Лекция№7 Элементы гидродинамики.
Рис. 4.3.1.7. Конфигурации вычислительных систем: кластеры и созвездия
Рис. 4.3.1.4. Гибридная архитектура
Рис. 4.3.1.3. Схемы асимметричной многопроцессорной архитектуры
Рис. 4.3.1.2. Симметричная мультипроцессорная архитектура
Лекция 7.
Симметрическая мультипроцессорная обработка Symmetric Multi Processing (SMP)– архитектура суперкомпьютера, в которой группа процессоров работает с общей оперативной памятью (рис. 4.3.1.2).
Память является способом передачи сообщений между процессорами, при этом все вычислительные устройства при обращении к ней имеют разные права и одну и ту же адресацию для всех ячеек памяти.
Работой управляет единственная копия операционной системы. Для ускорения обработки каждый процессор может также иметь собственную кэш-память. Задания между процессами распределяются непосредственно при выполнении прикладного процесса. Нагрузка между процессорами динамически выравнивается, а обмен данными между ними происходит с большой скоростью. Достоинство этого подхода состоит в том, что каждый процессор видит всю решаемую задачу в целом. Но поскольку для взаимодействия используется лишь одна шина, то возникают повышенные требования к ее пропускной способности. Соединение посредством шины применяется при небольшом (4-8) числе процессоров.
В подобных системах возникает проблема организации когерентности многоуровневой иерархической памяти.
Когерентность кэшей означает, что все процессоры получают одинаковые значения одних и тех же переменных в любой момент времени. Действительно, поскольку кэш-память принадлежит отдельному компьютеру, а не всей многопроцессорной системе в целом, данные, попадающие в кэш одного компьютера, могут быть недоступны другому. Чтобы избежать этого, следует провести синхронизацию информации, хранящейся в кэш-памяти процессоров.
Возможность увеличения числа процессоров в SMP ограничена из-за использования общей памяти. Более того, по той же причине все процессоры должны располагаться в одном корпусе. Между тем, преимуществом SMP является то, что она может работать с прикладными программами, разработанными для однопроцессорных систем.
Асимметрическая мультипроцессорная обработка ASymmetric Multi Processing (ASMP)– архитектура суперкомпьютера, в которой каждый процессор имеет свою оперативную память.
В ASMP используются три схемы (рис. 4.3.1.3). В любом случае процессоры взаимодействуют между собой, передавая друг другу сообщения, т.е. как бы образуя скоростную локальную сеть. Передача сообщений может осуществляться через общую шину (рис.4.3.1.3, а, см. также МРР-архитектуру), либо благодаря межпроцессорным связям. В последнем случае процессоры связаны либо непосредственно (рис. 4.3.1.3, б), либо через друг друга (рис. 4.3.1.3, в). Непосредственные связи используются при небольшом числе процессоров.
Каждый процессор имеет свою оперативную память, расположенную рядом с ним. Благодаря этому, если это необходимо, процессоры могут располагаться в различных, но рядом установленных корпусах. Группа устройств в одном корпусе именуется кластером. Пользователь, обращаясь к кластеру, может работать сразу с группой процессоров. Такое объединение увеличивает скорость обработки данных и расширяет используемую оперативную память. Резко возрастает также отказоустойчивость, ибо кластеры осуществляют резервное дублирование данных. Созданная таким образом система называется кластерной. В этой системе в соответствии с ее структурой может функционировать несколько копий операционной системы и несколько копий прикладной программы, которые работают с одной и той же базой данных (БД), решая одновременно разные задачи.
MPP-архитектура (massive parallel processing)– массивно- параллельная архитектура (рис. 4.3.1.3, а). В этом случае система строится из отдельных модулей, каждый из которых содержит:
· процессор;
· локальный банк оперативной памяти (ОП);
· два коммуникационных (маршрутизатора, рутера): один – для передачи команд, другой для передачи данных (или сетевой адаптер);
· жесткие диски и/другие устройства ввода-вывода.
По своей сути, такие модули представляют собой полнофункциональные компьютеры. Доступ к банку ОП из данного модуля имеют только процессоры из этого же модуля. Модули соединяются специальными коммуникационными каналами. Пользователь может определить логический номер процессора, к которому он подключен, и организовать обмен сообщениями с другими процессорами.
Гибридная архитектура Nonuniform Memory Access (NUMA). Главная особенность гибридной архитектуры NUMA – неоднородный доступ к памяти.
Гибридная архитектура воплощает в себе удобства систем с общей памятью и относительную дешевизну систем с раздельной памятью. Суть этой архитектуры – в методе организации памяти, а именно: память является физически распределенной по различным частям системы, но логически разделяемой, так что пользователь видит единое адресное пространство. Система состоит из однородных базовых модулей (плат), состоящих из небольшого числа процессоров и блока памяти. Модули объединены с помощью высокоскоростного коммутатора. Поддерживается единое адресное пространство, аппаратно поддерживается доступ к удаленной памяти, т.е. к памяти других модулей. При этом доступ к локальной памяти осуществляется в несколько раз быстрее, чем к удаленной. По существу архитектура NUMA является ММР-архитектурой (массивно-параллельной), где в качестве отдельных вычислительных элементов берутся SMP-узлы.
Пример структурной схемы компьютера с гибридной сетью (рис. 4.3.1.4): четыре процессора связываются между собой с помощью кроссбара в рамках одного SMP-узла. Узлы связаны сетью типа “бабочка”.
Известны также гибридные структуры с коммутатором (рис. 4.3.1.5). Здесь каждый процессор работает со своей памятью, но модули устройств памяти связаны друг с другом с помощью коммутатора (рис. 4.3.1.5, а). Коммутаторы могут включаться также между группами процессоров (ПР) и модулей памяти (П). Здесь сообщения между процессорами и памятью передаются через несколько узлов (рис. 4.3.1.5, б).
Архитектура развивалась такими компаниями, как Burrought, Convex Computer (в последующем HP), SGA, Sequent и Data General в период 1990-х гг. Разработанные здесь технологии в дальнейшем воплотилась в многих Unix-подобных ОС, а также в определенной степени – в Windows NT.
Эффективность как UMA, так и NUMA ограничивается пропускной способностью шины памяти и временами задержки как шины, так и самой памяти. Это значит, что с увеличением числа процессоров после определенного предела производительность перестает возрастать линейно. Этот “предел роста” зависит от выполняемых приложений и, как правило, не превосходит 24-68 процессоров.
Рис. 4.3.1.5. Гибридная архитектура с коммутатором (а); многокаскадная коммутация (б)
PVP-архитектура. PVP (Parallel Vector Process) – параллельная архитектура с векторными процессами. Основным признаком PVP-систем является наличие векторно-конвейерных процессов, в которых предусмотрены команды однотипной обработки векторов независимых данных, эффективно выполняющиеся на конвейерных функциональных устройствах. Как правило, несколько таких процессоров (1-16) работают одновременно с общей памятью (аналогично SMP) в рамках многопроцессорных конфигураций. Несколько таких узлов могут быть объединены с помощью коммутатора (аналогично MMP).
Кластерная архитектура. Кластер, как правило, состоит из двух или более узлов, которые связаны интерфейсами. Распределенные данные, которые доступны кластеру, находятся в накопителях информации. Каждый узел кластера содержит следующие основные компоненты:
· центральный процессор (ЦП – основное звено обработки информации), обменивающийся данными с оперативной памятью;
· оперативную память (ОП), предназначенную для хранения программ и данных;
· интерфейсы, обеспечивающие связь узлов;
· накопители данных (диски, ленты и пр.).
В любой кластерной архитектуре ЦП используется более или менее одноканальным образом, однако методы конфигурирования компонентов - узлов, памяти и интерфейсов – существенно различаются. В качестве узлов кластера могут выступать серверы, рабочие станции или обычные персональные компьютеры. Преимущество кластеризации для повышения работоспособности становится очевидным в случае сбоя какого-либо узла; при этом узел кластера может взять на себя нагрузку несправного узла, и пользователи не заметят прерывания в доступе. Возможности масштабируемости кластеров позволяют многократно увеличивать производительность приложений для большого числа пользователей.
Типы кластеров:
Тип I. Машина строится целиком из стандартных деталей, которые продают многие продавцы компьютерных компонентов (низкие цены, простое обслуживание, аппаратные компоненты доступны из различных источников).
Тип II. Система включает эксклюзивные или не широко распространенные детали. Этим можно достичь очень хорошей производительности, однако, при более высокой стоимости. Отметим, что границы между этими типами кластеров до некоторой степени размыты, и часто существующий кластер может иметь такие свойства или функции, которые выходят за рамки перечисленных типов. Более того, при конфигурировании большого кластера, используемого как система общего назначения, приходится выделять блоки, выполняющие все перечисленные функции.
Связь процессоров в кластерной системе. Архитектура кластерной системы (способ соединения процессоров друг с другом) определяет ее производительность в большей степени, чем тип используемых в ней процессоров. Критическим параметром, влияющим на величину производительности такой системы, является расстояние между процессорами. Так, соединив вместе 10 персональных компьютеров, можно получить систему для проведения высокопроизводительных вычислений. Проблема, однако, будет состоять в нахождении наиболее эффективного способа соединения стандартных средств друг с другом, поскольку при увеличении производительности каждого процессора в 10 раз производительность системы в целом в 10 раз не увеличится.
Доступ к внешней памяти (накопителям) в кластерных структурах. Кластерные архитектуры используют различные методы доступа к накопителям информации, каждый из которых использует специфическую схему распределения ресурсов, наилучшую для решаемых задач. Тип доступа к внешней памяти может быть независимым от использования ОП, например, кластер типа SMP может быть снабжен как однородным, так и неоднородным доступом к дисковой памяти.
Однородный доступ к дисковой памяти (Uniform Disk Memory Access – UDMA). При UDMA (рис. 4.3.1.6, а), затраты на доступ к дискам одинаковы для различных узлов.
Кластер на рис. 4.3.1.6, а состоит из нескольких SMP-узлов. Совместно используемая дисковая система такого типа часто применяется при организации соединения по каналам SCSI или Fibre Channel с большим количеством дисков.
Преимущества UDМA:
· высокая доступность данных, даже если некоторые узлы выходят из строя, доступ к данным не нарушается;
· хорошая масштабируемость.
Рис. 4.3.1.6. Разновидности архитектур доступа к дисковой памяти: а – однородный доступ (UDMA); б – неоднородный (NUDMA)
Неоднородный доступ к дискам (Non-Uniform Disk Memory Access - NUDMA). В таких системах дисковая память подсоединяется непосредственно к узлам, и для каждого узла такой диск является локальным. Для всех других узлов доступ к “чужому” диску должен быть обслужен программными средствами поддержки виртуальных дисков через каналы связи между узлами. Это означает, что затраты на такой доступ возрастают, как в связи с пониженным приоритетом “чужого” процессора, так и за счет задержек коммутации и перегрузки каналов связи.
Преимущества неоднородного доступа к дискам:
· количество узлов не ограничено возможностями системы коммуникации с дисками;
· общий объем дисковой памяти может быть неограниченно увеличен путем добавления узлов.
Созвездия. Для определенных кластерных конфигураций в последе время был предложен термин созвездие (constellation) (рис. 4.3.1.7).
Каждый узел кластера есть независимый компьютер с одним или более (N) процессоров. Если в системе всего M узлов, причем численность узла меньше этого количества (N<M), то имеет место кластерная конфигурация, в противном случае (N>M) имеет дело с созвездием.
Контрольные вопросы:
1. Симметрическая мультипроцессорная обработка Symmetric Multi Processing – ?
2. Когерентность кэшей означает-?
3. Увеличения числа процессоров в SMP ограничена -?
4.Преимуществом SMP является-?
5.Асимметрическая мультипроцессорная обработка ASymmetric Multi Processing (ASMP) –?
6.Кластер-?
7. MPP-архитектура (massive parallel processing) -?
8. Гибридная архитектура Nonuniform Memory Access (NUMA)-?
9.PVP-архитектура. PVP (Parallel Vector Process) -?
10.Кластерная архитектура -?
11. Типы кластеров -?
12. Связь процессоров в кластерной системе -?
13. Доступ к внешней памяти (накопителям) в кластерных структурах -?
14.Однородный доступ к дисковой памяти (Uniform Disk Memory Access )-?
15. Созвездие (constellation) -?
1)Метод Лагранжа
2)Метод Эйлера
Метод Лагранжа.

Рассмотрим движение отдельных физически малых объемов жидкости, записывается уравнение движения 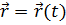 , x=x(t), y=y(t), z=z(t), записывается уравнение каждой частицы, записать скорость именно этой частицы в данный момент времени.
, x=x(t), y=y(t), z=z(t), записывается уравнение каждой частицы, записать скорость именно этой частицы в данный момент времени.
а)Поле скоростей всех частиц жидкости или газа в данный момент времени.

Эйлер вводит понятие поле скоростей. Согласно его методу задаются скорость частиц в каждой точке пространства заданного потоком.
б)Линия тока-линия, касательная к которой совпадает с направлением вектора скорости частиц.
В общем случае линия тока не совпадает с траекторией отдельной частицы, но если поток стационарен, т.е. вектор скорости в заданной точке не зависит от времени, то линии совпадут.
в)Трубка тока- поверхность, образованная линиями тока, проведенными через любой замкнутый контур.
