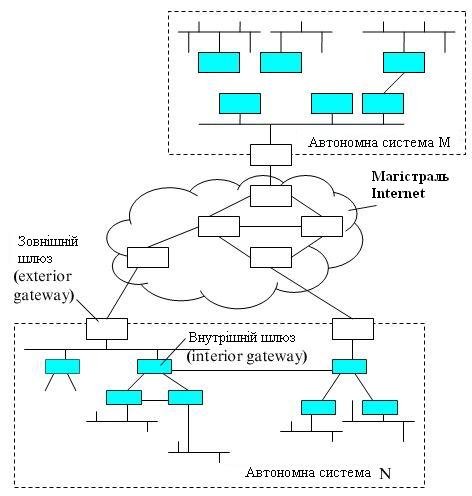
Рисунок 4.1 – Магістраль і автономні системи Інтернет
Відповідно протоколи маршрутизації усередині автономних систем називаються протоколами внутрішніх шлюзів (interior gateway protocol, IGP), а протоколи, що визначають обмін маршрутною інформацією між зовнішніми шлюзами й шлюзами магістральної мережі – протоколами зовнішніх шлюзів (exterior gateway protocol, EGP). Усередині магістральної мережі також допустимо будь-який власний внутрішній протокол IGP.
Смисл розподілу всієї мережі Інтернет на автономні системи – у її багаторівневому модульному представленні, що необхідно для будь-якої великої системи, здатної до розширення в великих масштабах. Зміна протоколів маршрутизації усередині якої-небудь автономної системи ніяк не повинна впливати на роботу інших автономних систем. Крім того, розподіл Інтернет на автономні системи повинен сприяти агрегуванню інформації в магістральних і зовнішніх шлюзах. Внутрішні шлюзи можуть використовуватися для внутрішньої маршрутизації досить докладні графи зв'язків між собою, щоб вибрати найбільш раціональний маршрут. Однак якщо інформація такого ступеня деталізації буде зберігатися у всіх маршрутизаторах мережі, то топологічні бази даних так розростуться, що зажадають наявності пам'яті гігантських розмірів, а час прийняття рішень маршрутизації стане неприйнятно великим.
Тому детальна топологічна інформація залишається усередині автономної системи, а автономну систему як єдине ціле для іншої частини Інтернет представляють зовнішні шлюзи, які повідомляють про внутрішній склад автономної системи мінімально необхідні відомості – кількість IP-мереж, їхні адреси й внутрішню відстань до цих мереж від даного зовнішнього шлюзу.
Техніка безкласової маршрутизації CIDR може значно скоротити обсяги маршрутної інформації, що передається між автономними системами. Так, якщо всі мережі усередині деякої автономної системи починаються із спільного префікса, наприклад 194.27.0.0/16, то зовнішній шлюз цієї автономної системи повинен робити оголошення тільки про цю адресу, не повідомляючи окремо про існування усередині даної автономної системи, наприклад, мережі 194.27.32.0/19 або 194.27.40.0/21, тому що ці адреси агрегуються на адресу 194.27.0.0/16.
Наведена на рисунку 4.1 структура Інтернет з єдиною магістраллю досить довго відповідала дійсності, тому спеціально для неї був розроблений протокол обміну маршрутної інформації між автономними системами, що називається EGP. Однак у міру розвитку мереж постачальників послуг структура Інтернет стала набагато більш складною, з довільним характером зв'язків між автономними системами. Тому протокол EGP поступився місцем протоколу BGP, що дозволяє розпізнати наявність петель між автономними системами й виключити їх з міжсистемних маршрутів. Протоколи EGP і BGP використовуються тільки в зовнішніх шлюзах автономних систем, які найчастіше організуються постачальниками послуг Інтернет. У маршрутизаторах корпоративних мереж працюють внутрішні протоколи маршрутизації, такі як RIP і OSPF.
Розглянемо протоколи внутрішньої маршрутизації:
Протокол GGP (Gateway to Gateway Protocol, RFC 823) був розроблений і реалізований фірмою BBN для перших експериментальних шлюзів мережі Інтернет. Він до цих пір використовується в шлюзах фірми BBN LSI/11, хоча вважається, що GGP має серйозні недоліки і пізніше був замінений на алгоритм SPF. Алгоритм протоколу GGP визначає маршрут з мінімальним числом маршрутизаторів, тобто його мірою довжини є просто число транзитних ділянок мережі між парами шлюзів. Він реалізує розподілений алгоритм найкоротшого шляху, який вимагає глобальної збіжності маршрутних таблиць після змін в топології або зв'язності.
Протокол RIP (Routing Information Protocol, RFC 1058, 1581, 1582, 1724) часто використовується для класу протоколів маршрутизації, що базуються на протоколах XNS (Xerox Network System – мережева система Xerox) фірми Xerox. Реалізація протоколу RIP для сімейства протоколів TCP/IP широко доступна, оскільки входить до складу програмного забезпечення ОС UNIX, наприклад, FreeBSD або Linux. В силу своєї простоти протокол RIP має найбільші шанси перетворитися на «відкритий» протокол IGP, тобто протокол, який може використовуватися для спільної роботи шлюзів, що поставляються різними фірмами. При використанні протоколу RIP працює алгоритм динамічного програмування Беллмана-Форда. В якості метрики маршрутизації RIP використовує число стрибків (кроків) до мети. Такий вид метрики не враховує відмінностей у пропускної здатності чи завантаженості окремих сегментів мережі. Кожному маршруту ставиться у відповідність таймер тайм-ауту і «збирач сміття». Таймер тайм-ауту скидається кожен раз, коли маршрут ініціалізується або коригується. Якщо з часу останньої корекції пройшло 3 хвилини або отримано повідомлення в тому, що вектор відстані дорівнює 16, маршрут вважається закритим, але запис про нього не стирається, поки не закінчиться час «збирання сміття» (2 хвилини). При появі еквівалентного маршруту перемикання на нього не відбувається. Протокол RIP досить простий, але не позбавлений недоліків:
- потрібно багато часу для відновлення зв'язку після збою в маршрутизаторі (хвилини); в процесі встановлення режиму можливі цикли;
- число кроків – важливий, але не єдиний параметр маршруту, та й 15 кроків – не межа для сучасних мереж.
Випадок нестійкої роботи мережі по протоколу RIP при зміні конфігурації – відмову лінії зв'язку маршрутизатора M1 з мережею 1. При працездатному стані цьому зв'язку в таблиці маршрутів кожного маршрутизатора є запис про мережу з номером 1 і відповідним відстанню до неї (див. рисунок 4.2).
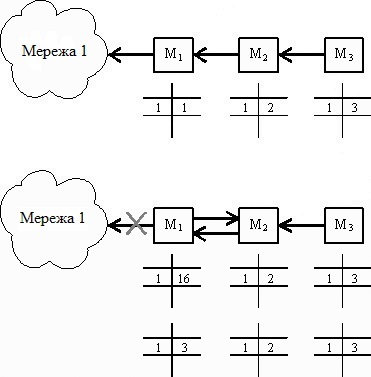
Рисунок 4.2 – Схема роботи протоколу RIP при відключені порту
При обриві зв'язку з мережею 1 маршрутизатор М1 зазначає, що відстань до цієї мережі взяло значення 16. Проте отримавши через деякий час від маршрутизатора М2 маршрутне повідомлення про те, що від нього до мережі 1 відстань складає 2 хопу, маршрутизатор М1 нарощує цю відстань на 1 і відзначає, що мережа 1 досяжна через маршрутизатор 2. У результаті пакет, призначений для мережі 1, буде циркулювати між маршрутизаторами М1 і М2 до тих пір, поки не закінчиться час зберігання запису про мережу 1 в маршрутизаторі 2, і він не передасть цю інформацію маршрутизатора М1.
Для виключення подібних ситуацій маршрутна інформація про відому маршрутизатора мережі не передається тому маршрутизатора, від якого вона прийшла (див. рисунок 4.3, 4.4).
| Код команди | Номер версії | Повинні бути нулі | |||
| Тип сімейства протоколу мережі 1 | Повинні бути нулі | ||||
| IP-адреса мережі 1 | |||||
| Маска підмережі для мережі 1 | |||||
| Адреса найближчої точки переходу для мережі 1 | |||||
| Відстань до мережі 1 | |||||
| Тип сімейства протоколу мережі 2 | Повинні бути нулі | ||||
| IP-адреса мережі 2 | |||||
| Маска підмережі для мережі 2 | |||||
| Адреса найближчої точки переходу для мережі 2 | |||||
| Відстань до мережі 2 | |||||
| … | |||||
Рисунок 4.3 – Формат повідомлення протоколу RIP 1
1 - запит на часткову або повну маршрутну інформацію;
2 - відповідь на запит, що містить пари чисел (адреса мережі, відстань), взяті з таблиці маршрутизації відправника;
9 - запит на оновлення;
10 - відповідь на запит на оновлення.
| Код команди | Номер версії | Повинні бути нулі | |||
| Тип сімейства протоколу мережі 1 | Ознака маршруту до мережі 1 | ||||
| IP-адреса мережі 1 | |||||
| Маска підмережі для мережі 1 | |||||
| Адреса найближчої точки переходу для мережі 1 | |||||
| Відстань до мережі 1 | |||||
| Тип сімейства протоколу мережі 2 | Ознака маршруту до мережі 2 | ||||
| IP-адреса мережі 2 | |||||
| Маска підмережі для мережі 2 | |||||
| Адреса найближчої точки переходу для мережі 2 | |||||
| Відстань до мережі 2 | |||||
| … | |||||
Рисунок 4.4 – Формат повідомлення протоколу RIP 2
Протокол "HELLO". Програмне забезпечення Fuzzball для шлюзу LSI/11 включає в себе реалізацію протоколу IGP під назвою "HELLO". На відміну від RIP в ньому критерієм вибору маршруту служить час, а не відстань, тому "HELLO" вимагає досить точної синхронізації служб часу шлюзів.
Протокол OSPF (Open Shortest Path First, RFC 1850, 1583, 1584, 1587) являє собою протокол стану маршруту, причому в якості метрики використовується коефіцієнт якості обслуговування. Кожен маршрутизатор володіє повною інформацією про стан усіх інтерфейсів шлюзів автономної системи. Визначальними є три характеристики: затримка, пропускна здатність і надійність. Переваги OSPF:
- для кожної адреси може бути кілька маршрутних таблиць, по одній на кожен вид IP-операції;
- кожному інтерфейсу присвоюється безрозмірна ціна, що враховує пропускну здатність, час транспортування повідомлення; кожної IP-операції може бути присвоєна своя ціна;
- при існуванні еквівалентних маршрутів OSPF розподіляє потік рівномірно по цих маршрутах;
- при зв'язку «точка-точка» не потрібне IP-адреса для кожного з кінців;
- застосовується мультікастінга замість широкомовлення, що знижує завантаження не залучених в обмін сегментів.
Недоліки OSPF – важко отримати інформацію про перевагу каналів для вузлів, що підтримують інші протоколи або мають статичну маршрутизацію.
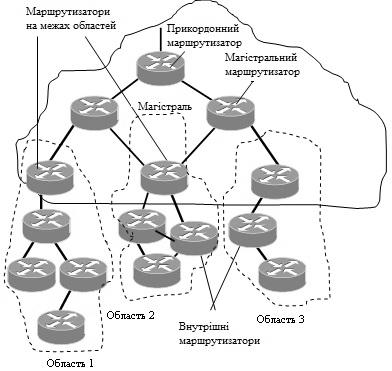
Рисунок 4.5 – Ієрархічно структурована автономна мережа OSPF з чотирма областями
Безпосередньо пов'язані (тобто досяжні без використання проміжних маршрутизаторів) маршрутизатори називаються "сусідами". Кожен маршрутизатор зберігає інформацію про те, в якому стані на його думку знаходиться сусід. Маршрутизатор покладається на сусідні маршрутизатори і передає їм пакети даних тільки в тому випадку, якщо він впевнений, що вони повністю працездатні. Для з'ясування стану зв'язків маршрутизатори-сусіди досить часто обмінюються короткими повідомленнями HELLO.
Для поширення по мережі даних про стан зв'язків маршрутизатори обмінюються повідомленнями іншого типу. Ці повідомлення називаються router links advertisement - оголошення про зв'язки маршрутизатора (точніше, про стан зв'язків). OSPF-маршрутизатори обмінюються не тільки своїми, але й чужими оголошеннями про зв'язки, отримуючи в кінці-кінців інформацію про стан всіх зв'язків мережі. Ця інформація і утворює граф зв'язків мережі, який, природно, один і той же для всіх маршрутизаторів мережі.
Крім інформації про сусідів, маршрутизатор у своєму оголошенні перераховує IP-підмережі, з якими він пов'язаний безпосередньо, тому після отримання інформації про графа зв'язків мережі, обчислення маршруту до кожної мережі проводиться безпосередньо з цього графу за алгоритмом Дейкстри. Більш точно, маршрутизатор обчислює шлях не до конкретної мережі, а до маршрутизатора, до якого ця мережа підключена. Кожен маршрутизатор має унікальний ідентифікатор, який передається в оголошенні про стани зв'язків. Такий підхід дає можливість не витрачати IP-адреси на зв'язку типу "точка-точка" між маршрутизаторами, до яких не підключені робочі станції.
Маршрутизатор обчислює оптимальний маршрут до кожної адресується мережі, але запам'ятовує тільки перший проміжний маршрутизатор з кожного маршруту. Таким чином, результатом обчислень оптимальних маршрутів є список рядків, в яких вказується номер мережі та ідентифікатор маршрутизатора, якому потрібно переслати пакет для цієї мережі. Зазначений список маршрутів і є маршрутної таблицею, але обчислений він на підставі повної інформації про графа зв'язків мережі, а не часткової інформації, як в протоколі RIP.
Описаний підхід призводить до результату, який не може бути досягнутий при використанні протоколу RIP або інших дистанційно-векторних алгоритмів. RIP припускає, що всі підмережі певної IP-мережі мають один і той же розмір, тобто, що всі вони можуть потенційно мати однакове число IP-сайтів, адреси яких не перекриваються. Більше того, класична реалізація RIP вимагає, щоб виділені лінії "точка-точка" мали IP-адресу, що призводить до додаткових витрат IP-адрес.
У OSPF такі вимоги відсутні: мережі можуть мати різне число хостів і можуть перекриватися. Під перекриттям розуміється наявність декількох маршрутів до однієї і тієї ж мережі. У цьому випадку адреса мережі в прийшов пакеті може співпасти з адресою мережі, привласненим декількох портів.
Якщо адреса належить кільком подсетям в базі даних маршрутів, то просуває пакет маршрутизатор використовує найбільш специфічний маршрут, тобто адресу підмережі, що має більше довгу маску.
Наприклад, якщо робоча група відгалужується від головної мережі, то вона має адресу головної мережі поряд з більш специфічним адресою, визначеним маскою підмережі. При виборі маршруту до хоста в підмережі цієї робочої групи маршрутизатор знайде два шляхи, один для головної мережі і один для робочої групи. Так як останній більш специфічний, то він і буде обраний. Цей механізм є узагальненням поняття "маршрут за умовчанням", використовуваного в багатьох мережах.
У протоколі OSPF використовується кілька часових параметрів (див. рисунок 4.6, 4.7), і серед них найбільш важливими є інтервал повідомлення HELLO і інтервал відмови маршрутизатора (router dead interval).
| Номер версії | Тип | Довжина повідомлення | |||
| IP-адресу вихідного маршрутизатора | |||||
| Ідентифікатор зони | |||||
| Контрольна сума | Тип аутентифікації | ||||
| Дані для аутентифікації (октети 0-3) | |||||
| Дані для аутентифікації (октети 4-7) | |||||
Рисунок 4.6 – Формат повідомлення протоколу OSPF
Типи OSPF-повідомлень:
1 - повідомлення HELLO (використовується для перевірки досяжності);
2 - опис бази даних (топологія);
3 - запит про стан з'єднання;
4 - оновлення стану з'єднання;
5 - повідомлення про стан з'єднання.
| Заголовок OSPF повідомлення тип якого дорівнює 1 (довжина заголовка 24 октетів) | ||
| Мережева маска | ||
| Макс. час відповіді | Інтер. відпр. повід. | Пріоритет маршрутиз. |
| IP-адреса виділеного маршрутизатора | ||
| IP-адреса резервного виділеного маршрутизатора | ||
| IP-адреса 1-го сусіда | ||
| … | ||
| IP-адреса N-го сусіда |
Рисунок 4.7 – Формат повідомлення HELLO протоколу OSPF
Протокол IS-IS. Враховуючи, з одного боку, широке поширення мереж з архітектурою TCP/IP, з іншого боку, підвищена увага урядових і комерційних організацій до архітектури ЕМВОС; очікується, що архітектури TCP/IP і ЕМВОС будуть існувати довгий час разом. Тому виникає необхідність у шлюзах, здатних маршрутизировать одночасно IP-і ЕМВОС-трафік. Протокол IS-IS (Intermediate System to Intermediate System Protocol, RFC 1195) забезпечує підтримку понять IP-підмережі, змінної маски підмережі, маршрутизацію на основі значення поля «тип сервісу» в заголовку IP-пакета і поняття зовнішнього маршруту. Протокол IS-IS є динамічним протоколом маршрутизації, побудованим на основі SPF-алгоритму.
Яскравим прикладом глобального протоколу маршрутизації є протокол BGP.
BGP – це протокол роботи з маршрутною інформацією – обмін, зберігання, редагування. На цьому протоколі побудований весь Інтернет. Сегменти Інтернету розбиті на AS – автономні системи – а за допомогою BGP вони обмінюються інформацією. Автономна система – це якась кількість мережевих пристроїв які управляються однаковою політикою (групою адміністраторів). Якщо дуже просто BGP це протокол дозволяє пакетам з вашого комп'ютера досягати одержувача.
Цей протокол вам може знадобитись, наприклад, якщо ви хочете собі зарезервувати блок адрес не менше 256, і хочете щоб вони були провайдеро-незалежними. Купили адреси – разом з номером AS (автономної системи). Встановили з вашим провайдером з’єднання по BGP, працюєте. Набрид провайдер - або змінили місце вашої дислокації на інше де до цього провайдеру підключитися немає можливості, встановлюйте BGP з новим провайдером і адреси у вас залишаються ті ж. Просто доступні тепер за іншими маршрутами.
Ще приклад – ви хочете підключиться одночасно до двох або більше провайдерам для того щоб підвищити стабільність (вартість) роботи Інтернету – тобто впав один з провайдерів – ви автоматично переходите на запасний пакет. Або з одного каналу дешевше один трафік – з іншого, іншого - за допомогою BGP можна розподілити куди ходити трафіку щоб було вигідніше.
Маршрутизатор BGP обмінюються інформацією про доступність тих чи інших мереж – найчастіше вони містять у своїй пам'яті так звану карти (маршрути) як досягти той чи інший адреса – а точніше номери АS (автономної системи) яка стверджує що необхідний вам адресу перебувати в її зоні відповідальності. Виглядає це карта приблизно так – AS (1111) -> AS (1112) -> AS (1113) і так далі тобто скільки AS доведеться пройти пакету щоб дійти до AS одержувача пакета. BGP це дистанційно-векторний протокол це означає що він буде намагатися вибрати найменшу кількість AS в карті до потрібної AS – такий маршрут коротший і BGP вважає його більш швидким. Також варто враховувати що BGP можна використовувати і усередині AS – а не тільки для зовнішнього обміну маршрутами.