Документальные БД
Резюме
· Оперативная аналитическая обработка данных (технология OLAP) предусматривает динамический синтез, анализ и консолидацию многомерных данных большого объема.
· Приложения OLAP применяются в различных функциональных областях, таких как планирование расходов, анализ финансовых результатов, анализ и прогнозирование сбыта, аналитические исследования рынка и сегментация рынков/клиентов.
· Основные характеристики приложений OLAP включают многомерные представления данных, поддержку сложных вычислений и правильный учет фактора времени.
· В базах данных OLAP для хранения данных и представления связей между ними используются многомерные структуры. Многомерные структуры проще всего представить в виде кубов данных . Каждая сторона куба рассматривается как отдельная размерность.
Реляционная модель данных, в основе которой лежит табличное представление данных, очень хорошо подходит для создания фактографических БД. Однако она может с успехом использоваться и для разработки документальных БД. В частности, хорошие возможности для создания документальных БД предоставляет современная СУБД SQL Server.
Организация данных и механизмы поиска в документальных БД имеют существенные отличия, которые обусловлены в первую очередь характером хранимой и обрабатываемой информации.
Фактографические системы хранят хорошо структурированные сведения (факты). Соответственно и запросы к ним носят более четкий (определенный) характер. Например, запрос к БД, содержащей сведения о сотрудниках предприятия, может быть таким: найти должность, оклад и телефон сотрудника Иванова.
Документальные системы хранят не факты, а документы, содержащие эти факты. Соответственно наш запрос о сотруднике может выглядеть следующим образом: найти документы, содержащие сведения о должности, окладе и телефоне сотрудника Иванова.
Иными словами, запись документальной базы данных — это документ (обычно большого размера), который задается как набор в общем случае необязательных полей (например, аннотаций, глав, разделов, подразделов и т.д.), для каждого из которых определены имя и тип.
C точки зрения поиска атомарным (семантически значимым) элементом данных является слово. Вследствие этого поисковые структуры строятся в виде инвертированных файлов.
Обычно система присваивает каждому документу уникальный номер; каждому ключевому слову документа ставится в соответствие указатель на списки экземпляров, являющихся перечнем документов, в которых встречается данное слово (то есть создается индекс). Каждый список экземпляров содержит заголовок, из которого можно узнать число экземпляров слова во всем файле документов, а также число документов, в которых это слово встречается.
Поисковый критерий (критерий поиска документов) может включать в себя разные слова, причем пользователь может потребовать, чтобы заданное слово встречалось в названии документа, аннотации, введении или в каком-то конкретном параграфе.
Независимо от содержания критерия отбора поиск документа (в большинстве случаев) осуществляется на уровне списка экземпляров без необходимости входа в файл документов.
Документальная БД включает в себя как минимум три области хранения данных, представляемые из-за своего большого размера, как правило, в виде файлов операционной системы (в действительности их всегда больше) :
• файл словаря, устанавливающий соответствие между словом, встречающимся в БД, и его кодом;
• инверсный (инвертированный, обратный) список, содержащий для каждого слова БД список документов, его содержащих, используется при текстовом поиске;
• текстовый файл, содержащий собственно документы, используется при выдаче (просмотре) документов.
На рис.21. 1 приведена принципиальная схема организации поиска документов, характерная для большинства современных документальных БД.
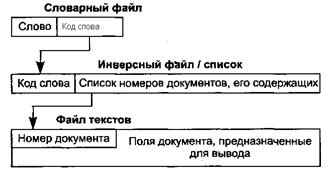
Рис.21. 1 Принципиальная схема поиска документов в документальных БД
Рассмотрим пример упрощенной реализации документальной БД в среде реляционной СУБД. С логической точки зрения она имеет «стандартную» структуру и включает две компоненты: регистрационные карты (РК) и полные тексты (ПТ).

Рис. 21.2 Логическая структура документальной БД
Регистрационные карты представляют собой форматированные записи, содержащие относительно стандартный набор библиографических данных, а также ссылку на соответствующий полный текст (рис.21.2).
Полные тексты документов состоят из страниц двух типов:
• логических, т. е. структурных единиц текста — пункт, параграф, статья;
• физических — принудительное разбиение длинного неструктурированного текста на фрагменты одинаковой длины.

Рис21. 3 Физическая структура документальной БД и виды поиска документов
Таблица ПТ — одна или несколько таблиц, в которых содержатся полные тексты документов. На логическом уровне образует представленную на рис.2 иерархическую структуру: БД, документ, страница.
Словарь ПТ — таблица представляет собой список ключевых слов и стандартных словосочетаний (например, «статья 256», «п. 13», «N 1400-РП»), извлеченных из текста, сопровождаемых частотами появления.
Инверсная таблица ПТ (или инверсный список ПТ) — таблица, содержащая список ключевых слов и словосочетаний, сопровождаемых номерами страниц.
Словарная и инверсная таблицы используются для сквозного полнотекстового поиска.
Таблица РК - таблица регистрационных карт, каждая запись которой содержит заглавие, дату регистрации, номер, вид документа, ссылки на страницы полного текста (ПТ) и другие поля.
Словарь РК - это таблица, содержащая значения полей регистрационных карт совместно с частотой появления и ссылками на записи таблицы РК.
Инверсная таблица РК (или инверсный список РК) содержит слова и словосочетания и ссылки на записи таблицы РК.
Словарная и инверсная таблицы используются для поиска записей РК, с последующим доступом к страницам полного текста (ПТ).
Наряду со словарем РК иногда может использоваться словарь синонимов, служащий для обеспечения двуязычного поиска в словарных таблицах.
Поиск документов по БД может быть двух видов: поиск по РК и поиск по ПТ.
Первый вид поиска соответствует случаю, когда пользователь что-то знает о документе, например, название, автора, дату выпуска и т.д. Самый простой случай, когда пользователь знает все. Тогда просто анализируется таблица РК, из нее отбирается нужная регистрационная карта, из которой отбирается указатели на страницы полного текста документа. Далее эти страницы выбираются из таблицы ПТ.
Несколько сложнее поиск в случае, когда пользователь знает только часть атрибутов регистрационной карты, например, только одно название или только словосочетание из названия. В этом случае предварительно анализируется словарь и инверсная таблица РК, после чего отыскивается сама РК.
Поиск по ПТ соответствует ситуации, когда пользователь ничего не знает о документе и может указать только ключевые слова для него. В этом случае прежде всего используется инверсная таблица ПТ, из которой отыскивается список страниц, содержащих эти слова. Если такой список оказывается очень велик, может быть использован словарь ПТ, позволяющий сократить его в соответствии с частотой появления слов.
Несложно видеть, что инверсные таблицы – это таблицы адекватные по назначению и структуре индексам. С той лишь разницей, что они видны пользовательской программе, а индексы нет. Именно возможность видеть содержимое инверсной таблицы позволяет пользовательской программе анализировать его совместно со словарем ПТ.
Таблица РК является обычной таблицей с символьными полями.
Таблицы словарей и инверсные таблицы содержат данные типа BLOB: то есть списки слов (словосочетаний) и списки указателей хранятся не в самой таблице, а в другой табличной области, отличной от табличной области для словаря или инверсного списка.
Таблица ПТ содержит данные типа BFILE, т.е. тексты страниц документов хранятся в файлах операционной системы.
Лекция 10