Последовательный поиск
Постановка задачи
В информационных системах под задачей поиска понимают быстрое нахождение записи, содержащей необходимую информацию. Как и в случае сортировки, каждая запись имеет специальное поле, содержащее значение ключа, однозначно определяющего свою запись. Для упрощения задачи предполагается, что записи с одинаковыми ключами отсутствуют. Ключ, являющийся некоторым полем внутри записи, называется внутренним ключом. Ключи, хранящиеся в виде таблицы указателей на записи, называются внешними ключами. Возможны ключи:первичные, вторичные и ключи более высокого порядка (адрес абонента).
Пусть К есть некоторый массив из N ключей, а X - некоторый набор записей, такой, что K(I) является ключом записи X(I). Пусть А является некоторым аргументом поиска.
Алгоритмом поиска называется определенный алгоритм, который воспринимает некоторый аргумент А и исследует последовательность записей xL, xL+1,..., xp с тем, чтобы найти некоторую запись, ключ которой равен А.
Целью поиска является информация, содержащаяся в записи, ассоциированной с данным ключом. Интервал от L до P называется интервалом поиска.
При реализации алгоритма поиска существуют две возможности его
окончания:
1) либо поиск оказался удачным, т.е. позволил определить положение соответствующей записи, содержащей ключ А,
2) либо он оказался неудачным, т.е. показал, что аргумент А не может быть найден ни в одной из записей.
Различают методы поиска:
1) внешние и внутренние, статические и динамические, где статический
означает, что содержимое набора данных остается неизменным, а динами-
ческий означает, что набор является объектом частых вставок и удалений;
2) основанные на сравнении ключей и цифровых свойствах ключей;
3) использующие истинные ключи и работающие с преобразованными ключами.
Мы будем изучать внутренние, статические методы поиска, основанные
на просмотре записей и на сравнении их ключей.
Под последовательным поиском понимается просмотр записей в том порядке, в котором они встречаются в наборе данных. Он заключается в последовательном сравнении аргумента поиска А с ключом каждой записи. Этот метод можно использовать для поиска в упорядоченной и неупорядоченной последовательности записей. При этом, если набор неупорядоченный, то последовательный способ поиска является единственным.
В неупорядоченной последовательности сравненение ключей продолжается до тех пор, пока не будут просмотрены все N записей. Запись с искомым ключом выводится на печать.
Структурограмма алгоритма последовательного поиска в неупорядоченной последовательности записей приведена на рис
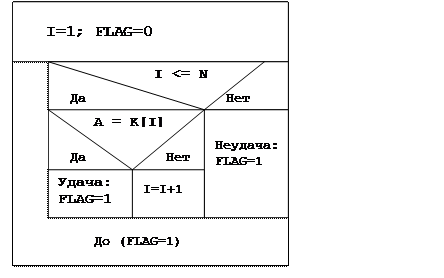
массиве ключей: 20 25 29 32 37.
i = 1:
Подчеркивание означает выбор Ki для сравнения с А.
i = 2: 20 25
i = 3: 20 25 29
Поиск окончен удачно, ключ 29 имеет порядковый номер, равный 3.
Пример реализации ?
function SearchPer (K : array of Integer; N, A : Integer) : Integer;var I : Integer;begin Result := -1; for I := 1 to N do if K [I] = A then begin Result := I; Exit; end;end;
Возможно ускорение работы последовательного поиска путем добавления в конец последовательности записей фиктивной записи XN+1 с ключом KN+1, равным аргументу поиска А. Структурограмма алгоритма
последовательного поиска в этом случае будет выглядеть так, как представлена на рис.
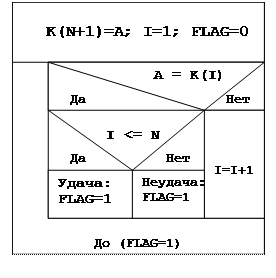
Выигрыш в быстродействии здесь достигается за счет того, что проверка на окончание последовательности записей выполняется лишь один раз - при совпадении аргумента поиска с ключом записи.
В последовательности, упорядоченной, например, по возрастанию ключей записей, поиск можно прекратить сразу же, как только значение ключа текущей записи превысит значение аргумента поиска.
Для ускорения в конец списка добавляют фиктивную запись XN+1 с ключом KN+1, превышающим аргумент поиска А. Рис. Пример (на обороте)
Если известно, что записи упорядочены, то существует несколько методов, которые могуть быть использованы для увеличения эффективности поиска.