I. Краткие сведения из теории статистики
ППП статистической обработки данных
Результаты статистического наблюдения – это таблицы, а также ряды распределения по определенному признаку. Ряд характеризует
· состояние явления
· границы
· однородность
· законы развития
По признаку ряды делятся на:
· Атрибутивные
· Вариационные, которые по характеру вариации делятся на:
o Дискретные (прерывные)
o Интервальные (непрерывные)
Для отображения дискретных вариационных рядов используются полигоны. Х – значения признака, Y – частота его появления
Ломаная линия называется полигоном частот

 Пример распределение числа квартир по числу комнат.
Пример распределение числа квартир по числу комнат.
| Число комнат | Число квартир |
| Всего 100 |
Для отображения интервальных вариационных рядов используются гистограммы
Преобразовать гистограмму в полигон можно, соединив отрезками линий середины верхних сторон прямоугольников.


| Площадь в кв.м на 1 человека | Число семей | Число семей нарастающим итогом |
| 3-5 | ||
| 5-7 | ||
| 7-9 | ||
| 9-11 | ||
| 11-13 | ||
| итого |
Кумулятивный ряд (кумулята) – это накопленные частоты или функция распределения. Кумулята:

Если используются неравные интервалы признака, то определяется плотность статистического распределения (сколько значений частоты в каждой интервальной группе приходится на единицу величины интервала) и высота прямоугольников показывается пропорционально плотности распределения
Пример распределения магазинов по товарообороту
| Товарооборот, тыс. руб. | Число магазинов | Интервал, тыс. руб. | Плотность распределения = (число магазинов) / интервал |
| До 50 | 0,5 | ||
| 50-120 | 0,64 | ||
| 120-250 | 0,5 | ||
| 250-450 | 0,4 | ||
| 450-980 | 0,04 | ||
| итого |
Полигон – это плотность распределения
 Вывод – чаще всего встречаются магазины с товарооборотом 250-450 тыс.руб. Это неверно.
Вывод – чаще всего встречаются магазины с товарооборотом 250-450 тыс.руб. Это неверно.
Чаще всего встречаются магазины с товарооборотом 50-12- тыс.руб.

Общее представление о значениях переменной дают описательные статистики:
· Минимум
· Максимум
· Среднее (сумма значений переменной, поделенная на число значений)

выполняется равенство 
· Дисперсия (изменяется от 0 до бесконечности. 0 означает что переменные постоянны, изменений нет)

· Стандартное отклонение (Это корень квадратный из дисперсии. Чем выше дисперсия и стандартное отклонение, тем сильнее разбросаны значения переменной относительно среднего)
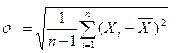
· и др.
Два вида случайных величин:
· Независимая – Х (фактор)
· Зависимая – Y (результативный признак)
Для определения аналитического выражения связи между независимой и зависимой случайными величинами используется регрессионный анализ. Форма связи – это уравнение регрессии.
Виды регрессии:
· Парная – исследуются 2 величины фактор и результативный признак), например y=a+bx для линейной регрессии
· Множественная – исследуются несколько факторов и результативный признак, например y=a0+a1x1+a2x2+…+anxn для линейной регрессии
Для составления прогнозов может быть использовано уравнение регрессии, в котором определяются коэффициенты, называемые параметрами регрессии. Построенная линия уравнения регрессии называется линией тренда, которая показывает тенденцию изменения данных. Для создания линии тренда используются следующие виды аппроксимации:
· Линейная - ŷ=ax+b, a – тангенс угла наклона, b – точка пересечения с осью ординат
· Логарифмическая – ŷ =c lnx+b, где c, b - константы
· Полиномиальная – ŷ =c6x6+…+c1x+b, где c6,…c1, b -
· Степенная – ŷ =cxb, где c, b - константы
· Экспоненциальная - ŷ =cebx, где c, b - константы
Достоверность аппроксимации определяется коэффициентом корреляции, характеризующим связь между двумя множествами в уравнении линейной регрессии. Если R2 лежит в диапазоне от 0,9 до 1, то можно применить линейное уравнение регрессии. Если R2 близко к –1, то между наблюдаемыми зависимостями обратная зависимость. При других видах аппроксимации используется индекс корреляции (R2 теряет смысл)
При R2 <=0,3 – слабая линейная связь,
R2 =0,3 –0,5 – умеренная линейная связь,
R2 =0,5 –0,7 – средняя или заметная линейная связь,
R2 >=0,7 – сильная или высокая линейная связь,
R2 >=0,9 – очень сильная или весьма высокая линейная связь,
R2=1 – полная функциональная зависимость, все точки на прямой
Для определения степени влияния факторов на результативный признак используется дисперсия следующих видов:
· Общая дисперсия – показывает степень влияния основных и остаточных факторов, где yi – значение результативного признака, n –число наблюдений (значений результативного признака)

· Факторная дисперсия - показывает степень влияния основных факторов

· Остаточная дисперсия - показывает степень влияния остаточных факторов. m – число факторов (остаток – это разница между реальными значениями и теоретическими прогнозируемыми)

Если существует корреляционная связь, то выполняется соотношение:

При анализе множественной регрессией используется множественный коэффициент детерминации R2, называемый также квадратом коэффициента множественной корреляции R и определяет долю вариации результативного признака, обусловленную изменением факторов.
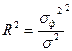
При R2>0,7 (критерий Фишера) считается, что вариация обусловлена влиянием факторов.
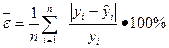 Также используется для оценки результата аппроксимации средняя ошибка аппроксимации:
Также используется для оценки результата аппроксимации средняя ошибка аппроксимации:
Если некоторые параметры регрессии малы по сравнению со стандартной ошибкой, то их можно исключить из анализа.
Для определения значимости результата используется p-уровень, характеризующий вероятность ошибки. Обычно принимается p-уровень <= 0,05, т.е. ошибка должна быть не более 5%.
Статистические методы обработки данных используются во многих ППП, например, Excel, QuattroPro, Lotus 1-2-3, MathCAD. Большими возможностями обладают специализированные ППП статистической обработки данных, предназначенные для специалистов со специальной подготовкой в области теории статистики. К ним относятся:
· ППП SPSS – разработчик SPSS inc.
· ППП STATISTICA используется в экономической статистике, финансах, научных исследованиях, производстве (разработчик StatSost)