Общая характеристика задач распознавания образов и их типы.
Под образом понимается структурированное описание изучаемого объекта или явления, представленное вектором признаков, каждый элемент которого представляет числовое значение одного из признаков, характеризующих соответствующий объект.
Общая структура системы распознавания имеет следующий вид:

Смысл задачи распознавания – установить, обладают ли изучаемые объекты фиксированным конечным набором признаков, позволяющих отнести их к определенному классу. Задачи распознавания имеют следующие характерные черты:
1. Это информационные задачи, состоящие из двух этапов:
a. Приведение исходных данных к виду, удобному для распознавания.
b. Собственно распознавание – указание принадлежности объекта определенному классу.
2. В этих задачах можно вводить понятие аналогии или подобия объектов и формулировать понятие близости объектов в качестве основания для зачисления объектов в один и тот же класс или разные классы.
3. В этих задачах можно оперировать набором прецедентов – примеров, классификация которых известна и которые в виде формализованных описаний могут быть предъявлены алгоритму распознавания для настройки на задачу в процессе обучения.
4. Для этих задач трудно строить формальные теории и применять классические математические методы: часто информация для точной математической модели или выигрыш от использования модели и математических методов несоизмерим с затратами.
5. В этих задачах возможна «плохая информация» - информация с пропусками, разнородная, косвенная, нечеткая, неоднозначная, вероятностная.
Целесообразно выделять следующие типы задач распознавания:
1. Задача распознавания, то есть отнесение предъявленного объекта по его описанию к одному из заданных классов (обучение с учителем).
2. Задача автоматической классификации – разбиение множества объектов (ситуаций) по их описаниям на систему непересекающихся классов (таксономия, кластерный анализ, обучение без учителя).
3. Задача выбора информативного набора признаков при распознавании.
4. Задача приведения исходных данных к виду, удобному для распознавания.
5. Динамическое распознавание и динамическая классификация – задачи 1 и 2 для динамических объектов.
6. Задача прогнозирования – задачи 5, в которых решение должно относиться к некоторому моменту в будущем.
Понятие образа.
Образ, класс – классификационная группировка в системе, объединяющая (выделяющая) определенную группу объектов по некоторому признаку. Образы обладают рядом характерных свойств, проявляющихся в том, что ознакомление с конечным числом явлений из одного и того же множества дает возможность узнавать сколь угодно большое число его представителей.
В качестве образа можно рассматривать и некоторую совокупность состояний объекта управления, причем вся эта совокупность состояний характеризуется тем, что для достижения заданной цели требуется одинаковое воздействие на объект. Образы обладают характерными объективными свойствами в том смысле, что разные люди, обучающиеся на различном материале наблюдений, большей частью одинаково и независимо друг от друга классифицируют одни и те же объекты.
В целом, проблема распознавания образов состоит из двух частей: обучение и распознавание.
Обучение осуществляется путем показа отдельных объектов с указанием их принадлежности тому или другому образу. В результате обучения распознающая система должна приобрести способность реагировать одинаковыми реакциями на все объекты одного образа и различными – на все объекты различных образов.
Очень важно, что процесс обучения должен завершиться только путем показов конечного числа объектов без каких-либо других подсказок. В качестве объектов обучения могут быть либо визуальные изображения, либо различные явления внешнего мира и другие.
За обучением следует процесс распознавания новых объектов, который характеризует действие уже обученной системы. Автоматизация этих процедур и составляет проблему обучения распознаванию образов. В том случае, когда человек сам разгадывает или придумывает, а затем навязывает ЭВМ правила классификации, проблема распознавания решается частично, так как основную и главную часть проблемы (обучение) человек берет на себя.
Проблема обучения распознаванию образов интересна как с прикладной, так и с принципиальной точки зрения. С прикладной точки зрения, решение этой проблемы важно прежде всего потому, что оно открывает возможность автоматизировать многие процессы, которые до сих пор связывали лишь с деятельностью живого мозга. Принципиальное значение проблемы связано с вопросом, что может и что принципиально не может делать ЭВМ.
При решении задач управления методами распознавания образов вместо термина «образ» применяется термин «состояние». Состояние – определенные формы отображения измеряемых текущих (мгновенных) характеристик наблюдаемого объекта, совокупность состояний определяет ситуацию.
Ситуацией принято называть некоторую совокупность состояний сложного объекта, каждое из которых характеризуется одними и теми же или схожими характеристиками объекта. Например, если в качестве объекта наблюдения рассматривается некоторый объект управления, то ситуация объединяет такие состояния этого объекта, в которых следует применять одни и те же управляющие воздействия. Если объектом наблюдения является игра, то ситуация объединяет все состояния игры.
Выбор исходного описания объектов является одной из центральных задач проблемы обучения распознаванию образов. При удачном выборе исходного описания (пространство признаков) задача распознавания может оказаться тривиальной. И наоборот, неудачно выбранное исходное описание может привести либо к очень сложной дальнейшей переработке информации, либо вообще к отсутствию решения.
Геометрический и структурный подходы.
Любое изображение, которое возникает в результате наблюдения какого-либо объекта в процессе обучения или экзамена, можно представить в виде вектора, а значит, и в виде точки некоторого пространства признаков.
Если утверждается, что при показе изображений возможно однозначно отнести их к одному из двух (или нескольких) образов, то тем самым утверждается, что в некотором пространстве существуют две или несколько областей, не имеющих общих точек, и что изображение точки из этих областей. Каждой точки такой области можно приписать наименование, то есть дать название, соответствующее образу.
Проинтерпретируем в терминах геометрической картины процесс обучения распознаванию образов, ограничившись пока случаем распознавания только двух образов. Заранее считается известным лишь то, что требуется разделить две области в некотором пространстве и что показываются точки только их этих областей. Сами эти области заранее не определены, то есть нет каких-либо сведений о расположении их границ или правил определения принадлежности точки к той или иной области.
В ходе обучения предъявляются точки, случайно выбранные из этих областей, и сообщается информация о том, к какой области принадлежат предъявляемые точки. Никакой дополнительной информации об этих областях, то есть о расположении их границ в ходе обучения не сообщается.
Цель обучения состоит либо в построении поверхности, которая разделяла бы не только показанные в процессе обучения точки, но и все остальные точки, принадлежащие этим областям, либо в построении поверхностей, ограничивающих эти области так, чтобы в каждой из них находились только точки одного образа. Иначе говоря, цель обучения состоит в построении таких функций от векторов-изображений, которые были бы, например, положительны на всех точках одного и отрицательны на всех точках другого образа.
В связи с тем, что области не имеют общих точек, всегда существует целое множество таких разделяющих функций, а в результате обучения должна быть построена одна из них. Если предъявляемые изображения принадлежат не двум, а большему числу образов, то задача состоит в построении по показанным в ходе обучения точкам поверхности, разделяющей все области, соответствующие этим образам, друг от друга.
Эта задача может быть решена, например, путем построения функции, принимающей над точками каждой из областей одинаковое значение, а над точками из разных областей значение этой функции должно быть различно.
Может показаться, что знания всего лишь некоторого количества точек из области недостаточно, чтобы отделить всю область. Действительно можно указать бесчисленное количество различных областей, которые содержат эти точки, и как бы ни была построена по ним поверхность, выделяющая область, всегда можно указать другую область, которая пересекает поверхность и вместе с тем содержит показанные точки.
Однако известно, что задача о приближении функции по информации о ней в ограниченном множестве точек является существенно более узкой, чем все множество, на котором функция задана, и является обычной математической задачей об аппроксимации функций. Разумеется, решение таких задач требует введения определенных ограничений на классе рассматриваемых функций, а выбор этих ограничений зависит от характера информации, которую может добавить учитель в процесс обучения.
Одной из таких подсказок является гипотеза о компактности образов.
Наряду с геометрической интерпретацией проблемы обучения распознаванию образов, существует и иной подход, который назван структурным, или лингвистическим. Рассмотрим лингвистический подход на примере распознавания зрительных изображений.
Сначала выделяется набор исходных понятий – типичных фрагментов, встречающихся на изображении, и характеристик взаимного расположения фрагментов (слева, снизу, внутри и т.д.). Эти исходные понятия образуют словарь, позволяющий строить различные логические высказывания, иногда называемые предложениями.
Задача состоит в том, чтобы из большого количества высказываний, которые могли бы быть построены с использованием этих понятий, отобрать наиболее существенные для данного конкретного случая. Далее, просматривая конечное и по возможности небольшое число объектов из каждого образа, нужно построить описание этих образов.
Построенные описания должны быть столь полными, чтобы решить вопрос о том, к какому образу принадлежит данный объект. При реализации лингвистического подхода возникают две задачи: задача построения исходного словаря, то есть набора типичных фрагментов, и задача построения правил описания из элементов заданного словаря.
В рамках лингвистической интерпретации проводится аналогия между структурой изображений и синтаксисом языка. Стремление к этой аналогии было вызвано возможностью использовать аппарат математической лингвистики, то есть методы по своей природе являются синтаксическими. Использование аппарата математической лингвистики для описания структуры изображений можно применять только после того, как произведена сегментация изображений на составные части, то есть выработаны слова для описания типичных фрагментов и методы их поиска.
После предварительной работы, обеспечивающей выделение слов, возникают собственно лингвистические задачи, состоящие из задач автоматического грамматического разбора описаний для распознавания изображений.
Гипотеза компактности.
Если предположить, что в процессе обучения пространство признаков формируется исходя из задуманной классификации, то тогда можно надеяться, что задание пространства признаков само по себе задает свойство, под действием которого образы в этом пространстве легко разделяются. Именно эти надежды по мере развития работ в области распознавания образов стимулировали появление гипотезы компактности, которая гласит: образам соответствуют компактные множества в пространстве признаков.
Под компактным множеством будем понимать некие сгустки точек в пространстве изображений, предполагая, что между этими сгустками существуют разделяющие их разряжения. Однако эту гипотезу не всегда удавалось подтвердить экспериментально. Но те задачи, в рамках которых гипотеза компактности хорошо выполнялась, всегда находили простое решение и наоборот, те задачи, для которых гипотеза не подтверждалась, либо совсем не решались, либо решались с большим трудом и привлечением дополнительной информации.
Сама гипотеза компактности превратилась в признак возможности удовлетворительно решения задач распознавания.
Формулировка гипотеза компактности подводит вплотную к понятию абстрактного образа. Если координаты пространства выбирать случайно, то и изображения в нем будут распределены случайно. Они будут в некоторых частях пространства располагаться более плотно, чем в других.
Назовем некоторое случайно выбранное пространство абстрактным изображением. В этом абстрактном пространстве почти наверняка будут существовать компактные множества точек. Поэтому, в соответствии с гипотезой компактности, множество объектов, которым в абстрактном пространстве соответствуют компактные множества точек, принято называть абстрактными образами заданного пространства.
Обучение и самообучение, адаптация и обучение.
Если бы удалось подметить некое всеобщее свойство, не зависящее ни от природы образов, ни от их изображений, а определяющее лишь способность к разделимости, то наряду с обычной задачей обучения распознаванию с использованием информации о принадлежности каждого объекта из обучающей последовательности тому или иному образу, можно было бы поставить иную классификационную задачу – так называемую задачу обучения без учителя.
Задачу такого рода на описательном уровне можно сформулировать следующим образом: системе одновременно или последовательно предъявляются объекты без каких-либо указаний об их принадлежности к образам. Входное устройство системы отображает множество объектов на множество изображений и, используя некоторое заложенное в нем заранее свойство разделимости образов, производит самостоятельную классификацию этих объектов.
После такого процесса самообучения система должна приобрести способность к распознаванию не только уже знакомых объектов (объектов из обучающей последовательности), но и тех, которые ранее не предъявлялись. Процессом самообучения некоторой системы называется такой процесс, в результате которого эта система без подсказки учителя приобретает способность к выработке одинаковых реакций на изображения объектов одного и того же образа и различных реакций на изображения различных образов.
Роль учителя при этом состоит лишь в подсказке системе некоторого объективного свойства, одинакового для всех образов и определяющего способность к разделению множества объектов на образы.
Оказывается, таким объективным свойством является свойство компактности образов. Взаимное расположение точек в выбранном пространстве уже содержит информацию о том, как следует разделить множество точек. Эта информация и определяет то свойство разделимости образов, которое оказывается достаточным для самообучения системы распознаванию образов.
Большинство известных алгоритмов самообучения способны выделять только абстрактные образы, то есть компактные множества в заданных пространствах. Различие между ними состоит в формализации понятия компактности. Однако это не снижает, а иногда и повышает ценность алгоритмов самообучения, так как часто сами образы заранее никем не определены, а задача состоит в том, чтобы определить, какие подмножества изображений в заданном пространстве представляют собой образы.
Примером такой постановки задачи являются социологические исследования, когда по набору вопросов выделяются группы людей. В таком понимании задачи алгоритмы самообучения генерируют заранее неизвестную информацию о существовании в заданном пространстве образов, о которых ранее никто не имел никакого представления.
Кроме того, результат самообучения характеризует пригодность выбранного пространства для конкретной задачи обучения распознаванию. Если абстрактные образы, выделяемые в пространстве самообучения, совпадают с реальными, то пространство выбрано удачно. Чем сильнее абстрактные образы отличаются от реальных, тем неудобнее выбранное пространство для конкретной задачи.
Обучением обычно называют процесс выработки в некоторой системе той или иной реакции на группы внешних идентичных сигналов путем многократного воздействия на систему внешней корректировки. Механизм генерации этой корректировки практически полностью определяет алгоритм обучения.
Самообучение отличается от обучения тем, что здесь дополнительная информация о верности реакции системе не сообщается.
Адаптация – процесс изменения параметров и структуры системы, а возможно, и управляющих воздействий, на основе текущей информации с целью достижения определенного состояния системы при начальной неопределенности и изменяющихся условиях работы.
Обучение – процесс, в результате которого система постепенно приобретает способность отвечать нужными реакциями на определенные совокупности внешних воздействий, а адаптация – подстройка параметров и структуры системы с целью достижения требуемого качества управления в условиях непрерывных изменений внешних условий.
Системы распознавания речи.
Речь выступает в роли основного средства коммуникации между людьми и поэтому речевое общение считается одним из важнейших компонентов системы искусственного интеллекта. Распознавание речи представляет собой процесс преобразования акустического сигнала, формируемого на выходе микрофона или телефона, в последовательность слов.
Более сложной задачей является задача понимания речи, которая сопряжена с выявлением смысла акустического сигнала. В этом случае выход подсистемы распознавания речи служит входом подсистемы понимания высказываний. Автоматическое распознавание речи (системы АРР) является одним из направлений технологий обработки естественного языка.
Автоматическое распознавание речи применяется при автоматизации ввода текстов в ЭВМ, при формировании устных запросов к базам данных или информационно-поисковым системам при формировании устных команд различным интеллектуальным устройствам.
Основные понятия систем распознавания речи.
Системы распознавания речи характеризуются многими параметрами.
Одним из основных параметров является ошибка распознавания слов (ОРС). Этот параметр представляет собой отношение количества нераспознанных слов к общему количеству произнесенных слов.
Другими параметрами, характеризующими системы автоматического распознавания речи, являются:
1) размер словаря,
2) режим речи,
3) стиль речи,
4) предметная область,
5) дикторозависимость,
6) уровень акустических шумов,
7) качество входного канала.
В зависимости от размера словаря системы АРР подразделяются на три группы:
- с малым размером словаря (до 100 слов),
- со средним размером словаря (от 100 слов до нескольких тысяч слов),
- с большим размером словаря (более 10 000 слов).
Режим речи характеризует способ произнесения слов и фраз. Выделяют системы распознавания слитной речи и системы, позволяющие распознавать только изолированные слова речи. В режиме распознавания изолированных слов требуется, чтобы диктор делал краткие паузы между словами.
По стилю речи системы АРР подразделяются на две группы: системы детерминированной речи и системы спонтанной речи.
В системах распознавания детерминированной речи диктор воспроизводит речь, следуя грамматическим правилам языка. Спонтанная речь характеризуется нарушениями грамматических правил и ее сложнее распознавать.
В зависимости от предметной области выделяют системы АРР, ориентированные на применение в узкоспециальных областях (например, доступ к базам данных) и системы АРР с неограниченной областью применения. Последние требуют наличия большого объема словаря и должны обеспечивать распознавание спонтанной речи.
Многие системы автоматического распознавания речи являются дикторозависимыми. Это предполагает предварительную настройку системы на особенности произношения конкретного диктора.
Сложность решения задачи распознавания речи объясняется большой изменчивостью акустических сигналов. Эта изменчивость объясняется несколькими причинами:
Во-первых, различной реализацией фонем – основных единиц звукового строя языка. Изменчивость реализации фонем вызвана влиянием соседних звуков в потоке речи. Оттенки реализации фонем, обусловленные звуковым окружением, называют аллофонами.
Во-вторых, положением и характеристиками акустических приемников.
В-третьих, изменениями параметрами речи одного и того же диктора, которые обусловлены различным эмоциональным состоянием диктора, темпом его речи.
На рисунке представлены основные компоненты системы распознавания речи:
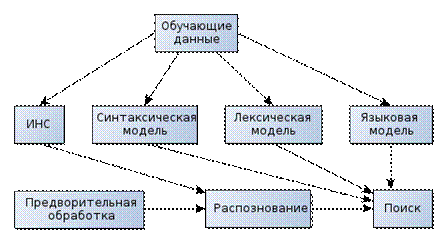
Оцифрованный речевой сигнал поступает на блок предварительной обработки, где осуществляется выделение признаков, необходимых для распознавания звуков. Распознавание звуков часто осуществляется с помощью моделей искусственных нейронных сетей. Выделенные звуковые единицы используют в дальнейшем для поиска последовательности слов, в наибольшей степени соответствующей входному речевому сигналу.
Поиск последовательности слов выполняется с помощью акустической, лексической и языковой моделей. Параметры моделей определяют по обучающим данным на основе соответствующих алгоритмов обучения.
Синтез речи по тексту. Основные понятия
Во многих случаях создание систем искусственного интеллекта с элементами ея-общения требуют вывода сообщений в речевой форме. На рисунке представлена структурная схема интеллектуальной вопросно-ответной системы с речевым интерфейсом:
Рисунок 1.
Кусок лекций взять у Олега
Рассмотрим особенности эмпирического подхода на примере распознавания частей речи. Задача состоит в присвоении словам предложения меток: существительное, глагол, предлог, прилагательное и тому подобное. Кроме этого, необходимо определять некоторые дополнительные признаки существительных и глаголов. Например, для существительного – число, а для глагола – форму. Формализуем задачу.
Представим предложение в виде последовательности слов: W=w1 w2…wn, где wn – случайные переменные, каждая из которых получает одно из возможных значений, принадлежащих словарю языка. Последовательность меток, назначаемых словам предложения, представим последовательностью X=x1 x2 … xn, где xn – случайные переменные, значения которых определены на множестве возможных меток.
Тогда задача распознавания частей речи состоит в поиске наиболее вероятной последовательности меток x1, x2, …, xn по заданной последовательности слов w1, w2, …, wn. Иными словами, необходимо найти такую последовательность меток X*=x1 x2 … xn, которая обеспечивает максимум условной вероятности P(x1, x2, …, xn| w1 w2.. wn).
Перепишем условную вероятность P(X| W) в следующем виде P(X| W)=P(X,W) / P(W). Так как требуется найти максимум условной вероятности P(X,W) по переменной X, получим X*=argx max P(X,W). Совместную вероятность P(X,W) можно записать в виде произведения условных вероятностей: P(X,W)=произведение по и-1 до н от P(xi|x1,…,xi-1, w1,…,wi-1) P(wi|x1,…,xi-1, w1,…,wi-1). Непосредственный поиск максимума данного выражения представляет собой сложную задачу, так как при больших значениях n поисковое пространство становится очень большим. Поэтому вероятности, которые записаны в этом произведении, аппроксимируют более простыми условными вероятностями: P(xi|xi-1) P(wi|wi-1). В этом случае полагают, что значение метки xi связано только с предыдущей меткой xi-1 и не зависит от более ранних меток, а также что вероятность слова wi определяется только текущей меткой xi. Указанные предположения называют марковскими, а для решения задачи привлекают теорию марковских моделей. С учетом марковских предположений можно записать:
X*= arg x1, …, xn max Пi=1n P(xi|xi-1) P(wi|wi-1)
Где условные вероятности оцениваются на множестве обучающих данных
Поиск последовательности меток Х* осуществляют с помощью алгоритма динамического программирования Витерби. Алгоритм Витерби может рассматриваться как вариант алгоритма поиска на графе состояний, где вершинам соответствуют метки слов.
Характерно, что для любой текущей вершины множество дочерних меток всегда одно и то же. Более того, для каждой дочерней вершины множества родительских вершин тоже совпадают. Это объясняется тем, что на графе состояний осуществляются переходы с учетом всех возможных сочетаний меток. Предположение Маркова обеспечивают существенное упрощение задачи распознавания частей речи при сохранении высокой точности назначения меток словам.
Так, при наличии 200 меток точность назначения примерно равна 97%. Долгое время имперический анализ выполнялся с помощью стохастических контекстно-свободных грамматик. Однако для них характерен существенный недостаток. Он заключается в том, что различным грамматическим разборам могут назначаться одинаковые вероятности. Это происходит из-за того, что вероятность грамматического разбора представляется в виде произведения вероятностей правил, участвующих в разборе. Если в ходе разбора используются различные правила, характеризуемые одинаковыми вероятностями, то это и порождает указанную проблему. Лучшие результаты дает грамматика, учитывающая лексику языка.
В этом случае в правила включаются необходимые лексические сведения, которые обеспечивают различные значения вероятности для одного и того же правила в разных лексических окружениях. Имперический синтаксический анализ в большей степени соответствует распознаванию образов, чем традиционному грамматическому разбору в его классическом понимании.
Сравнительные исследования показали, что правильность имперического грамматического разбора приложений естественного языка оказывается выше по сравнению с традиционным грамматическим разбором.