Поиск источников информации
Метапоисковая машина
Адреса наиболее популярных поисковых машин за рубежом и в России.
Зарубежные поисковые машины:
Google - http://www.google.com/
Altavista - http://www.altavista.com/
Excite - http://www.excite.com/
HotBot -http://www.hotbot.com/
Nothern Light - http://www.northernlight.com/
Go (Infoseek) - http://www.go.com/(infoseek.com)
Fast - http://www.alltheweb.com/
Российские поисковые машины:
Яndex - http://www.yandex.ru/ (илиhttp://www.ya.ru/)
Рэмблер - http://www.rambler.ru/
Апорт - http://www.aport.ru/
Метапоисковая система. Обратите внимание на то, что различные поисковые системы описывают разное количество источников информации в Интернет. Поэтому нельзя ограничиваться поиском только в одной из указанных поисковых системах. Теперь познакомимся с инструментами поиска, которые не формируют собственный индекс, но умеют использовать возможности других поисковых систем. Это метапоисковые системы (поисковые службы) - системы, способные послать запросы пользователя одновременно нескольким поисковым серверам, затем объединить полученные результаты и представить их пользователю в виде документа со ссылками.
Адреса известных метапоисковых систем:
MetaCrawler - http://www.metacrawler.com/
SavvySearch - http://www.savvysearch.com/
Обсудим проблему поиска такого источника информации, как статьи в группах новостей. Инструментами поиска в данном случае могут являться рассмотренные поисковые машины WWW, которые индексируют не только пространство WWW, но и статьи в телеконференциях и имеют специальный режим поиска именно в этом ресурсе. Поиск в группах новостей поддерживает, например, поисковый сервер Altavistа. Следует отметить, что поисковые системы WWW весьма оперативно индексируют группы новостей и содержат информацию о статьях, реально существующих в сети. Для поиска в архивах новостей существую специализированные системы, самой известной из которых является система Deja (www.deja.com). Эта система позволяет проводить как поиск отдельных статей, содержащих введенный термин, так и поиск определенных групп новостей, посвященных обсуждению заданной темы. Можно зарегистрироваться в Deja и подписаться на определенные группы новостей.
Теперь рассмотрим инструменты, позволяющие проводить поиск файлов. Многие поисковые системы WWW стали оказывать услугу поиска мультимедийных файлов (Altavista, Aport). Для этого вовсе нет необходимости знать специальные операторы, а достаточно перейти с домашней страницы по ссылкам Картинки (Images), MP3/Audio или Video к специальному режиму поиска. Поиск проводится по возможному имени файла или по тексту в комментарии к ссылке на мультимедийный файл.
Что касается поиска программного обеспечения, во всемирной паутине существуют поисковые Web-серверы с коллекциями условно-бесплатного ПО, некоторые из них специализируются на поиск программного обеспечения для Интернета или для конкретной операционной системы. Эти системы в конечном итоге приведут вас к конкретному серверу, с которого и можно скачать искомый программный продукт. Следует упомянуть серверы Archie, также оказывающие услугу поиска файлов на FTP-серверах, однако пользоваться Web-серверами гораздо удобнее.
Рассмотрим поисковые инструменты для поиска адресной информации. Введем понятие Белого(White) и Желтого (Yellow) поиска.
White-поиск - поиск адресной информации по заранее известному собственному имени адресата (имя человека или организации)
Yellow-поиск - поиск собственного имени по дополнительным признакам (по роду деятельности, по географическому признаку), а затем поиск его адресной информации.
Обычно Yellow Pages системы фактически сразу включают в себя и White Pages - у найденного адресата сразу видны его телефон и почтовый адрес. Кроме того, некоторые Yellow Pages позволяют искать просто в алфавитном списке своих абонентов (white-поиск). С другой стороны, White pages также содержат элементы yellow-поиска - кроме задания собственного имени они обычно позволяют указать название города, штата и другие, сужающие поиск, данные (что необходимо в случае многих однофамильцев). Возможно, именно поэтому многие on-line телефонные справочники, выполняющие, фактически white-поиск, называют себя Yellow pages.
Здесь приведены адреса Web-систем для поиска адресной информации для людей и организаций.
Поиск людей:
- Поиск людей на Yahoo(http://people.yahoo.com/).
- Система WhoWhere(http://www.whowhere.com/).
- Система Bigfoot(http://www.bigfoot.com/).
Поиск организаций: раздел Желтые страницы (Yellow pages) на поисковых системах
специализированные сервераhttp://www.yellowpages.com/ - для поиска в США и других странах.
Технологии работы с WWW.
В течение последних лет предпринималось немало попыток разработать концепцию универсальной информационной базы данных, в которой можно было бы не только получать информацию из любой точки земного шара, но и иметь удобный способ связи информационных сегментов друг с другом, так чтобы наиболее важные данные быстро могли быть найдены. В 60-е годы исследования в этой области породили понятие «информационной Вселенной» (docuverse = documentation + universe), которая преобразила бы всю информационную деятельность, в частности в области образования. Но только в настоящее время появилась технология, воплотившая эту идею и предоставляющая возможности ее реализации в масштабах планеты.
WWW — это аббревиатура от «World Wide Web» («Всемирная паутина»). Официальное определение World Wide Web звучит как мировая виртуальная файловая система — «широкомасштабная гипермедиа-среда, ориентированная на предоставление универсального доступа к документам».
Проект WWW возник в начале 1989 г. в Европейской Лаборатории физики элементарных частиц (European Laboratory for Particle Physics (CERN) in Geneva, Switzerland). Основное назначение проекта — предоставить пользователям не профессионалам «on-line» доступ к информационным ресурсам. Результатом проекта World Wide Web (WWW, W3) является предоставление пользователям сетевых компьютеров достаточно простого доступа к самой разнообразной информации.
Используя популярный программный интерфейс, проект WWW изменил процесс просмотра и создания информации. Идея заключается в том, что по всему миру хаотично разбросаны тысячи информационных серверов и любую машину, подключенную к Internet в режиме on-line, можно преобразовать в сервер и начинить его информацией. С любого компьютера, подключенного к Internet, можно свободно установить сетевое соединение с таким сервером и получать от него информацию.
Первый такой сервер был организован в CERN'e, там же с целью развития и поддержки стандартов WWW-технологий создан The World Wide Web Consortium (или W3C). WWW-сервер The W3C's Web site является интегрирующим сервером по поддержке WEB-технологий Internet.
Позднее к проекту подключились и многие другие организации. Большой вклад в развитие WWW-технологий внес Национальный центр суперкомпьютерных приложений (National Centre for Super-computing Applications —NCSA).
Информационный WWW-сервер использует гипертекстовую технологию. Для записи документов в гипертексте используется специальный, но очень простой язык HTML (Hypertext Markup Language), который позволяет управлять шрифтами, отступами, вставлять цветные иллюстрации, поддерживает вывод звука и анимации. В стандарт языка также входит поддержка математических формул.
Представление о гипертексте. Внешне гипертекст отличается от обычного текста тем, что часть слов или целые строки в нем, будучи выделены особым шрифтом или цветом, оказываются чувствительными к появлению на них указателя манипулятора «мышь». При попадании на такую область текста указатель (часто стрелочка) изменяет первоначальный вид, становясь, например, ладошкой. Щелчок «мыши» в таком положении приводит к инициированию какого-либо события, чаще всего к загрузке в программу просмотра нового документа, привязанного так называемой гипертекстовой ссылкой к выделенной строке текста. В результате у пользователя появляется возможность самому выбирать порядок просмотра тех или иных страниц, двигаясь по перемежающимся между собой нитям — паутинкам ссылок. Если при этом компьютер подключен к глобальной сети Интернет, то в сценарий просмотра могут входить ресурсы всего мира, доступ к которым происходит по протоколу работы с гипертекстом, или HTTP (Hyper Text Transfer Protocol). После сказанного становится понятным представление об этих ресурсах как о Всемирной паутине.
Поскольку нетривиальный характер взаимодействия клиента и сервера по протоколу HTTP с удаленными ресурсами Сети скрыт от конечного пользователя за интерфейсом дружественной программы-просмотра гипертекстовых страниц (броузером, от англ. browse -просматривать), начало работы в Web не представляет больших проблем.
Итак, гипертекст не может корректно отображаться обычным текстовым редактором, хотя последний вполне пригоден для его приготовления. Специально разработанный язык гипертекстовой разметки HTML позволяет превращать нужные элементы документа, включая не только текстовые поля, но и графику, в области «мышечувствительности», или в гипертекстовые ссылки. Существует ряд серьезных причин, по которым необходимо остановиться на этом языке ниже чуть более подробно.
Для удобства ввода информации предусмотрены специальные формы, меню. Программы просмотра позволяют получать доступ не только к WWW-серверам, но и к другим службам Internet. С их помощью можно путешествовать по Gopher-серверам, искать информацию в WAlS-базах, получать файлы с файловых серверов по протоколу FTP. Поддерживается протокол обмена сетевыми новостями Usenet NNTP.
Вся польза WWW состоит в создании гипертекстовых документов, и если вас заинтересовал какой-либо пункт в таком документе, то достаточно «ткнуть» в него курсором для получения нужной информации. Также в одном документе возможно делать ссылки на другие, написанные другими авторами или даже расположенные на другом сервере. Одно из главных преимуществ WWW над другими средствами поиска и передачи информации — «многосредность». В WWW можно увидеть на одной странице одновременно текст и изображение, звук и анимацию.
WWW — это в настоящее время самый популярный и самый интересный сервис Интернет, самое популярное и удобное средство работы с информацией. Самое распространенное имя для компьютера в Интернет сегодня — www, больше половины потока данных Интернет приходится на долю WWW. Количество серверов WWW сегодня нельзя оценить сколько-либо точно, но по некоторым оценкам их более 300 тысяч. Скорость роста WWW даже выше, чем у самой сети Интернет.
WWW работает по принципу клиент-сервер, точнее, клиент-серверы: существует множество серверов, которые по запросу клиента возвращают ему гипермедийный документ — документ, состояли из частей с разнообразным представлением информации, в котором каждый элемент может являться ссылкой на другой документ или его часть. Ссылки эти в документах WWW организованы таким образом, что каждый информационный ресурс в глобальной сети Интернет однозначно адресуется, и документ, который вы читаете в данный момент, способен ссылаться как на другие документы на том же сервере, так и на документы (и вообще на ресурсы Интернет) на других компьютерах Интернет. Причем пользователь не замечает этого и работает со всем информационным пространством Интернет как с единым целым. Ссылки WWW указывают не только на документы, специфичные для самой WWW, но и на прочие сервисы и информационные ресурсы Интернет. Более того, большинство программ-клиентов WWW (browsers, навигаторы) не просто понимают такие ссылки, но и являются программами-клиентами соответствующих сервисов: ftp, gopher, сетевых новостей Usenet, электронной почты и т.д. Таким образом, программные средства WWW являются универсальными для различных сервисов Интернет, а сама информационная система WWW играет интегрирующую роль.
Тип соединения с Internet. Подключение к Internet производится посредством сетевого адаптера или другого сетевого устройства, например модема или платы ISDN (Integrated Services Digital Network, Цифровая сеть с интеграцией сервиса). Скорость передачи информации в Internet выражается в битах в секунду.
Скорость передачи узла Internet определяет, насколько быстро проходят через него данные и сколько запросов такой узел сможет обслужить одновременно. Если число одновременных запросов превышает допустимое, то возможно возникновение задержек и срывов.
Скорости передачи арендуемых линий находятся в пределах от 56 000 bps (Frame Relay) до 45 000 000 bps (соединение ТЗ). Коммутируемая линия ISDN обеспечивает скорость вплоть до 128 000 bps.
Распространенные типы соединений в Internet представлены в табл.
Таблица
| Тип соединения | Максимальная скорость передачи | Приблизительное число пользователей |
| Выделенный PPP/SLIP | Скорость модема | 2-3 |
| 56К (Frame Relay) | 56000 bps | 10-20 |
| ISDN (использует РРР) | 128000bps | 10-50 |
| T1 | 1540000bps | 100-500 |
| Дробная T1 | В зависимости от необходимости | В зависимости от необходимости |
| ТЗ | 5000 и выше |
Мало загруженный сервер может использовать соединение 56К или ISDN. На сервер со средней загрузкой лучше установить линию Т1 или ее часть. Крупные организации, которые предполагают высокую загрузку своего узла Internet, могут нуждаться в дробной или множественной линии ТЗ, чтобы обслуживать тысячи пользователей.
Соединение с Internet при помощи модема обычно используется для индивидуальных клиентов и не рекомендуется для серверов.
Такое соединение не в состоянии обслуживать более трех пользователей одновременно. Модемные соединения часто называют «медленными каналами», так как скорость передачи через них обычно составляет от 9600 до 28800 bps. Это значительно меньше того, в чем нуждается, к примеру, сервер World Wide Web.
Аппаратное обеспечение. Существенное влияние на производительность сервера оказывают объем его оперативной памяти (RAM) и тип его процессора. Число пользователей, которых сервер может обслуживать одновременно, меняется в зависимости от типа открываемых ими сеансов и других факторов. Сервер может обслуживать в большем количестве тех пользователей, чьи сеансы меньше загружают его процессор. К числу таких сеансов относятся сеансы электронной почты.
В табл. 7.7.2 приведены минимальные и рекомендуемые требования, которым должно удовлетворять аппаратное обеспечение для работы Microsoft Windows NT Server версии 4.0 и сервера IIS.
Таблица 7.7.2
| Требование | Минимум | Рекомендуется |
| Процессор | 50MHz | 90 MHz Pentium |
| RAM | 16MB | 32-64 MB |
| Свободное место на винчестере | 50МВ | 200MB |
| Монитор | VGA | SVGA |
| CD-ROM | ЗХ | 6X |
Количество оперативной памяти, необходимое для сервера, зависит от ряда факторов, включающих:
Ø число пользователей, обслуживаемых одновременно;
Ø соотношение между числом пользователей HTTP (требуют много памяти) и пользователей Gopher и FTP (требуют меньше памяти);
Ø объем памяти, используемой под кэш;
Ø размер файла подкачки (swap file);
Ø объем свободного дискового пространства;
Ø объем видеопамяти;
Ø число запущенных сервисов;
Ø тип процессора;
Ø поиск в базах данных SQL.
Выбор ISP. Для подключения к Интернету необходим ISP (Internet Service Provider — Поставщик услуг Интернета). ISP предоставляет клиентам доступ к Интернету по телефонным линиям. Кроме того, ISP предоставляет услуги, такие, как аренда пространства на сервере и создание Web-страниц.
Очень важна территориальная близость ISP: независимо от типа используемого соединения цена растет с увеличением расстояния. Также имеют значение надежность обслуживания, набор предлагаемых сервисов, наличие у ISP лишних каналов, скорость связи, цена, доступность обслуживающего персонала и сервисной службы.
Обращаясь к ISP, необходимо указать сервисы и потребность в полосе пропускания. После заключения контракта ISP сообщит ваш адрес IP, маску подсети, имена серверов DNS, проинструктирует о подключении его к сети и порекомендует любое необходимое дополнительное оборудование.
При выборе ISP основные критерии — местоположение, цена, надежность и набор предоставляемых сервисов.
Регистрация имени домена. Домены в Интернете различаются по уровням иерархии, например в iae.lt iae —домен второго уровня, а lt — верхнего. Создавая домен, необходимо зарегистрировать его в руководящей организации, тогда имя домена будет включено в имя ее домена. Домены верхнего уровня классифицируют организации по типам (используется в США): gov (government — государственные), edu (educational — образовательные), org (organization — организации), net (главные центры поддержки сети), mil (военные группы), int (международные), com (commercial — коммерческие), <country code> (любая страна, географическая единица).
Чтобы присоединиться ко всем, кроме последнего, необходимо иметь аргументы, соответствующие предъявляемым строгим требованиям. Включение в домен com гораздо проще, однако все-таки нужно правильно определить, к какому из доменов верхнего уровня относится организация.
Имя домена должно иметь смысл, легко запоминаться и вводиться с клавиатуры, а также не использоваться другой организацией на Интернете.
Выбранное подходящее имя регистрируется. Обычно для этого из области Registration Web-страницы InterNIC получают текстовый бланк и заполняют его в любом редакторе или текстовом процессоре или заполняют форму WWW, используя программу просмотра Web.
Необходимо сообщить InterNIC о себе некоторые данные, первых, кто будет контактировать с ней по административным, техническим или финансовым вопросам, касающимся домена. Во-вторых, имена и IP-адреса серверов DNS, поддерживающих домен.
Заполненная форма отсылается электронной почтой в InterNIC. Через некоторое время поступают два ответа: первый — подтверждение получения запроса, второй — разрешение на использование имени домена.
Файловая система. Windows NT Server поддерживает две файловые системы для жестких дисков: NTFS (Windows NT File System) и FAT (File Allocation Table). Файловая система определяет формат жесткого диска и способ его взаимодействия с операционной системой.
PAT (таблица размещения файлов) — файловая система, совместимость с которой сохранили все файловые системы ПК. FAT обеспечивает доступ к файлам из MS DOS и OS/2. Однако при использовании FAT вы не сможете пользоваться возможностями Windows NT в сфере безопасности данных. Кроме того, FAT не может работать с файлами, превышающими определенные размеры, и не обладает мощностью NTFS. Например, FAT не позволяет автоматически восстанавливать поврежденные в результате сбоя данные.
NTFS (файловая система Windows NT) — позволяет использовать все возможности, которыми обладает Windows NT. Возможно даже указать для каждого пользователя определенные права доступа к каждому файлу или каталогу. Кроме того, эта файловая система ведет журнал операций, так что в случае внезапного сбоя питания (или другой аварийной ситуации) можно без потерь восстановить данные, находящиеся на диске. В отличие от FAT, NTFS позволяет использовать длинные имена файлов и поддерживает расширенный перечень файловых атрибутов. NTFS автоматически генерирует имена файлов, корректные для MS DOS, что обеспечивает совместимость с DOS-приложениями. Эта система позволяет приложениям, написанным для других операционных систем (например, MS DOS), получать доступ к файлам NTFS при работе под управлением Windows NT.
NTFS разработана специально для максимального использования возможностей современных ПК, в которых может находиться несколько мощных процессоров и несколько жестких дисков большого объема.
Организация информации. Документы, предназначенные для экрана компьютера, могут содержать большое количество различных средств отображения информации, включая текст, числа, иллюстрации или фотографии, мультипликацию и цифровой аудиовизуальный материал, поэтому хорошо спроектированный интерфейс — основа проектирования WWW-документов и систем.
Разработка WWW-страниц требует, по крайней мере, базового представления о принципах проектирования интерфейса пользователя. Вопреки новизне компьютерных средств отображения информации и концептуальным трудностям объединения большого количества форм отображения информации в связное представление, существуют пока еще не слишком широко распространенные стандарты организации электронных документов.
Большинство современных концепций относительно структурирования информации относятся к организации книг, периодических изданий и индексации библиотек и систем каталогов, которые росли вокруг печатной информации. Разработка WWW-документов и гипертекстовых документов также должна подвергнуться подобному развитию и стандартизации, чтобы сделаться столь же легко доступной и в электронной форме.
Самая лучшая стратегия при разработке гипертекстового документа — последовательно применять хотя бы некоторые основные принципы построения документа к каждой создаваемой WWW-странице.
Хотя компьютерные гипертекстовые документы предоставляют множество новых возможностей проектировщикам информационных систем, основные принципы проектирования, создания, редактирования и организации электронных информационных систем почти не отличаются от текущей практики создания печатных средств информации.
Диапазон способов организации узлов Web весьма широк: от узлов, имеющих строгую линейную структуру, до узлов, у которых вообще нет четкой структуры. Обычно страницы располагаются в иерархическом или линейном порядке, а также в виде паутины.
Иерархическая организация. Узлы Web, которые следуют иерархической, или древовидной, организации, имеют единственную точку входа в узел, остальные страницы располагаются на исходящих из нее ответвлениях. Данный подход удобен, если информация легко разбивается на категории и подкатегории. При иерархической организации узла Web (рис.7.7.1) к странице самого нижнего уровня ведет один и только один путь.
Такая строгая структура узла может вызвать проблемы у пользователей. Например, если пользователь прошел на несколько уровней вниз по одному из путей, а потом решил попасть в другую часть дерева, то ему придется возвращаться обратно.
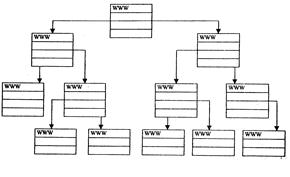
Рис. 7.7.1. Иерархическая организация WWW
Линейная организация. Если необходимо, чтобы пользователи читали содержимое узла как книгу или журнал, или чтобы они прошли по заданному пути от начала и до конца узла, выбирается линейная организация (рис. 7.7.2).
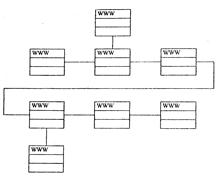
Рис. 7.7.2. Линейная организация WWW.
Какая-то страница может иметь несколько связей с примечаниями и дополнениями, но для продвижения дальше пользователь должен вернуться на нее снова. Продвижение по документу осуществляется кнопкой Next, а возврат к началу узла — кнопкой Prev.
Для большого узла Web линейная организация подходит не очень. Читателям, ищущим конкретную информацию, может не понравиться необходимость пройти через множество страниц, прежде чем они попадут на нужную.
Организация в виде паутины. Организация информации в виде паутины, вероятно, наилучшим образом подходит для большинства случаев. В этой структуре (рис. 7.7.3) страницы связаны друг с другом общим контекстом. К одной странице может идти несколько связей, и у каждого документа есть, по крайней мере, два. Связи иногда образуют круг.
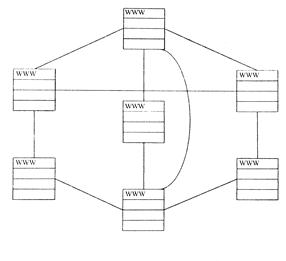
Рис 7.7.3. Организация WWW в виде паутины
Для просмотра Web эта организация узла наиболее удобна. Быстрый проход по узлу и большая свобода перемещения. Недостаток такой структуры в том, что пользователь может что-нибудь пропустить, не пройдя по всем связям.
Программы-клиенты www
Наиболее распространенными программами этого типа являются Mosaic, Netscape Navigator, Internet Explorer (графический интерфейс) и Lynx для алфавитно-цифрового режима доступа. Приведем здесь их краткие характеристики.
Lynx — полноэкранный интерфейс доступа к WWW. Данный интерфейс обеспечивает доступ к WWW с алфавитно-цифровых устройств типа терминала vt100. Интерфейс поддерживает все возможности языка HTML 2.0, за исключением графики.
Internet Explorer (Microsoft) и Netscape Navigator (Netscape Communications) — близкие по своим возможностям многопротокольные графические интерфейсы доступа к WWW и другим ресурсам Сети, интерпретирующие язык гипертекстовой разметки HTML 3.2 (речь идет о версиях продуктов 1997 г.) и поддерживающие средства работы с объектами гипермедиа.
Учитывая высокую популярность броузера Netscape Navigator, a также тот факт, что им в отличие от Internet Explorer не поддерживается меню на русском языке, более подробно обсудим здесь возможности, предоставляемые этой программой.
Netscape Navigator как один из компонентов коммуникационного пакета Netscape Communicator 4.0. (1997). Netscape Navigator реализован для таких платформ, как UNIX, Windows, Macintosh и является мощной многопротокольной программой, позволяющей эффективно организовать доступ ко многим ресурсам Сети. В своей четвертой версии он существует в виде одного из компонентов интегрированного многофункционального пакета Netscape Communicator.
Интерфейс программы для Windows 95/NT можно представить следующим образом. В самом верхнем поле окна отображаются название программы и имя текущего документа, которое указывается в его заголовке. Чуть ниже располагаются элементы главного меню, которые раскрываются по щелчку «мыши» на их именах. Сразу под ними размещена панель с кнопками быстрого доступа к наиболее часто используемым командам. В принципе весь спектр возможностей программы можно извлечь из главного меню, а все остальные поля дублируют пункты главного меню и служат для ускорения работы с пакетом, их можно сделать невидимыми.
На следующем уровне представлена иконка Bookmarks, являющаяся точкой входа в сервис работы с загадками. Сбоку от нее находится, пожалуй, самое главное поле программы — окно Location, предназначенное для ввода адреса ресурса (его URL). Стрелочка-указатель в правой части окна Location предлагает раскрывающееся меню, содержащее по 14 URL наиболее часто просматриваемых пользователем страниц.
Уровнем ниже размещена персональная панель пользователя, которую он может конструировать по своему усмотрению. Далее следует обширная область, в которую загружается документ (Web-страница).
Система прокрутки (в виде полосы справа и снизу от текста) позволяет просматривать содержимое страницы, не поместившееся в один экран.
Для того чтобы различать ссылки в тексте на уже просмотренные страницы от еще не просмотренных, для первых по умолчанию используется синий цвет, для вторых — фиолетовый.
Копирование части текста страницы можно выполнить с помощью меню или штатных средств Windows.
В нижней части окна слева направо располагаются иконка замка (указатель режима безопасности обмена информацией), поле состояния загрузки, поле статуса сообщения и панель иконок составляющих программ-компонентов пакета.
При этом поле состояния загрузки показывает количество загруженной части текущего документа в процентах. Поле сообщения статуса отображает текст, относящийся к загружаемому документу, в том числе и текущую скорость передачи информации. При наложении указателя мыши на гипертекстовую ссылку в документе в этом поле отображается ее URL, а при работе с картой чувствительного изображения — текущие координаты указателя.
Сообщение в поле статуса типа Document Done означает лишь, что загружен очередной объект страницы, например картинка, а не документ в целом. Поскольку на экране может появиться только часть страницы до ее полной загрузки, то и полоса прокрутки появляется только при необходимости и возможности движения вверх-вниз по документу. О полной загрузке страницы сообщает только поле состояния загрузки.
Панель составляющих программ-компонентов позволяет запустить программы пакета Navigator (броузер). Messenger Маilbox (электронная почта), Collabra Discussion Groups (просмотр новостей телеконференций) и Page Composer (редактор HTML-документов).
При помещении указателя «мыши» на соответствующие иконки, как и в других случаях, можно увидеть подсказку. Приведем здесь предметный обзор пунктов главного меню второго уровня.
Основы языка HTML
HTML - язык разметки гипертекста (hyper text markup language). Его основное назначение - управлять размещением информации (текстовой, графической и др.), доступ к которой осуществляется посредством Интернета. Сами языковые конструкции HTML в браузере не видны, однако именно они влияют на отображение веб-страниц. HTML-конструкции обрабатываются браузерами, задавая таким образом правила размещения данных и их иерархическую структуру. HTML в первую очередь выполняет роль "скелета" веб-страницы.
Правила использования языка определяются в спецификациях, которые находятся в свободном доступе по адресу http://www.w3.org/ - на сайте организации, стандартизирующей язык. Спецификацию к HTML 4.0 можно загрузить здесь
Тег (tag) - дескриптор (от англ. describe - описывать), элемент языка HTML, дающий программе, которая обрабатывает HTML-документ, описание правил обработки информации, привязанной к этому элементу.
Веб-страница - совокупность дескрипторов и привязанной к ним информации, расположенная в одном HTML-файле, являющемся структурной единицей информационного ресурса - веб-сайта - либо независимым документом.
Веб-сайт - совокупность HTML-страниц, составляющих единую логическую структуру и объединенных общей целью.
HTML-код - часть веб-страницы, могущая также выступать в виде самостоятельной страницы. Автор/веб-мастер - лицо, написавшее/создавшее страницу/сайт.
«Родоначальником» языка был GML (1969 год). Его задача сводилась к разметке (введению иерархических структур) технической документации. В 1986 г. этому языку был придан статус международного стандарта - SGML (standard generalized markup language - стандартный обобщенный язык разметки). Этот язык предназначен для построения систем логической, структурной разметки любых видов текста. «Структурная разметка» означает, что управляющие коды никак не влияют на визаульное форматирование информации, а лишь указывают на соподчиненность различных частей текста. Стоит отметить, что SGML не является языком программирования, т.к. сам по себе он не способен управлять процессами. Он лишь описывает правила обработки прилагаемой к SGML-конструкции информации собственно программе (браузеру, например).
Наглядная иллюстрация к понятию «структурная разметка» - учебник. Весь текст в нем логически разделен на разделы. Скелет книги - это оглавление, которое можно сравнить с тем самым управляющим кодом.
Стоит заметить, что само по себе оформление средствами HTML вашего документа не придаст последнему «логичности» и «структурности» сколько-нибудь отличной от заданной вами иерархии. Глубину, порядок иерархической структуры вы должны определить заранее, и только затем втискивать документ в рамки HTML. Этот язык никак не влияет на информационное качество, он лишь позволяет другим (пользователям, посетителям) увидеть уже существующую структуру. При это средства языка выступают своего рода флажками, указывающими «путь», который пользователи проходят, посещая вашу страницу.
Ничто не мешает средствами SGML указать на правила отображения текста (размер шрифта, цвет, семейство шрифта), однако идеология SGML требует ограничиться указанием на уровень заголовка к тексту и его положение в иерархической структуре документа. Все остальное может быть вынесено в стилевые спецификации, т.е. надстройки к SGML, размещенные вне SGML -документа и управляющие визуальными аспектами отображения текста. При этом соблюдается независимость развития SGML и его стилевых спецификаций. Такое жесткое условия согласуется с принципом унификации Интернет-технологий, всеобщей доступности веб-документов.
Проследим судьбу Заголовка в различных программах:
· графический браузер
· браузер - синтезатор речи
· поисковый робот
Первый выделит заголовок укрупненным кеглем, сделает жирным. Синтезатор речи выделит заголовок более громкой интонацией. Ну а поисковик при индексации документа будет формировать свое представление о содержимом страницы с помощью заголовка. Именно поэтому следует внимательно относится к распределению заголовков в своем веб-документе.
В 1991 г. на базе SGML был разработан язык HTML. Изначально он полностью разделял идеологию своего "родителя". В версии HTML 1.2 из сорока с небольшим элементов (тегов, дескрипторов) лишь три управляли не структурными, а физическими параметрами отображения документа.
В чем же заключается «гипертекстовость» языка? Гипертекст - это совокупность объектов, в документе, ссылающихся на другие объекты, находящиеся как внутри самого документа, так и за его пределами.
В настоящий момент широко используется версия HTML 4.0, где помимо структурных тегов немало и физических. В данной дисциплине будет рассматриваться последняя версия языка HTML.
Для того, чтобы ваш веб-документ отображался в браузере наиболее точно, необходимо определить версию языка в заголовке до открывающего тега :
В общем случае кодировка (encoding) или кодовая таблица- это однозначное соответствие между подмножеством целых чисел (как правило, идущих подряд) и некоторым набором символов. Ключевое понятие здесь - символ. Символ может быть буквой, знаком препинания, графическим знаком, он также может соответствовать звуку речи. Символ - это мельчайшая неделимая часть смысла. Так латинское «A» и кириллическое «А» суть разные символы, потому что они несут в себе разную информацию (принадлежат разным алфавитам).
Определяющим для любой кодировки является количество охватываемых ею символов. Поскольку в компьютере тексты хранятся в виде последовательности байтов, все кодировки разбиваются на 2 больших типа: однобайтовые (восьмибитные) и двухбайтовые (шестнадцатибитные). Первые способны закодировать не более 256 символов, вторые - до 65 636.
Исторически первой появилась кодировка ASCII (American Standard Code for Information Iterchange), включающая в себя 128 символов. В ней «старший» восьмой бит всегда равен нулю. Она охватывает буквы латинского алфавита, цифры и основные знаки пунктуации. Значимость этой кодировки крайне велика - на ее основе построены все более объемные кодировки, т.е. на своих первых 128-ми знакоместах они размещают те же символы, что и в ASCII.
Первые 32 позиции в кодировке занимают так называемые управляющие символы (control characters), предназначенные для управления устройством, читающим текст (табуляция, перевод строки, возврат каретки). Задействовав в однобайтовой кодировке старший 8-й бит мы получаем дополнительные 128 символов, к которым можно отнести, например, буквы кириллического алфавита. Из-за конкуренции среди производителей программного обеспечения возникло несколько стандартов кодирования кириллицы.
Первым стал т.н. КОИ8 (Код обмена информацией 8-мибитный). Эта кодировка применялась еще в советские времена. Получив распространение она сейчас является обязательной для большинства программ, работающих с текстом (браузеры, электронная почта).
Вторая по хронологии кириллическая кодировка - CP1251 (code page или кодовая страница). Более знакомое ее название - Windows-1251.
Кодировка Latin-1, принятая ISO (Intarnational Standards Organisation - Международной Организацией по Стандартизации), также получила широкое распространение в мире. Она включает в себя так называемую расширенную латиницу, включающую символы французского, испанского, немецкого и др. западноевропейских языков.
Двухбайтовые кодировки необходимы для отображения языков с иероглифическим написанием, количество символов в которых в сотни раз больше, чем в алфавитах. В 1991 году была предпринята попытка создать единую двухбайтовую кодировку, охватывающую символы из всех языков мира, а также множество музыкальных, химических и прочих символов. Результатом этого стал стандарт Unicode (универсальная кодировка). Однако в настоящее время повсеместное использование Unicode остается делом будущего. Пока же достаточно часто используется вариация Unicode - UTF8.
Для определения кодировки в вашем HTML-документе необходимо ввести в его заголовок тег META со следующим содержанием.
Изучение любого языка (компьютерного в том числе) начинается со знакомства с его основными строительными блоками - операторами, выражениями, переменными. С этой точки зрения HTML крайне прост для изучения. Он использует только один только один тип управляющих конструкций - теги. При этом сам HTML-документ состоит из единиц разметки - тегов - и собственно составных частей документа (обеспечение доступа к которым и является основной его целью).
Теги бывают двух видов: парные и непарные. Парные(разделяющие) теги состоят из «открывающего» и «закрывающего» элементов (часто используется как «открывающий/закрывающий тег»). Они заключают в себе текст документа, разделяя его на составные части. Текст, вложенный в такой тег, называется контейнером (контейнером тега, от англ. contain - содержать, вмещать).
Непарные (создающие) представлены одним элементом. Они, в свою очередь, "создают" новые элементы (например, отображают графику).
Также есть несколько тегов, имеющих закрывающую пару, при этом сохраняющие свое действие в "непарном" варианте. Назовем их альтернативными тегами. Визуально тег представляет собой текст в латинице, заключенный в угловые скобки.
<парный тег _ начало> текст и другие теги <непарный тег>Парные теги не должны пересекаться, т.е. если тег А начинается внутри тега Б, то начало и конец тега А должны располагаться после начала тега Б и до его окончания.
Большинство тегов (как парных, так и не парных), имеют атрибуты, уточняющие его действие. Каждый тип тегов имеет набор атрибутов, определенных версией языка.
<тег атр.1="значение" атр.2="значение">Не все атрибуты обладают набором значений - некоторые самим присутствуем в скобках тега устанавливают определенные правила применения. При отсутствии атрибутов браузер использует тег так, как это по умолчанию определено версией языка.
Для обеспечения совместимости HTML-документа со всеми программами-обработчиками рекомендуется соблюдать следующие правила написания HTML-кода:
· все теги, их атрибуты (не считая значений в кавычка “ ”) набирать строчным (малым) шрифтом;
· значение атрибута заключать в кавычки, что в большинстве случаев не обязательно, но может значительно упростить работу при последующей работе с веб-документом;
· альтернативные теги всегда использовать в парном варианте
Специальные символы. HTML как стандартизированный язык пользуется рядом специальных символов (кодовых подстановок - entities), имеющих служебное значение. Эти символы воспринимаются программами-обработчиками не как часть отображаемого документа, а как элемент структурной разметки. К спец.символам относятся:
· < - угловая скобка («рамка тега»)
· & - амперсанд
Для того, чтобы ввести в документ спецсимволы, а также символы, отсутствующие на клавиатуре, используются подстановки. Подстановки бывают мнемонические и числовые. Каждый символ-подстановка, как и тег, заключен в определенные рамки, «скобки»: открывающая «скобка» - амперсанд ( $ ), закрывающая - точка с запятой ( ; ). Мнемонический код:
· & - для &
· © - для ©
· < - для <
· > - для >
Для числовых подстановок используется десятичный (как правило, однако может применяться и шестнадцатеричная система) числовой код, обозначающий положение элемента в текущей кодировке документа. При этом перед цифровым кодом ставится знак # Например:
· & - для &
· © - для ©
· 〈 - для <
· 〉 - для >
Электронная почта во многом похожа на обычную почтовую службу.
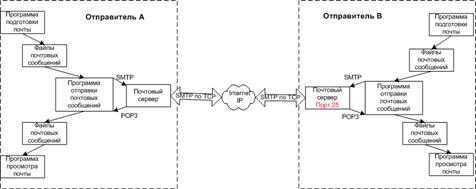
Отправка и получение почты
Основные протоколы:
· SMTP (Simple Mail Transfer Protocol) - простой протокол передачи почты, используется для отправки почты, как клиентом на сервер, так и сервером на другой сервер.
· POP3 (Post Office Protocol) - используется для приема почты клиентом с сервера.
· IMAP 4 (Internet Message Access Protocol) -
· UUCP (Unix-Unix-CoPy) - используется для отправки и приема почты, как клиентом на(с) сервер(а), так и сервером на другой сервер. В данное время почти не используется, поэтому рассматривать не будем.
SMTP - это почтовый протокол хост-хост. SMTP-сервер принимает письма от других систем и сохраняет их в почтовых ящиках пользователей. Сохраненные письма могут быть прочитаны несколькими способами. Пользователи с интерактивным доступом на почтовом сервере могут читать почту с помощью локальных почтовых приложений. Пользователи на других системах могут загрузить свои письма с помощью программ - почтовых клиентов по протоколам РОРЗ и IMAP.
UNIX-хосты сделали самым популярным SMTP. Широко используемыми SMTP-серверами являются Sendmail, Small, MMDF и PP. Самым популярным SMTP-сервером в Unix’e является Sendmail, написанный Брайаном Эллманом. Он поддерживает создание очередей сообщений, переписывание заголовков писем, алиасы, списки рассылки и т.д. Обычно он конфигурируется так, что должен работать как привилегированный процесс. Это означает, что если его защиту можно будет обойти каким-нибудь способом, атакующий сможет нанести вред, далеко превышающий удаление электронных писем.
POP - это самый популярный протокол приема электронной почты. РОР-сервер позволяет РОР-клиенту загрузить письма, которые были получены им от другого почтового сервера. Клиенты могут загрузить все сообщения или только те, которые они еще не читали. Он не поддерживает удаление сообщений перед загрузкой на основе атрибутов сообщения, таких как адрес отправителя или получателя. POP версии 2 поддерживает аутентификацию пользователя с помощью пароля, но пароль передается серверу в открытом (незашифрованном) виде.
POP версии 3 предоставляет дополнительный метод аутентификации, называемый АРОР, который прячет пароль. Некоторые реализации POP могут использовать Kerberos для аутентификации.
IMAP - это самый новый, и поэтому менее популярный протокол чтения электронной почты.
Как сказано в RFC:
IMAP4rev1 поддерживает операции создания, удаления, переименования почтовых ящиков; проверки поступления новых писем; оперативное удаление писем; установку и сброс флагов операций; разбор заголовков в формате RFC-822 и MIME-IMB; поиск среди писем; выборочное чтение писем.
IMAP более удобен для чтения почты в путешествии, чем POP, так как сообщения могут быть оставлены на сервере, что избавляет от необходимости синхронизировать списки прочитанных писем на локальном хосте и на сервере.
Протокол Simple Mail Transfer Protocol(SMTP). Для работы электронной почты в Интернет специально разработан этот протокол, который является протоколом прикладного уровня и использует транспортный протокол TCP. Однако совместно с этим протоколом используется и Unix-Unix-CoPy (UUCP) протокол. UUCP хорошо подходит для использования телефонных линий связи. Разница между SMTP и UUCP заключается в том, что при использовании первого протокола почтового обмена программа, функционирующая на сервере, пытается найти машину получателя почты и установить с ней взаимодействие в режиме on-line для того, чтобы передать почту в ее почтовый ящик. В случае использования SMTP почта достигает почтового ящика получателя за считанные минуты, и время получения сообщения зависит только от того, как часто получатель просматривает свой почтовый ящик. При использовании UUCP почта передается по принципу «stop-go», т.е. почтовое сообщение передается по цепочке почтовых серверов от одной машины к другой, пока не достигнет машины-получателя или не будет отвергнута по причине отсутствия абонента-получателя. С одной стороны, UUCP позволяет доставлять почту по плохим телефонным каналам, так как не требуется поддерживать линию все время доставки от отправителя к получателю, а с другой стороны, время доступа к адресату значительно возрастает. В целом же общие рекомендации таковы: если имеется возможность надежно работать в режиме on-line и это является нормой, то следует настраивать почту для работы по протоколу SMTP, если линии связи плохие или on-line используется чрезвычайно редко лучше использовать UUCP.
Основой любой почтовой службы является система адресов. Без точного адреса невозможно доставить почту адресату. В Интернет принята система адресов, которая базируется на доменном адресе машины. Например, для пользователя tala машины с адресом citmgu.ru почтовый адрес будет выглядеть так:
tala@citmgu.ru
Таким образом, адрес состоит из двух частей: идентификатора пользователя, который записывается перед знаком «коммерческого эй» – «@» и доменного адреса машины, который записывается после знака «@».
Протокол SMTP был разработан для обмена почтовыми сообщениями в сети Интернет, он не зависит от транспортной среды и может использоваться для доставки почты в сетях с протоколами отличными от TCP/IP.
Модель протокола. Взаимодействие в рамках SMTP строится по принципу двусторонней связи, которая устанавливается между отправителем и получателем почтового сообщения. При этом отправитель инициирует соединение и посылает запросы на обслуживание, а получатель на эти запросы отвечает. Фактически, отправитель выступает в роли клиента, а получатель — сервера (см. рис. 7.8.1).
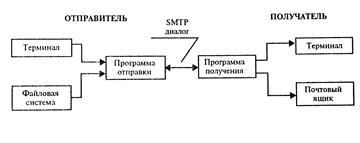
Рис. 7.8.1 Схема взаимодействия по протоколу SMTP
Канал связи устанавливается непосредственно между отправителем и получателем сообщения. При таком взаимодействии почта достигает абонента в течение нескольких секунд после отправки.
РОР3 (Post Office Protocol, версия 3). Протокол обмена почтовой информацией РОР3 предназначен для разбора почты из почтовых ящиков пользователей на их рабочие места при помощи программ – клиентов. Если по протоколу SMTP пользователи отправляют корреспонденцию через Интернет, то по протоколу РОР3 они получают корреспонденцию из своих почтовых ящиков на почтовом сервере в локальные файлы (см. рис. 7.8.2.)
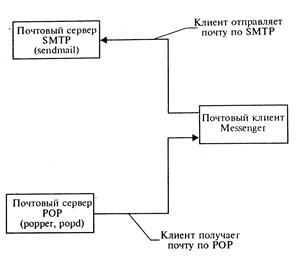
Рис. 7.8.2. Схема работы с почтовым сервером из-под MS-Windows и MS- DOS
Такая схема предполагает, что пользователь имеет почтовый ящик на машине – сервере, которая не выключается круглосуточно. Все почтовые сообщения складываются в этот почтовый ящик. По мере необходимости пользователь из своего почтового клиента обращается к почтовому ящику и забирает из него пришедшую на его имя почту.
При отправке программа – клиент обращается непосредственно к серверу рассылки почты и передает отправляемые сообщения на этот сервер для дальнейшей рассылки.
Формат почтового сообщения Интернет определен в документе RPC – 822 (Standard for ARPA Internet Text Message). Почтовое сообщение состоит из трех частей: конверта, заголовка и тела сообщения. Пользователь видит только заголовок и тело сообщения. Конверт используется только программами доставки. Заголовок всегда находится перед телом сообщения и отделен от него пустой строкой. RFC – 822-регламентирует содержание заголовка сообщения. Заголовок состоит из полей. Поля состоят из имени поля и содержания поля. Имя поля отделено от содержания символом «:». Минимально необходимыми являются поля Date, From, cc или То, например:
Date 26 Aug 76 1429 EDT
From Jones@Registry. org
Cc Robert@Registry. org
или
Date 26 Aug 76 1429 EDT
From Jones@Registry. org
cc Smith@Registry. org
Поля Date определяет дату отправки сообщения, поле From — отправителя, а поля ее и То — получателя(ей). Чаще заголовок содержит дополнительные поля:
Date 26 Aug 76 1429 EDT
From George Jones<Jones@Registry. org>
Sender Secy@SHOST,,MIOM
To Smith@Registry.org
Message –ID: <4231.629.XYzi – What@ Registry.org>
В данном случае поле Sender указывает, что George Jones не является автором сообщения. Он только переслал сообщение, которое получил из Secy&SHOST. Поле Message-ID содержит уникальный идентификаторсообщения и используется программами доставки почты. Следующее сообщение демонстрирует все возможные поля заголовка:
Date 27 Aug 76 0932
From: Ken Davis <Kdavis «This-Host.This.net>
Subject: Re:The Syntax in the RFC
Sender Ksecy@0ther-host
Reply-To Sam. Irvinge@Reg. Organization
To George Jones<Jones@Registry. org
cc Important folks
Tom Softwood <Balsa@Tree.Root.>
«Sam lrving»2@Other-Host:
Standard Distribution:
/main/davis/people/standard@Other-Host:
Comment: Sam is away on bisiness.
In-Reply-To: <some.string@DBM.Group>, George's message
X-Special-action: This is a sample of user-defined field-names .
Message-ID: <4331,629.XYzi-What@Other-Host
Поле Subject определяет тему сообщения, Reply-To — пользователя, которому отвечают, Comment — комментарий, In-Reply-To -— показывает, что сообщение является тем, которое выслано «В ответ на Ваше сообщение, отвечающее на сообщение, отвечающее ...». X-Special-action — поле, определенное пользователем, которое не определено в стандарте.
Следует сказать, что формат сообщения постоянно дополняется и совершенствуется, кроме того, хотелось бы отметить, что возможности почты не ограничиваются только пересылкой корреспонденции. По почте можно получить доступ ко многим ресурсам Интернет, которые имеют почтовых работников (специальные программы автоматического обслуживания), отвечающих на запросы.
Стандарт МIME (Multipurpose Internet Mail Extension),или в нотации Интернет — документ RFC-1341, предназначен для описания тела почтового сообщения Интернет. Предшественником MIME является стандарт почтового сообщения ARPA (RFC822). Стандарт RFC822 был разработан для обмена текстовыми сообщениями. С момента опубликования стандарта возможности аппаратных средств и телекоммуникаций ушли далеко вперед, и стало ясно, что многие типы информации, которые широко используются в сети, невозможно передать по почте без специальных ухищрений. Так, в тело сообщения нельзя включить графику, аудио, видео и другие типы информации. Естественно, что при использовании RFC822 не может быть и речи о передаче размеченного текста для отображения его различными стилями. Ограничения RPC822 становятся еще более очевидными, когда речь заходит об обмене сообщениями в разных почтовых системах.
В некотором смысле стандарт MIME ортогонален стандарту RFC822. Если последний подробно описывает в заголовке почтового сообщения текстовое тело письма и механизм его рассылки, то МIМЕ главным образом сориентирован на описание в заголовке письма структуры тела почтового сообщения и возможности составления письма из информационных единиц различных типов.
В стандарте зарезервировано несколько способов представления разнородной информации. Для этой цели используются специальные поля заголовка почтового сообщения:
Ø поле версии MIME, которое используется для идентификации сообщения, подготовленного в новом стандарте;
Ø поле описания типа информации в теле сообщения, которое позволяет обеспечить правильную интерпретацию данных;
Ø поле типа кодировки информации в теле сообщения, указывающее на тип процедуры декодирования;
Ø два дополнительных поля, зарезервированных для более детального описания тела сообщения.
Стандарт MIME разработан как расширяемая спецификация, в которой подразумевается, что число типов данных будет расти по мере развития форм представления данных. При этом следует учитывать, что анархия типов (безграничное их увеличение) тоже не допустима. Каждый новый тип в обязательном порядке должен быть зарегистрирован в IANA (Internet Assigned Numbers Authority).