РЕШЕНИЕ ТИПОВОГО ПРИМЕРА
СОДЕРЖАНИЕ
| С. | ||
| ЛАБОРАТОРНАЯ РАБОТА № 1 «Математическое моделирование экономических процессов с помощью парных регрессионных моделей» …………………………………………………………………. | ||
| ЛАБОРАТОРНАЯ РАБОТА № 2 «Математическое моделирование экономических процессов с помощью моделей множественной регрессии» ...…………………………………………………………….. | ||
| ЛАБОРАТОРНАЯ РАБОТА № 3 «Анализ и прогнозирование временных рядов» ……………....….……………..…………………….. | ||
| Рекомендуемый список литературы для выполнения практических работ …………………………………………………………………….. | ||
| Приложение …………………………………………………………….. |
ЛАБОРАТОРНАЯ РАБОТА № 1
«Математическое моделирование экономических процессов с помощью парных регрессионных моделей»
Данные представлены таблицей значений независимой переменной X и зависимой переменной Y.
Задание
1. Вычислить коэффициент корреляции и сделать вывод о тесноте и направлении связи.
2. На уровне значимости α = 0,05 проверить гипотезу о значимости коэффициента корреляции.
3. Составить уравнение парной регрессии Y = b0 + b1X.
4. Нанести данные на чертеж и изобразить прямую регрессии.
5. С помощью коэффициента детерминации R2 оценить качество построенной модели.
6. Оценить значимость уравнения регрессии с помощью дисперсионного анализа.
7. При уровне значимости a = 0,05 построить доверительные интервалы для оценки параметров регрессии β1, β0 и сделать вывод об их значимости.
8. При уровне значимости a = 0,05 получить доверительные интервалы для оценки среднего и индивидуального значений зависимой переменной Y, если значение объясняющей переменной X принять равным x*.
| x | |||||||||||
| y | |||||||||||
| x* = 105 |
| x | |||||||||||
| y | |||||||||||
| x* = 105 |
| x | |||||||||||
| y | |||||||||||
| x* = 98 |
| x | |||||||||||
| y | |||||||||||
| x* = 40 |
| x | |||||||||||
| y | |||||||||||
| x* = 100 |
| x | |||||||||||
| y | |||||||||||
| x* = 90 |
| x | |||||||||||
| y | |||||||||||
| x* = 90 |
| x | |||||||||||
| y | |||||||||||
| x* = 96 |
| x | |||||||||||
| y | |||||||||||
| x* = 27 |
| x | |||||||||||
| y | |||||||||||
| x* = 100 |
РЕШЕНИЕ ТИПОВОГО ПРИМЕРА
Пусть имеются следующие данные:
| x | ||||||||||
| y | ||||||||||
| x* = 85 |
1. Вычисление коэффициента корреляции rxy проведем по формуле:
 ,
,
а расчёт параметров b1 и b0 выборочного уравнения парной регрессии соответственно по формулам:
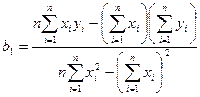 ,
, 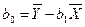 ,
,
где  ,
, 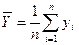 , а n – объём выборки.
, а n – объём выборки.
Для расчётов удобно использовать следующую таблицу:
Таблица 1 – Вспомогательная таблица для расчета параметров уравнения парной регрессии
| № | 
| 
| 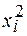
| 
| 
| 
| 
| 
|
| 60,000 | 4,000 | 16,000 | ||||||
| 34,678 | -7,322 | 53,612 | ||||||
| 27,772 | 9,772 | 95,492 | ||||||
| 76,114 | -7,886 | 62,189 | ||||||
| 76,114 | 20,114 | 404,573 | ||||||
| 87,624 | -19,376 | 375,429 | ||||||
| 87,624 | -2,376 | 5,645 | ||||||
| 78,416 | 10,416 | 108,493 | ||||||
| 41,584 | 10,584 | 112,021 | ||||||
| 30,074 | -17,926 | 321,341 | ||||||

| 600,00 | 0,000 | 1554,796 |
Замечание. Столбцы 7 – 9 таблицы 1 заполняются после получения выборочного уравнения прямой регрессии и будут необходимы для выполнения последующих пунктов задания.
Используя результаты вычислений, представленные в таблице 1, найдём значение выборочного коэффициента корреляции:
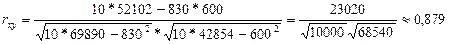 .
.
Полученное значение коэффициента корреляции свидетельствует о том, что между переменными 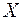 и
и  имеется высокая корреляционная связь. Данная связь характеризуется как положительная, т. е. с увеличением одной из переменных значения другой переменной также увеличиваются.
имеется высокая корреляционная связь. Данная связь характеризуется как положительная, т. е. с увеличением одной из переменных значения другой переменной также увеличиваются.
2. Для оценки значимости коэффициента корреляции следует использовать статистику
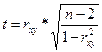 ,
,
которая в условиях нулевой гипотезы H0 : ρxy = 0 имеет распределение Стьюдента с числом степеней свободы, равным n – 2. В нашем случае получаем следующее расчётное значение статистики:
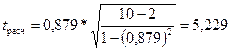 .
.
Используя таблицы распределения Стьюдента при заданном уровне надёжности γ = 0,95 (γ = 1 – α) и числе степеней свободы, равном 8, определим критическое значение статистики:
tкрит= t(0,95;8) = 2,31.
Поскольку |tрасч| > tкрит, то нулевую гипотезу о равенстве нулю коэффициента корреляции отвергаем с вероятностью ошибки меньше 5% и делаем вывод о значимости коэффициента корреляции.
3. Для того чтобы составить выборочное уравнение прямой регрессии, необходимо вычислить коэффициенты b1 и b0. Используя результаты расчётов, представленных в таблице 1, находим:

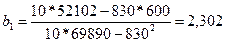 ,
,
b0 = 60 – 2,302*83 = –131,066.
Таким образом, получаем следующее регрессионное уравнение:
Y = -131,066 + 2,302*X.
4. Прямая регрессии представлена на рисунке 1.

Рисунок 1 – График линейной регрессионной модели
5. Качество регрессионной модели может быть оценено с помощью коэффициента детерминации R2, который определяется формулой:
 ,
,
где ŷi = b0 + b1xi, 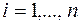 – расчётные (прогнозные) значения величины , полученные подстановкой соответствующих значений X в уравнение регрессии. Для вычисления этих значений используются столбцы 7 – 9 таблицы 1. В нашем случае имеем:
– расчётные (прогнозные) значения величины , полученные подстановкой соответствующих значений X в уравнение регрессии. Для вычисления этих значений используются столбцы 7 – 9 таблицы 1. В нашем случае имеем:
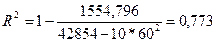 .
.
Коэффициент детерминации показывает, какую часть вариации (дисперсии) зависимой переменной Y воспроизводит (объясняет) построенное уравнение регрессии. В нашем случае построенное уравнение регрессии на 77,3% объясняет зависимость переменной от переменной X.
Замечание. Для проверки правильности расчётов можно воспользоваться соотношением  .
.
6. Проверка значимости уравнения регрессии заключается в установлении его существенности. Другими словами эта проверка даёт ответ на вопрос о том, насколько можно быть уверенным, что рассматриваемая регрессионная зависимость действительно наличествует в генеральной совокупности, а не является результатом случайного отбора наблюдений.
Проверка значимости регрессионной зависимости производится методом однофакторного дисперсионного анализа, где в качестве фактора выступает построенное уравнение регрессии. Результаты дисперсионного анализа принято представлять в виде стандартной таблицы 2.
Таблица 2 – Результаты дисперсионного анализа
| Компоненты вариации | Сумма квадратов | Число степеней свободы | Средние квадраты | F -отношение |
| Регрессия | 
| 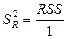
| 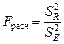
| |
| Остаточная | 
| n – 2 | 
| |
| Общая | 
| n – 1 |
В нашем случае при расчёте сумм квадратов следует принять во внимание следующие равенства:
 ;
;
RSS = TSS – ESS.
С учётом результатов, представленных в таблице 1, получим следующие значения:
TSS = 42854 – 10*602 = 6854; ESS = 1554,796;
RSS = 6854 – 1554,796 = 5299,204.
Тогда таблица дисперсионного анализа примет вид таблицы 3.
Таблица 3 – Результаты дисперсионного анализа
| Компоненты вариации | Сумма квадратов | Число степеней свободы | Средние квадраты | F -отношение |
| Регрессия | 5299,204 | 5299,204 | 
| |
| Остаточная | 1554,796 | 194,350 | ||
| Общая | 6854,000 |
При отсутствии линейной зависимости между переменными X и Y статистика  имеет распределение Фишера с числом степеней свободы v1 = 1; v2 = n – 2 = 8.
имеет распределение Фишера с числом степеней свободы v1 = 1; v2 = n – 2 = 8.
Принимая стандартный 5% уровень значимости, в таблице критических точек распределения Фишера находим Fкрит = F(0,05;1;8) = 5,32.
Поскольку Fрасч = 27,267 превышает Fкрит = 5,32, то делаем вывод о значимости уравнения регрессии.
7. Исправленные выборочные оценки стандартных отклонений (ошибок) МНК-коэффициентов регрессии вычисляются по формулам:


Используя результаты вычислений из предыдущих пунктов, получаем:
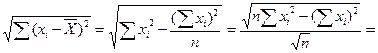
 ;
;
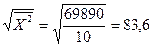 .
.
Отсюда:
 ;
;
 .
.
Доверительные интервалы для коэффициентов регрессии β1 и β0имеют соответственно вид:
[b1 – tкрит*S(b1);b1 + tкрит*S(b1)]; [b0 – tкрит*S(b0);b0 + tкрит*S(b0)].
Если окажется, что доверительный интервал включает 0, то соответствующий коэффициент регрессии объявляется незначимым.
При заданном уровне значимости a = 0,05 и числе степеней свободы, равном n – 2, где n – заданный объем выборки (у нас n = 10) критическое значение статистики Стьюдента tкрит = 2,31.
Теперь строим доверительные интервалы для β1 и β0 соответственно:
[2,302 – 2,31*0,441; 2,302 + 2,31*0,441] = [1,28; 3,32];
[–131,066 – 2,31*36,88; –131,066 + 2,31*36,88] = [–216,26; –45,87].
Поскольку ни один из полученных интервалов не включает нулевое значение, делаем вывод о значимом отличии от нуля коэффициентов β1 и β0.
8. Интервал для прогноза среднего значения зависимой переменной при значении объясняющей переменной x* (точнее, прогноза  ) по линейному уравнению регрессии имеет вид:
) по линейному уравнению регрессии имеет вид:
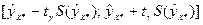 ,
,
где tγ находят по таблицам критических точек распределения Стьюдента для заданных значений g и числа степеней свободы v = n – 2 (в случае парной регрессии). Мы уже знаем, что при n = 10 и g = 0,95 (т.е. α = 0,05) tγ = 2,31.
Вычисляем 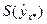 с учетом полученных ранее результатов:
с учетом полученных ранее результатов:
 .
.
Из выборочного уравнения прямой регрессии имеем:
 .
.
Получаем окончательный вид искомого доверительного интервала:

или
[54,21; 75,00].
Для расчета доверительного интервала возможных индивидуальных значений наблюдений при значении объясняющей переменной x* применяется формула:
 ,
,
где

 .
.
Окончательно получаем:
 =
=
=  .
.