Есть несколько методов формирования репрезентативной выборки.
Случайная выборка – метод формирования репрезентативной выборки в условиях отсутствия достоверной информации о параметрах структуры генеральной совокупности. Суть метода – каждая из единиц генеральной совокупности должна иметь равные с прочими шансы быть отобранной в выборку для обследования. Очевидно, что необходимо участие в процессе отбора (информирования выборки) всех единиц генеральной совокупности. Для полной реализации метода случайного отбора обязателен доступ к полному списку единиц (объектов).
Направленная по признаку – метод формирования репрезентативной выборки в условиях отсутствия доступа к списку единиц генеральной совокупности для отбора в выборку. Для реализации метода необходима достоверная информация о структуре генеральной совокупности по характеристикам, существенно влияющим на отношение к предмету исследования. Суть метода в том, что в выборку отбираются единицы, обладающие определенными характеристиками в соответствии со структурой генеральной совокупности. Необходимо понимать, что заверения исследовательских организаций в репрезентативности обследованных выборок (по комплексу характеристик) основаны в основном на исследовательской практике, а не на строгом расчете. Однако есть все основания утверждать, что методы формирования выборок, реализуемые различными организациями (в т. ч. с постановкой квотных ограничений), в большинстве случаев позволяют получать достоверную информацию, т. е. можно утверждать, что структура выборочной совокупности по исследуемым параметрам (характеристикам) адекватна структуре генеральной совокупности.
Следующим шагом на пути организации маркетингового исследования является разработка подходящих процедур построения выборки. Процесс построения выборки включает 5 шагов:
1. Определение целевой популяции.
2. Определение структуры выборки.
3. Выбор метода формирования выборки.
4. Определение размера выборки.
5. Осуществление процесса выборки [11].
Первый этап процесса построения выборки заключается в определении целевой популяции. Под целевой популяцией понимается совокупность элементов или объектов, обладающих необходимой исследователю информацией. Определение целевой популяции включает представление правил, определяющих кто должен, а кто не должен быть включен в выборку. Целевую популяцию следует определить с точки зрения элементов, единиц выборки, пространственного и временного интервала. Элемент - это объект (или человек), о котором или от которого нужно получить информацию, например респондент. Единицей выборки может быть сам элемент, или более доступный объект, содержащий целевой элемент. Пространственный интервал связан с географическими границами исследования. Временной интервал – это период времени, представляющий интерес для исследователя.
Второй этап процесса построения выборки заключается в определении структуры выборки. Структура выборки - это представление элементов целевой популяции. Фактически - это список или набор инструкций по определению целевой популяции. Структура выборки может быть составлена с использованием телефонного справочника, компьютерной программы генерации телефонных номеров, каталога ассоциации, в котором перечислены фирмы некоторой отрасли, почтового списка, приобретенного у коммерческой организации, городского каталога или карты. процесс составления списка элементов часто бывает сложным и несовершенным, что ведёт к ошибке определения размера выборки. Некоторые элементы могут не попасть в выборку или, наоборот, список может содержать элементы, не входящие в целевую популяцию. во избежание допущения ошибки в размере выборки исследователь должен учитывать и обрабатывать ошибку структуры выборки.
Второй этап процесса построения выборки заключается в выборе метода формирования выборки.
Методы формирования выборки можно разделить на вероятностные и невероятностные.
Невероятностная выборка при определении элементов выборки основывается скорее на личном мнении исследователя, чем на случайности. Исследователь может сформировать выборку произвольно, с точки зрения удобства, либо он может принять сознательное решение по поводу того, какие элементы включить в выборку. В данном случае невозможно произвести объективную оценку точности результатов выборки. Под точностью подразумевается степень неопределенности измеряемой характеристики. Так как вероятность отбора того или иного элемента неизвестна. Поэтому полученные оценки не могут быть распространены на всю популяцию с некоторой определенной степенью уверенности.
Невероятностные методы построения выборки включают следующие разновидности:
· Выборка по удобству;
· Выборка по усмотрению;
· Выборка методом квот;
· Выборка методом снежного кома.
Выборка по удобству, как и подразумевается из названия, стремится получить набор элементов на основании удобства для исследования. Выбором единиц выборки занимается преимущественно интервьюер. Часто респонденты попадают в выборку потому, что они оказываются в нужное время в нужном месте.
Преимущества в том, что такая выборка является недорогой и быстрой. Кроме того, единицы обычно доступны, легки для измерения и охотно сотрудничают и интервьюером. Несмотря на эти преимущества, у данного вида выборки есть серьезные ограничения. Главным ограничением является тот факт, что итоговая выборка не является представителем любой определимой целевой популяции. Этот процесс выборки характеризуется отклонением отбора. Это означает, что характеристики людей, включенных в выборку по удобству, могут систематически отличаться от характеристик целевой популяции. Из-за этих ограничений теоретически бессмысленно делать обобщение на всю популяцию.
Выборка по усмотрению представляет собой такую форму выборки по удобству, при которой элементы популяции выбираются на основании мнения исследователя. Исследователь выбирает те или иные элементы выборки, т. к. он считает, что они представляют целевую популяцию.
Выборка по усмотрению является привлекательной из-за ее низкой стоимости, удобства и скорости. Однако она является субъективной, в значительной степени зависящей от опыта и творческих способностей исследователя. Поэтому нельзя делать обобщений для конкретной популяции, обычно по причине того, что популяция четко не определена. Этот метод выборки лучше всего подходит для исследований, в которых не требуется делать обобщений для всей популяции.
Выборка методом квот расширяет выборку по усмотрению. Здесь процесс выборки по усмотрению состоит из двух этапов. На первом этапе происходит разработка контрольных категорий, иначе квот, элементов популяции. Используя здравый смысл для определения релевантных категорий, таких как пол или раса, исследователь оценивает распределение этих характеристик в целевой популяции. Квоты используются для обеспечения того, что состав выборки и состав популяции будут одинаковыми в отношении характеристик, представляющих интерес.
Как только определены квоты, начинается второй этап формирования выборки. Элементы подбираются по удобству или по усмотрению. Присутствует значительная свобода при выборе элементов, которые включаются в выборку. Единственным требованием является то, чтобы выбранные элементы соответствовали контрольным характеристикам.
return false">ссылка скрытаОднако с этим методом выборки связано множество потенциальных проблем. В процессе установки квот можно не придать значения важным характеристикам, а это ведет к тому, что с точки зрения релевантных контрольных характеристик выборка не будет являться достаточно хорошим представлением популяции. Так как в каждой квоте элементы выбираются по удобству или по усмотрению, возможно множества источников отклонения отбора. Еще одним ограничением выборки методом квот является тот факт, что для нее нельзя выполнить оценку ошибки выборки.
Выборка методом снежного кома выбирается первоначальная группа респондентов, обычно случайным образом. Этих респондентов, после того, как они опрошены, просят указать, кто еще принадлежит к целевой популяции, представляющей интерес. Этот процесс продолжается, что ведет к эффекту снежного кома, т.к. одна ссылка исходит из другой. Таким образом, в результате этого процесса формируется структура выборки, из которой отбираются респонденты. Несмотря на то, что в этом методе выборки сначала используется вероятностная выборка, в результате получается невероятностная выборка. Это происходит потому, что указанные респонденты по демографическим и психографическим характеристикам будут скорее похожи на респондентов, которые указали на них.
Выборка методом снежного кома используется при изучении характеристик, которые для данной популяции являются сравнительно редкими или трудными для выявления. Главное преимущество заключается в том, что она значительно увеличивает вероятность обнаружения требуемых свойств среди популяции. Она характеризуется сравнительно низкой стоимостью и величиной отклонений в выборке[12].
При вероятностной выборке элементы выборки отбираются случайным образом. Вероятность получения любой потенциальной выборки из популяции может быть установлена заранее. Для оценки качества выборки могут быть рассчитаны доверительные интервалы, и уже имеет смысл статистически распространять результаты, полученные для выборки на всю популяцию, т.е. делать выводы насчёт целевой популяции.
Они варьируются с точки зрения эффективности выборки. Эффективность выборки – это понятие, отражающее компромисс между стоимостью выборки и точностью. Эффективность вероятностного метода построения выборки можно оценить путем ее сравнения с эффективность простой случайной выборки.
Вероятностные методы построения выборки включают следующие разновидности:
· Простая случайная выборка;
· Систематическая выборка;
· Стратифицированная выборка;
· Кластерная выборка.
Простая случайная выборка каждому элементу популяции соответствует заданная и одинаковая вероятность отбора. Составляется схема исследования путем присвоения каждому элементу уникального идентификационного номера. Затем, для того, чтобы определить, какой элемент выбрать, используются случайные числа, сгенерированные с помощью компьютерной программы или таблицы случайных чисел.
У метода простой случайной выборки есть множество преимуществ. Он прост для понимания, и он направлен на то, чтобы получить данные, являющиеся репрезентативными для целевой популяции. Но есть как минимум четыре существенных ограничения:
1. Построение структуры выборки с использованием этого метода является сложной задачей
2. Этот метод может оказаться дорогостоящим и занимать много времени, так как структура выборки географически может быть распределена по большой территории
3. Метод простой случайной выборки часто дает низкую точность, генерируя выборки с высокой среднеквадратической ошибкой
4. Выборки могут быть нерепрезентативными выборками целевой популяции, особенно если размер выборки мал.
Систематическая выборка заключатся в том, что выборка формируется путем выбора случайным образом начальной точки затем последовательно отбора каждого i-элемента схемы выборки. Частота отбора элементов, i, называется интервалом выборки. Он вычисляется путем деления размера популяции N на размер выборки n и округления полученного значения до ближайшего целого.
Элементы популяции, используемые при систематической выборке, обычно определенным образом организованы.
Систематическая выборка менее дорогостояща и более проста, чем простая случайная выборка, потому что здесь случайный выбор происходит только один раз. Кроме того, систематическую выборку можно применить, не имея знаний о структуре схемы выборки.
Стратифицированная выборка представляет собой процесс выборки, состоящий их двух этапов и производящий скорее вероятностную выборку, чем выборку по удобству или по усмотрению. Во-первых, популяция делится на подгруппы, называемые стратами. Каждый элемент популяции должен быть отнесен к одной и только одной страте, и ни один из элементов не должен быть пропущен. Во-вторых, элементы из каждой страты должны быть отобраны случайным образом. Идеальным вариантом является использование метода простой случайной выборки для отбора элементов в каждой страте.
Страты формируются исходя из четырех критериев: однородность, разнородность, связанность, стоимость. Следует соблюдать следующие указания:
· Элементы в пределах страты должны быть похожими или однородными
· Элементы, находящиеся в разных стратах, должны отличаться, т. е. быть разнородными
· Стратификационные переменные должны быть связаны и интересующей характеристикой
· Количество страт обычно варьируется между двумя и шестью. Когда число страт превышает шесть, всякое дальнейшее повышение точности происходит за счет очень высокой стоимости.
У метода стратификации есть два преимущества. Когда исследование проводится с учетом перечисленных выше указаний, колебания в выборке уменьшаются. Стоимость выборки также можно уменьшить, если стратификационные переменные выбираются так, чтобы их было легко измерить и применить. Стратификационная выборка повышает точность метода генерации простой случайной выборки.
Кластерная выборка целевую популяцию сначала делят на взаимно исключающие и совокупно исчерпывающие субпопоуляции, по-другому – кластеры. Затем с помощью вероятностного метода выборки, такого как простая случайная выборка, формируется произвольная выборка из кластеров. В каждом отдельном кластере включаются либо все элементы, либо выборка элементов, сформированная вероятностным методом.
Кластерная выборка имеет два основных преимущества: легкая осуществимость и низкая стоимость. Так как структуры выборки часто составляются на основании кластеров, а не элементов популяции, кластерная выборка может быть единственно возможным вариантом. Кластерная выборка является самым экономически эффективным методом выборки. Это преимущество следует рассматривать, принимая во внимание то, что существуют и некоторые ограничения. При кластерном методе построения получаются некачественные выборки, в которых трудно сформировать отличающиеся, разнородные кластеры.
Выбор между невероятностным и вероятностным методом построения выборки следует делать, принимая во внимание такие факторы, как природа исследования, ошибка, вносимая в процессе выборки, изменчивость популяции, статистические и оперативные факторы. Например, в познавательных исследованиях получаемые сведения рассматриваются как предварительные, и тогда применение вероятностной выборки может быть неоправданным. С другой стороны, в итоговых исследованиях, в которых исследователь хочет обобщить результаты на всю целевую популяцию., как в случаях оценки доли рынка, предпочтительно использование вероятностной выборки. Вероятностные выборки делают возможным статистическое распространение результатов на целевую популяцию.
Когда требуется высокая степень точности, как в случае получения оценок характеристик популяции, желательно использовать вероятностную выборку. В таких ситуациях исследователю нужно устранить отклонения отбора и вычислить влияние ошибки выборки. Для этого требуется использование вероятностной выборки. Однако даже при такой повышенной точности метода формирования, вероятностная выборка не всегда даст более точные результаты. Например, с помощью вероятностной выборки невозможно контролировать ошибки, не связанные с выборкой. Если ошибки именно такого рода будут представлять главную проблему, то невероятностные методы выборки, такие как выборка по усмотрению, могут оказаться более предпочтительными, так как они дают повышенный уровень контроля над процессом выборки.
При выборе между методами формирования выборки исследователь должен также принять во внимание похожесть или однородность популяции в характеристиках, представляющих интерес. Например, вероятностная выборка лучше подходит для популяций с высокой степенью разнородности, для которых формирование репрезентативной выборки имеет исключительно большое значение. Вероятностная выборка более предпочтительна и с точки зрения статистики, так как на ее основе можно применять все наиболее распространенные статистические методы.
Хотя вероятностный метод формирования выборки имеет множество преимуществ, он сложен и требует от исследователей отличного знания статистики. Обычно построение вероятностной выборки дороже и требует больше времени, чем невероятностной. Во многих проектах маркетинговых исследований очень сложно найти оправдание дополнительным затратам финансов и времени. Поэтому на практике использование того или иного метода выборки диктуется целями исследования.
Четвёртым этапом процесса построения выборки является определение её размера. Под размером выборки подразумевается число элементов, которые должны быть в нее включены. Необходимый размер выборки зависит от ряда качественных и количественных факторов. Начнем с качественных факторов.
1. Чем важнее решение, тем больше информации нужно для его обоснования и тем точнее она должна быть. Соответственно, нужна большая выборка. Однако каждая дополнительная единица повышения точности требует все больше затрат. Случайная ошибка выборки уменьшается обратно пропорционально корню квадратному из числа элементов в выборке. Доли представителей исследуемой совокупности, обладающих определенным свойством. Однако, чем больше выборка, тем меньше выигрыш в точности от добавления в нее каждого следующего респондента[13].
2. На размере выборки сказывается природа исследования. Разные виды исследований предполагают использование выборки разного размера. Минимальный и типичный размеры выборки для разных исследований представлены в табл. [14].
Табл. .Определение размеров выборки.
| Задачи исследования | Размер выборки | |
| Минимальный | Типичный | |
| Выявление проблем (например, оценка потенциала рынка) | 1000-2500 | |
| Решение проблем (например, относительно цены товара) | 300-500 | |
| Тестирование продукта | 300-500 | |
| Тестирование телевизионной, радио- или печатной рекламы (в расчете на один рекламный продукт) | 200-300 |
3. Если предполагается получить оценки не только для всех элементов выборки в целом, но и для отдельных подгрупп элементов, выборка должна быть больше.
4. Необходимый размер выборки можно приблизительно оценить, зная, в каких пределах он обычно находится в аналогичных исследованиях (табл.).
5. Размер выборки также определяется финансовыми и временными ресурсами, численностью квалифицированного персонала для сбора данных, а также особенностями элементов выборки.
Количественные методы определения размера выборки подразделяются на методы, основанные на средних арифметических значениях и методы, основанные на пропорция.
Если в результате исследования требуется определить среднее значение некоторого показателя, необходимый для этого размер выборки можно рассчитать по формуле:
n = (Zσ/Δ)2,
где Δ — величина погрешности, которую решено считать допустимой;
Z — значение границы доверительного интервала по таблицам стандартизованного (т.е. с нулевым средним и единичной дисперсией) нормального распределения для выбранного уровня доверительной вероятности; например, при уровне доверительной вероятности 90% Z =1,64, при 95% — Z =1,96, при 99% - Z=2,58;
σ — стандартное отклонение показателя, среднее значениекоторого требуется определить. Если опыта изучения этого показателя нет, приходится делать предположение относительно его стандартного отклонения, которое после исследования проверяется по данным исследования.
В случае, когда существует только две категории ответа на задаваемый респондентам вопрос, и исследователь изучает процентное соотношение элементов, находящихся в одной из этих категорий, используется второй метод определения размера выборки, основанный на пропорциях. Тогда формула для определения размера выборки имеет вид:
 n = (Z√π(1-π)/Δ)2,
n = (Z√π(1-π)/Δ)2,
где Δ — величина погрешности в долях единицы, которую решено считать допустимой;
Z — значение границы доверительного интервала по таблицам нормализованного (т.е. с нулевым средним и единичной дисперсией) нормального распределения для выбранного уровня доверительной вероятности;
π— предположительная доля представителей исследуемой совокупности, которые ответили бы на данный вопрос интересующим нас образом.
На последнем, пятом, этапе построения выборки – этапе осуществления процесса выборки - необходимо детально определить, как конкретно будут воплощаться в жизнь все решения, принятые на более ранних этапах построения выборки: решения об исследуемой совокупности, о единицах отбора, о методе построения выборки и её размере. Например, необходимо составить набор инструкций для людей, занимающихся сбором информации.
При проведении маркетингового исследования одной из основных задач исследователей становится минимизация ошибок, возникающих в процессе сбора, анализа и интерпретации данных.
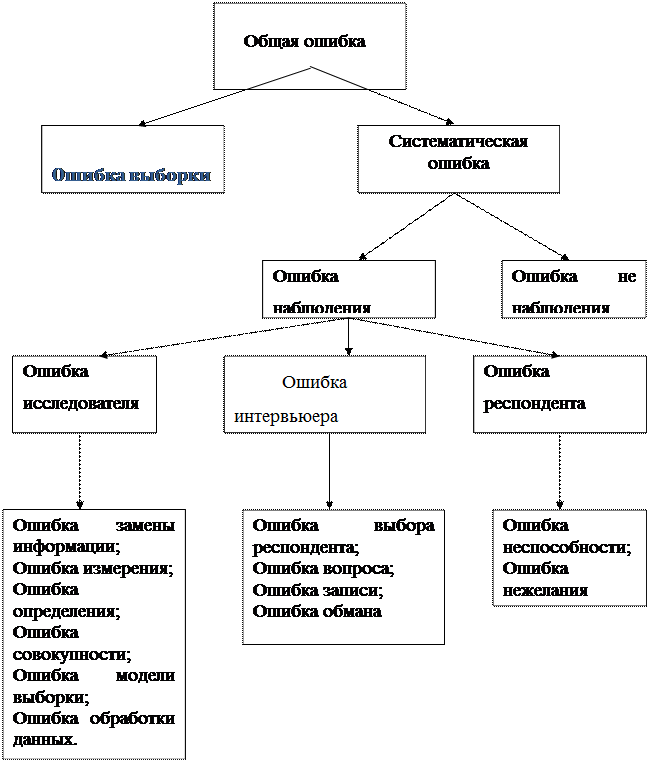
Источники ошибок представлены на рис.[15]
Общая ошибка – отклонение истинного среднего значения интересующей переменной в генеральной совокупности от наблюдаемого среднего значения величины, полученного в результате проведенного маркетингового исследования.
Ошибка выборки – возникает потому, что конкретная отдельная выборка не в полной мере соответствует интересующей маркетолога генеральной совокупности. Она представляет собой отклонение истинного среднего значения величины для генеральной совокупности от истинного среднего значения величины для исходной выборки.
Систематическая ошибка – Представляет собой ошибку, которая не связана с формированием выборки. Могут быть случайными и неслучайными.
Ошибка не наблюдения – возникает, когда от некоторых из респондентов, входящих в выборку нельзя получить ответ.
Ошибка наблюдения – возникает, когда респонденты дают неточные ответы, их ответы неправильно записаны или неправильно проанализированы.