В частности, из свойств дисперсии следует, что
D[С+Х]= D[X]
D[X - Y]= D[X] + D[Y].
Среднеквадратичным отклонением случайной величины называется корень квадратный из ее дисперсии:
 .
.
2.2 Генеральная совокупность, выборка, характеристики
Совокупность всех мысленно возможных объектов данного вида, над которыми проводятся наблюдения с целью получения конкретных значений определенной случайной величины, или совокупность результатов всех мыслимых наблюдений, проводимых в неизменных условиях над одной из случайных величин, связанных с данным видом объектов, называется генеральной совокупностью.
Выборочной ковариацией двух переменных x, y называется средняя величина произведения отклонений этих переменных от своих средних, т.е.
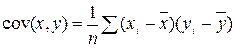 ,
,
где  - выборочные средние переменных x, y. Выборочная ковариация является мерой взаимосвязи между двумя переменными.
- выборочные средние переменных x, y. Выборочная ковариация является мерой взаимосвязи между двумя переменными.
2.3 Корреляция и ковариация
Более точной мерой зависимости между величинами является коэффициент корреляции. Различают выборочный и теоретический коэффициенты корреляции.
Выборочный коэффициент корреляции определяется выражением
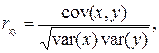 -1£ r £1, (2.1)
-1£ r £1, (2.1)
он является безмерной величиной и показывает степень линейной связи двух переменных. Выборочный коэффициент корреляции является случайной величиной. Теоретический коэффициент корреляции определяется выражением
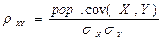 , (2.2)
, (2.2)
где sX, sY – средние квадратичные отклонения случайных величин X,Y. Теоретический коэффициент корреляции показывает тесноту линейной связи двух случайных величин:
r > 0 при положительной связи и r = 1 при строгой положительной линейной связи;
r < 0 при отрицательной связи и r = -1 при строгой отрицательной линейной связи;
r = 0 при отсутствии линейной связи.
В качестве критерия проверки гипотезы H0: r = 0 принимается случайная величина
Список рекомендуемой литературы: /1, 2, 5, 7, 8, 9/
Тема 3 - Метод наименьших квадратов
План лекции:
1. Оценка параметра, ее сущность.
2. Точечные и интервальные оценки параметров.
3. Проверка (тестирование) статистических гипотез
4. Основные цели и задачи прикладного корреляционно-регрессионного анализа
5. Постановка задачи регрессии
6. Парная регрессия и метод наименьших квадратов
7. Коэффициент корреляции, коэффициент детерминации, корреляционное отношение
8. Интерпретация уравнения регрессии
3.1 Оценка параметра, ее сущность.
Оценкой 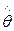 параметра
параметра 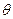 называют всякую функцию результатов наблюдений над случайной величиной Х, с помощью которой судят о значениях параметра .
называют всякую функцию результатов наблюдений над случайной величиной Х, с помощью которой судят о значениях параметра .
Оценка параметра называется несмещенной, если ее математическое ожидание равно оцениваемому параметру, то есть М()=.
Оценка параметра называется состоятельной, если она удовлетворяет закону больших чисел, то есть сходится по вероятности к оцениваемому параметру.
Несмещенная оценка параметра называется эффективной, если она имеет наименьшую дисперсию среди всех возможных несмещенных оценок параметра , вычисленных по выборкам одного и того же объема n.
3.2 Точечные и интервальные оценки параметров.
Интервальной оценкой параметра называется числовой интервал ( ), который с заданной вероятностью γ накрывает неизвестное значение параметра . Такой интервал () называется доверительным, а вероятность γ – доверительной вероятностью или надежностью оценки.
), который с заданной вероятностью γ накрывает неизвестное значение параметра . Такой интервал () называется доверительным, а вероятность γ – доверительной вероятностью или надежностью оценки.
3.3 Проверка (тестирование) статистических гипотез
Статистическая гипотеза — это любое утверждение о виде или свойствах распределений исследуемых случайных величин. Задача проверки данной (нулевой) гипотезы (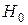 ) состоит в том, чтобы сформулировать правило, которое позволяло бы по результатам наблюдений принять или отклонить . Это правило называют статистическим критерием проверки гипотезы .
) состоит в том, чтобы сформулировать правило, которое позволяло бы по результатам наблюдений принять или отклонить . Это правило называют статистическим критерием проверки гипотезы .
Пусть генеральная функция распределения.  неизвестна, F = {F} — множество допустимых распределений. Сформулируем нулевую гипотезу: “По предположению истинное распределение наблюдаемой случайной величины
неизвестна, F = {F} — множество допустимых распределений. Сформулируем нулевую гипотезу: “По предположению истинное распределение наблюдаемой случайной величины  принадлежит классу F
принадлежит классу F 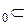 F ”. Допустимые распределения, отличные от гипотетических, называются альтернативами. Таким образом, нужно проверить гипотезу H0 :
F ”. Допустимые распределения, отличные от гипотетических, называются альтернативами. Таким образом, нужно проверить гипотезу H0 : F F против альтернативы
F F против альтернативы
 F
F 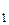 = F / F
= F / F 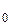 .
.
Основное назначение статистического критерия — улавливать (выявлять) возможные отклонения от , которые задаются конкретными альтернативами. Любому критерию соответствует разбиение выборочного пространства (множества возможных реализаций выборки) на два непересекающихся множества: область принятия 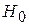 и критическую область. Пусть выбрана критическая область, тогда критерий можно сформулировать так: если наблюдавшееся
и критическую область. Пусть выбрана критическая область, тогда критерий можно сформулировать так: если наблюдавшееся  принадлежит критической области, то отвергают, в противном случае гипотезу принимают.
принадлежит критической области, то отвергают, в противном случае гипотезу принимают.
Как правило, критическая область задается на основе некоторой статистики 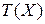 и имеет следующий вид:
и имеет следующий вид:  , или
, или 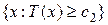 , или
, или  . Пусть T
. Пусть T 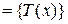 — множество всех возможных значений статистики критерия. Тогда критическая область критерия есть некоторое подмножество T
— множество всех возможных значений статистики критерия. Тогда критическая область критерия есть некоторое подмножество T  T, которое должно включать все маловероятные при значения . Если в процессе проверки :
T, которое должно включать все маловероятные при значения . Если в процессе проверки :
- отклоняется верная гипотеза, то совершается ошибка первого рода;
- принимается ложная гипотеза, то совершается ошибка второго рода.
Введем функцию мощности критерия  T½
T½ F, представляющую собой вероятность попадания случайной выборки в критическую область, когда
F, представляющую собой вероятность попадания случайной выборки в критическую область, когда 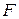 — истинное распределение выборки.
— истинное распределение выборки.
Вероятность ошибки первого рода 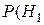 ½
½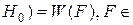 F .
F .
Вероятность ошибки второго рода  ½
½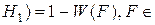 F .
F .
Принцип выбора критической области таков: при заданном объеме выборки устанавливается граница для вероятности ошибки первого рода, при этом выбирается критическая область, для которой вероятность ошибки второго рода минимальна, т.е. выбираем число 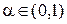 , называемое уровнем значимости критерия, и налагаем условие
, называемое уровнем значимости критерия, и налагаем условие  F , при котором за счет выбора критической области стараемся сделать максимальной мощность
F , при котором за счет выбора критической области стараемся сделать максимальной мощность  F1. Таким образом, решающим моментом для построения критерия является задача отыскания распределения статистики в случае справедливости гипотезы .
F1. Таким образом, решающим моментом для построения критерия является задача отыскания распределения статистики в случае справедливости гипотезы .
Функция мощности полностью характеризует качество критерия: критерий тем лучше, чем больше его мощность при альтернативах.
3.4 Основные цели и задачи прикладного корреляционно-регрессионного анализа
Рассмотрим некоторый экономический объект (процесс, явление, систему) и выделим только две переменные, характеризующие объект. Обозначим переменные буквами Y и X. Будем предполагать, что независимая (объясняющая) переменная X оказывает воздействие на значения переменной Y, которая, таким образом, является зависимой переменной, т.е. имеет место зависимость:
Y=f(X) (3.1)
Зависимость (3.1) можно рассматривать с целью установления самого факта наличия или отсутствия значимой связи между Y и X, можно преследовать цель прогнозирования неизвестных значений Y по известным значениям X, наконец возможно выявление причинно-следственных связей между X и Y.
При изучении взаимосвязи между переменными Y и X следует, прежде всего, установить тип зависимости (природу анализируемых переменных Y и X). Возможны следующие ситуации:
-Y и X являются неслучайными переменными, т.е. значения Y строго зависят только от соответствующих значений X и полностью ими определяются. В этом случае говорят о функциональной зависимости, когда Y является некоторой функцией от переменной X и верна модель (3.1). Пример: y=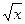
- Y является случайной переменной, а X - неслучайной. В этом случае считают, что между переменными имеет место регрессионная зависимость. То есть верна модель Y=f(X)+u, где и - величина случайной ошибки.
- Y и X зависят от множества неконтролируемых факторов, так что являются случайными по своей сущности. В этом случае к проблемам построения конкретного вида зависимости между указанными переменными присоединяется проблема исследования тесноты связи между этими переменными. Речь в этом случае идет о корреляционно-регрессионной зависимости между Y и X.
Будем предполагать наличие второй из указанных ситуаций. Регрессионный анализ является инструментом решения следующих основных задач:
1) Для любых значений объясняющей переменной X построить наилучшие по некоторому критерию оценки для неизвестной функции ДХ).
2) По заданным значениям объясняющей переменной X построить наилучший по некоторому критерию прогноз для неизвестного значения результирующей переменной Y(X).
3) Пусть известно, что искомая функция зависит от параметра Ө: (Х, Ө). Требуется построить наилучшую в определенном смысле оценку для неизвестного значения этого параметра.
4) Оценить удельный вес влияния переменной X на результирующий показатель Y.
3.5 Постановка задачи регрессии
Поставим задачу регрессии Y на X.
Пусть мы располагаем п парами выборочных наблюдений над двумя переменными X и Y:
X , X
, X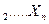 ;
;
Y, Y ,…Y
,…Y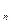
Функция f(X) называется функцией регрессии Y по X, если она описывает изменение условного среднего значения результирующей переменной Y в зависимости от изменения значений объясняющей переменной X: f(Х)=Е(YIX).
Таким образом, уравнение регрессионной связи между Y и X:
У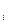 =f(Х)+ε, i=1,...,п. (3.2)
=f(Х)+ε, i=1,...,п. (3.2)
Присутствие в модели (4.2) случайной "остаточной" компоненты ε, также называемой случайным членом, обусловлено следующими причинами:
1) Ошибки спецификации. Среди них выделяют не включение важных
объясняющих переменных, агрегирование (объединение) переменных, неправильную функциональную спецификацию модели.
2) Ошибки измерения. Связаны со сложностью сбора исходных данных и использованием в модели аппроксимирующих переменных для учета факторов, непосредственное измерение которых невозможно.
3) Ошибки, связанные со случайностью человеческих реакций. Обусловлены тем, что поведение и непосредственное участие человека в ходе сбора и подготовки данных может быть достаточно непредсказуемым и вносит, таким образом, свой вклад в случайный член.
Необходимо на основе выборочных наблюдений с учетом дополнительных требований, налагаемых на εстатистически оценить функцию f(X), проверить оптимальность полученной оценки и использовать уравнение для построения прогноза.
Допущения модели. Относительно εнеобходимо принять ряд гипотез, известных как условия Гаусса-Маркова:
1) Е ε=0, i=1,...,n.
Это требование состоит в том, что математическое ожидание случайного члена в любом наблюдении должно быть равно нулю. Иногда случайный член будет положительным, иногда отрицательным, но он не должен иметь систематического смещения ни в одном из двух возможных направлений. Свойство непосредственно вытекает из смысла функции регрессии. Возьмем в (4.2) матожидание от обеих частей при фиксированном значении X, получим: E(Y\X) =Е(f(Х))+Е(ε), по свойству матожидания => E(Y\X) =f(Х)+Е(ε), а поскольку с учетом определения функции регрессии должно быть f(X)=E(Y IX), то необходимо Е(ε)=0.
2) E(ε ε  )=
)=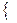


Первая строчка означает требование постоянства дисперсии регрессионных остатков (независимость от того, при каких значениях объясняющей переменной производятся наблюдения i, которое называют гомоскедастичностью остатков. Вторая строчка предполагает отсутствие систематической связи между значениями случайного члена в любых двух наблюдениях, которые должны быть абсолютно независимы друг от друга.
3) X, ..., Хп - неслучайные величины.
Таким образом, задача регрессии имеет вид:
Y=f(Х)+ ε, i=1,..., n.
а) Е ε =0, i=1,...,n. (3.3)
б) E(ε ε )=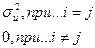 (3.4)
(3.4)
в) Х, ...,Хп- неслучайные величины. (3.5)
При выборе вида функции в (3.2) обычно руководствуются следующими рекомендациями:
- используется априорная информация о содержательной экономической сущности анализируемой зависимости - аналитический способ;
- предварительный анализ зависимости с помощью визуализации - графический способ;
- использование различных статистических приемов обработки исходных данных и экспериментальных расчетов.
3.6 Парная регрессия и метод наименьших квадратов
Будем предполагать в рамках модели (4.2) линейную зависимость между двумя переменными Y и X. Т.е. имеем модель парной регрессии в виде:
Y= 
а. Е ε =0, i=1,...,n.
б. E(ε ε )= 
в. Xi, ...,Xn-неслучайные величины.
Предположим, что имеется выборка значений Y и X. Обозначим арифметические средние (выборочные математические ожидания) для переменных X и Y:
Запишем уравнение оцениваемой линии в виде:
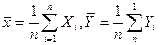
Запишем уравнение оцениваемой линии в виде:

 (3.6)
(3.6)
где  и
и  - оценки неизвестных параметров α и β, a
- оценки неизвестных параметров α и β, a  - ордината этой линии.
- ордината этой линии.
Пусть (X, Y) одна из пар наблюдений. Тогда отклонение этой точки (см. рис. 4.1) от оцениваемой линии будет равно e=Y—  .
.
Принцип метода наименьших квадратов (МНК) заключается в выборе таких оценок и , для которых сумма квадратов отклонений для всех точек становится минимальной.
Y

Рис. 3.1. Иллюстрация принципа МНК
Необходимым условием для этого служит обращение в нуль частных производных функционала:

по каждому из параметров. Имеем:


Упростив последние равенства, получим стандартную форму нормальных уравнений, решение которых дает искомые оценки параметров:
 (3.7)
(3.7)
Из (4.7) получаем:
 (3.8)
(3.8)
Где 
Следующая важная проблема состоит в том, чтобы определить, насколько "хороши" полученные оценки и уравнение регрессии. Этот вопрос рассматривается по следующим стадиям исследования: квалифицирование (выяснение условий применимости результатов), определение качества оценок, проверка выполнения допущений метода наименьших квадратов.
Ошибка прогноза вычисляется по формуле . Ошибка прогноза
. Ошибка прогноза  фактически является оценкой значений ε.
фактически является оценкой значений ε.
В модели (4.2) функция f может быть и нелинейной. Причем выделяют два класса нелинейных регрессий:
- регрессии, нелинейные относительно включенной объясняющей переменной, но линейные по параметрам, например, полиномы разных степеней -  или гипербола -
или гипербола - 
- регрессии нелинейные по оцениваемым параметрам, например степенная функция - , или показательная функция -
, или показательная функция -  В первом случае МНК применяется так же, как и в линейной регрессии, поскольку после замены, например, в квадратичной параболе
В первом случае МНК применяется так же, как и в линейной регрессии, поскольку после замены, например, в квадратичной параболе  переменной X,2 на
переменной X,2 на , получаем линейное уравнение регрессии
, получаем линейное уравнение регрессии 
Во втором случае в зависимости от вида функции возможно применение линеаризующих преобразований, приводящих функцию к виду линейной. Например, для степенной функции , после логарифмирования получаем
, после логарифмирования получаем  ; линейную функцию в логарифмах и применяем МНК. Однако для, например, модели
; линейную функцию в логарифмах и применяем МНК. Однако для, например, модели  , линеаризующее преобразование отсутствует, и приходится применять другие способы оценивания (например, нелинейный МНК).
, линеаризующее преобразование отсутствует, и приходится применять другие способы оценивания (например, нелинейный МНК).
3.7 Коэффициент корреляции, коэффициент детерминации, корреляционное отношение
Для трактовки линейной связи между двумя переменными акцентируют внимание на коэффициенте корреляции.
Пусть имеется выборка наблюдений  которая представлена на диаграмме рассеяния, именуемой также полем корреляции (рис. 3.2).
которая представлена на диаграмме рассеяния, именуемой также полем корреляции (рис. 3.2).

Y I II
III IV
0 X
Рисунок 3.2. Поле корреляции
Разобьем диаграмму на четыре квадранта так, что для любой точки  ) будут определены отклонения
) будут определены отклонения  .
.
Ясно, что для всех точек I квадранта  для всех точек II квадранта
для всех точек II квадранта ; для всех точек Ш квадранта; для всех точек IV квадранта. Следовательно, величина
; для всех точек Ш квадранта; для всех точек IV квадранта. Следовательно, величина  может служить мерой зависимости между переменными X и Y. Если большая часть точек лежит в первом и третьем квадрантах, то
может служить мерой зависимости между переменными X и Y. Если большая часть точек лежит в первом и третьем квадрантах, то  и зависимость положительная, если большая часть точек лежит во втором и четвертом квадрантах, то
и зависимость положительная, если большая часть точек лежит во втором и четвертом квадрантах, то  и зависимость отрицательная. Наконец, если точки рассеиваются по всем четырем квадрантам близка к нулю и между X и Y связи нет.
и зависимость отрицательная. Наконец, если точки рассеиваются по всем четырем квадрантам близка к нулю и между X и Y связи нет.
Указанная мера зависимости изменяется при выборе единиц измерения переменных X и Y. Выразив в единицах среднеквадратических отклонений, получим после усреднения выборочный коэффициент корреляции:
 (3.9)
(3.9)
Из последнего выражения можно после преобразований получить следующую формулу для квадрата коэффициента корреляции:

 (3.10)
(3.10)
Квадрат коэффициента корреляции называется коэффициентом детерминации. Согласно (3.10) значение коэффициента детерминации не может быть больше единицы, причем это максимальное значение будет достигнуто при  , т.е. когда все точки диаграммы рассеяния лежат в точности на прямой. Следовательно, значения коэффициента корреляции лежат в числовом промежутке от -1 до +1.
, т.е. когда все точки диаграммы рассеяния лежат в точности на прямой. Следовательно, значения коэффициента корреляции лежат в числовом промежутке от -1 до +1.
Кроме того, из (4.10) следует, что коэффициент детерминации равен доле дисперсии Y (знаменатель формулы), объясненной линейной зависимостью от X (числитель формулы). Это обстоятельство позволяет использовать R2 как обобщенную меру "качества" статистического подбора модели (4.6). Чем лучше регрессия соответствует наблюдениям, тем меньше  и тем ближе R2 к 1, и наоборот, чем "хуже" подгонка линии регрессии к данным, тем ближе значение R2 к 0.
и тем ближе R2 к 1, и наоборот, чем "хуже" подгонка линии регрессии к данным, тем ближе значение R2 к 0.
Поскольку коэффициент корреляции симметричен относительно X и Y, то есть  , то можно говорить о корреляции как о мере взаимозависимости переменных. Однако из того, что значения этого коэффициента близки по модулю к единице, нельзя сделать ни один из следующих выводов: Y является причиной X; X является причиной Y; X и Y совместно зависят от какой-то третьей переменной. Величина r ничего не говорит о причинно-следственных связях. Эти вопросы должны решаться, исходя из содержательного анализа задачи. Следует избегать и так называемых ложных корреляций, т.е. нельзя пытаться связать явления, между которыми отсутствуют реальные причинно-следственные связи. Например, корреляция между успехами местной футбольной команды и индексом Доу-Джонса. Классическим является пример ложной корреляции, приведенный в начале XX века известным российским статистиком А.А. Чупровым: если в качестве независимой переменной взять число пожарных команд в городе, а в качестве зависимой переменной - сумму убытков от пожаров за год, то между ними есть прямая корреляционная зависимость, т.е. чем больше пожарных команд, тем больше сумма убытков. На самом деле здесь нет причинно-следственной связи, а есть лишь следствия общей причины - величины города.
, то можно говорить о корреляции как о мере взаимозависимости переменных. Однако из того, что значения этого коэффициента близки по модулю к единице, нельзя сделать ни один из следующих выводов: Y является причиной X; X является причиной Y; X и Y совместно зависят от какой-то третьей переменной. Величина r ничего не говорит о причинно-следственных связях. Эти вопросы должны решаться, исходя из содержательного анализа задачи. Следует избегать и так называемых ложных корреляций, т.е. нельзя пытаться связать явления, между которыми отсутствуют реальные причинно-следственные связи. Например, корреляция между успехами местной футбольной команды и индексом Доу-Джонса. Классическим является пример ложной корреляции, приведенный в начале XX века известным российским статистиком А.А. Чупровым: если в качестве независимой переменной взять число пожарных команд в городе, а в качестве зависимой переменной - сумму убытков от пожаров за год, то между ними есть прямая корреляционная зависимость, т.е. чем больше пожарных команд, тем больше сумма убытков. На самом деле здесь нет причинно-следственной связи, а есть лишь следствия общей причины - величины города.
Если между переменными имеет место нелинейная зависимость, то коэффициент корреляции теряет смысл как характеристика степени тесноты связи. В этом случае используется наряду с расчетом коэффициента детерминации расчет корреляционного отношения.
Предположим, что выборочные данные могут быть сгруппированы по оси объясняющей переменной X. Обозначим s - число интервалов группирования,  - число выборочных точек, попавших в у- и интервал группирования,
- число выборочных точек, попавших в у- и интервал группирования,  - среднее значение ординат точек, попавших в j-й интервал группирования,
- среднее значение ординат точек, попавших в j-й интервал группирования,  общее среднее по выборке. С учетом формул для оценок выборочных дисперсий среднего значения Y внутри интервалов группирования
общее среднее по выборке. С учетом формул для оценок выборочных дисперсий среднего значения Y внутри интервалов группирования  и суммарной дисперсии результатов наблюдения
и суммарной дисперсии результатов наблюдения  получим:
получим:
 (3.11)
(3.11)
Величину  в (3.11) называют корреляционным отношением зависимой переменной Y по независимой переменной X. Его вычисление не предполагает каких-либо допущений о виде функции регрессии. Величина по определению неотрицательная и не превышает единицы, причем
в (3.11) называют корреляционным отношением зависимой переменной Y по независимой переменной X. Его вычисление не предполагает каких-либо допущений о виде функции регрессии. Величина по определению неотрицательная и не превышает единицы, причем  свидетельствует о наличии функциональной связи между переменными Y и X. Если указанные переменные не коррелированны друг с другом, то
свидетельствует о наличии функциональной связи между переменными Y и X. Если указанные переменные не коррелированны друг с другом, то  Можно показать, что не может быть меньше величины коэффициента корреляции r (формула (4.9)) и в случае линейной связи эти величины совпадают.
Можно показать, что не может быть меньше величины коэффициента корреляции r (формула (4.9)) и в случае линейной связи эти величины совпадают.
Это позволяет использовать величину разности  - R2 в качестве меры отклонения регрессионной зависимости от линейного вида.
- R2 в качестве меры отклонения регрессионной зависимости от линейного вида.
3.8 Интерпретация уравнения регрессии
Проанализируем, какую информацию дает нам оцененное уравнение регрессии (4.6), т.е. поставим вопрос об интерпретации (содержательном объяснении) коэффициентов уравнения.
Во-первых, можно сказать, что увеличение X на одну единицу (в единицах измерения переменной X) приведет к увеличению/уменьшению (в зависимости от знака коэффициента ) значения Y на единиц (в единицах измерения переменной Y).
Во-вторых, необходимо проверить, в каких единицах измерены переменные X и Y и можно ли заменить слово "единица" фактическим количеством (тенге, тонны и т.п.).
В-третьих, константа дает прогнозируемое значение Y, если положить Х=0. Это может иметь или не иметь экономического смысла в зависимости от конкретной ситуации.
Часто рассчитывают средний коэффициент эластичности  , который показывает, на сколько процентов в среднем по совокупности изменится результат Y от своей средней величины при изменении фактора X на 1% от своего среднего значения.
, который показывает, на сколько процентов в среднем по совокупности изменится результат Y от своей средней величины при изменении фактора X на 1% от своего среднего значения.
При интерпретации уравнения регрессии важно помнить о следующих фактах:
- величины и являются только оценками а и β а следовательно, и
вся интерпретация представляет собой тоже оценку;
- уравнение регрессии отражает общую тенденцию для выборки, а каждое отдельное наблюдение при этом подвержено воздействию случайностей;
- верность интерпретации зависит от правильности спецификации уравнения, то есть включения/исключения соответствующих объясняющих переменных и выбора вида функции регрессии.
Статистическую значимость уравнения регрессии можно оценить с помощью F-критерия Фишера. F-тест состоит в проверке гипотезы  о статистической незначимости уравнения регрессии и показателя тесноты связи. Сравниваются фактическое
о статистической незначимости уравнения регрессии и показателя тесноты связи. Сравниваются фактическое  и критическое (табличное)
и критическое (табличное)  значения F-критерия Фишера. можно рассчитать по формуле:
значения F-критерия Фишера. можно рассчитать по формуле:
 (3.12)
(3.12)
где n – число единиц совокупности;
к – число параметров при переменных x.
- максимально возможное значение F-критерия под влиянием случайных факторов при данных степенях свободы и уровне значимости  .
.
Уровень значимости - вероятность отвергнуть правильную гипотезу при условии, что она верна. Обычно принимается равной 0, 05.
Гипотеза - природа оцениваемых характеристик случайна.
Гипотеза  - природа оцениваемых характеристик не случайна.
- природа оцениваемых характеристик не случайна.
Если  , то - гипотеза о случайной природе оцениваемых характеристик отклоняется и признается их статистическая значимость и надежность с вероятностью1-.
, то - гипотеза о случайной природе оцениваемых характеристик отклоняется и признается их статистическая значимость и надежность с вероятностью1-.
Если  , то - гипотеза о случайной природе оцениваемых характеристик не отклоняется и признается их статистическая незначимость и ненадежность с вероятностью 1-.
, то - гипотеза о случайной природе оцениваемых характеристик не отклоняется и признается их статистическая незначимость и ненадежность с вероятностью 1-.
Если коэффициент детерминации не ниже 0,5 средняя ошибка аппроксимации не превышает 8-10% и отклоняется гипотеза из F-теста, то изучаемая модель хорошо описывает изучаемую закономерность.
Список рекомендуемой литературы:/1, 2, 5, 6, 7/
ТЕМА 4 - Модель множественной линейной регрессии
План лекции:
1. Доверительные интервалы оценок коэффициентов
2. t-статистика Стьюдента
3. F–критерий Фишера
4.1 Доверительные интервалы оценок коэффициентов
Перейдем к вопросу о том, как отличить "хорошие" оценки МНК от "плохих". Конечно, предполагается, что существуют критерии качества рассчитанной линии регрессии.
Перечислим способы, которые помогают решить вопрос о достоинствах рассчитанной линии регрессии:
- построение доверительных интервалов и оценка статистической значимости коэффициентов регрессии по t-критерию Стьюдента;
- дисперсионный анализ и F-критерий Фишера;
- проверка существенности выборочного коэффициента корреляции
(детерминации).
Перейдем к подробному изложению свойств оценок МНК и способов проверки их значимости.
Несложно показать, что оценки и , полученные МНК по (4.8) с учетом ограничений (4.3)-(4.5), являются линейными несмещенными оценками и обладают наименьшими дисперсиями (являются эффективными) в классе линейных оценок (теорема Гаусса-Маркова).
Для вычисления интервальных оценок α, β предполагаем нормальное распределение случайной величины и. Для получения интервальных оценок а, β оценим дисперсию случайного члена  по отклонениям . В качестве оценки дисперсии ошибки возьмем величину:
по отклонениям . В качестве оценки дисперсии ошибки возьмем величину:
 (4.1)
(4.1)
Вычислим величину

и  - стандартную ошибку коэффициента регрессии а.
- стандартную ошибку коэффициента регрессии а.
Статистика
 имеет t-распределение Стьюдента. Так как несмещенная оценка, то для заданного 100(1-
имеет t-распределение Стьюдента. Так как несмещенная оценка, то для заданного 100(1- )% уровня значимости доверительный интервал для а суть:
)% уровня значимости доверительный интервал для а суть:
 (4.2)
(4.2)
где  - табличное значение t распределения для (n-2) степеней свободы и уровня значимости
- табличное значение t распределения для (n-2) степеней свободы и уровня значимости
Вычислим величину 
и  - стандартную ошибку коэффициента регрессии β.
- стандартную ошибку коэффициента регрессии β.
Статистика t = имеет t-распределение Стьюдента. Так как несмещенная оценка, то для заданного 100(1-ε)% уровня значимости доверительный интервал для β суть:
имеет t-распределение Стьюдента. Так как несмещенная оценка, то для заданного 100(1-ε)% уровня значимости доверительный интервал для β суть:
 (4.3)
(4.3)
где - табличное значение t распределения для (n-2) степеней свободы и уровня значимости ε.
4.2 t-статистика Стьюдента
Проверим гипотезу о равенстве нулю коэффициента а, т.е.
Н0: а=0.
С учетом статистики t= для α=0, имея в виду формулу для V(), получим:
для α=0, имея в виду формулу для V(), получим:
 (4.4)
(4.4)
Если вычисленное по (5.4) значение t будет больше tе для заданного критического уровня значимости е, то гипотеза Н0 о равенстве нулю коэффициента а отклоняется, если же t<t, то Н0 принимается.
Аналогично для проверки гипотезы о равенстве нулю коэффициента β т.е. Но: β=0
рассчитаем статистику:
 (4.5)
(4.5)
Если вычисленное по (4.5) значение t будет больше tе для заданного критического уровня значимости е, то гипотеза Н0 о равенстве нулю коэффициента β отклоняется, если же  , то Но принимается.
, то Но принимается.
Разложим общую вариацию значений Y около их выборочного среднего  на составляющие (см. рис. 4.1):
на составляющие (см. рис. 4.1):
 (4.6)
(4.6)
Сумма квадратов отклонений от среднего в выборке равна сумме квадратов отклонений значений  , полученных по уравнению регрессии, от выборочного среднего Y плюс сумма квадратов отклонений Y от линии регрессии . Первую связывают с линейным воздействием изменений переменной X и называют "объясненной". Вторая составляющая является остатком и называется "необъясненной" долей вариации переменной Y.
, полученных по уравнению регрессии, от выборочного среднего Y плюс сумма квадратов отклонений Y от линии регрессии . Первую связывают с линейным воздействием изменений переменной X и называют "объясненной". Вторая составляющая является остатком и называется "необъясненной" долей вариации переменной Y.
Долю дисперсии, объясняемую регрессией, в общей дисперсии результативной переменной Y характеризует коэффициент детерминации, определяемый по формуле:

Проверка гипотезы о значимости выборочного коэффициента корреляции равносильна проверке основной гипотезы об отсутствии линейной связи между Y и X. Вычисляя значение t-статистики  вывод о значимости г делается при /t / >ге, где tе - соответствующее табличное значение г-распределения с (n -2) степенями свободы и уровнем значимости.
вывод о значимости г делается при /t / >ге, где tе - соответствующее табличное значение г-распределения с (n -2) степенями свободы и уровнем значимости.
5.3 F-критерий Фишера
Предположим, что мы хотим проверить гипотезу об отсутствии линейной функциональной связи между X и Y, т.е. Н0: β=0. Иначе говоря, мы хотим оценить значимость уравнения регрессии (4.6) в целом. Для проверки гипотезы сведем необходимые вычисления в таблицу (табл. 5.1).
Соотношение
 (4.7)
(4.7)
удовлетворяет F-распределению Фишера с (1, п-2) степенями свободы. Критические значения этой статистики Fe для уровня значимости е затабулированы. Если F > Fтабл, то гипотеза об отсутствии связи между переменными Y и X отклоняется, в противном случае гипотеза Но принимается и уравнение регрессии не значимо.
Таблица 4.1 Таблица дисперсионного анализа
| Источник вариации | Сумма квадратов отклонений | Число степеней свободы | Среднее квадратов отклонений |
| X |  =2 =2
| 
| |
| Остаток | Q2 = (n-2)
| n-2 |
|
| Общая вариация | 
| n-1 | - |
Список рекомендуемой литературы: /1, 2, 4, 7, 8, 9/
ТЕМА 5 - Классическая модель множественной линейной регрессии
План лекции:
1. Предположения модели
2. Оценивание коэффициентов КЛММР методом наименьших квадратов
3. Парная и частная корреляция в КЛММР
5.1 Предположения модели
Пусть мы располагаем выборочными наблюдениями над k переменными  , и
, и  , j=1,…,k, i=1,2,…,n, где n - количество наблюдений:
, j=1,…,k, i=1,2,…,n, где n - количество наблюдений:
| 2 | i | n | |||
| Y,
| Y2, | Yj, | Y,, | ||
| х,„ | X12, | xh, | xlr, | ||
| xkl, | Xk2, | xki, | Хь, |
Предположим, что существует линейное соотношение между результирующей переменной Y и k объясняющими переменными ХХ3, ..., Xk. Тогда с учетом случайной ошибки  запишем уравнение:
запишем уравнение:
 (5.1)
(5.1)
В (5.1) неизвестны коэффициенты βj,βj=0,2,...,k и параметры распределения . Задача состоит в оценивании этих неизвестных величин. Модель (6.1) называется классической линейной моделью множественной регрессии (КЛММР). Заметим, что часто имеют в виду, что переменная Х0 при  равна единице для всех наблюдений i=1,2,...,n.
равна единице для всех наблюдений i=1,2,...,n.
Относительно переменных модели в уравнении (5.1) примем следующие основные гипотезы:
1. E(Ui)=0; (5.2)
2. (5.3)
(5.3)
3. ХХ3,..., Xk - неслучайные переменные; (5.4)
4. Не должно существовать строгой линейной зависимости между переменными ХХ3,..., Xk. (5.5)
Первая гипотеза (5.2) означает, что переменные имеют нулевую среднюю.
Суть гипотезы (5.3) в том, что все случайные ошибки имеют постоянную дисперсию, то есть выполняется условие гомоскедастичности дисперсии.
Согласно (5.4) в повторяющихся выборочных наблюдениях источником возмущений Y являются случайные колебания , а значит, свойства оценок и критериев обусловлены объясняющими переменными ХХ3,..., Xk.
Последняя гипотеза (5.5) означает, в частности, что не существует линейной зависимости между объясняющими переменными, включая переменную Х0, которая всегда равна 1.
Понятно, что условия (5.2)-(5.4) соответствуют своим аналогам для случая двух переменных.
5.2 Оценивание коэффициентов КЛММР методом наименьших квадратов
Оценки коэффициентов могут быть получены методом наименьших квадратов. Применяя к (6.1) с учетом (5.2)-(5.5) МНК, получаем из необходимых условий минимизации функционала:

т.е. обращения в нуль частных производных по каждому из параметров:

Упростив последние равенства, получим стандартную форму нормальных уравнений, решение которых дает искомые оценки параметров:

(5.6)
Сложность решения системы линейных уравнений (5.6) с (k+l) неизвестными увеличивается быстрее, чем растет k. В зависимости от количества уравнений система может быть решена методом исключения Гаусса или методом Крамера или другим численным методом решения системы линейных алгебраических уравнений.
В результате решения системы (5.6) получим оценки коэффициентов  , j=0,2,..., k.
, j=0,2,..., k.
Возможна и другая запись уравнения (6.1) в так называемом стандартизованном масштабе:
tY=b1tx + b2tXj+... + bktx +u, (5.7)
где tY,tx ,...,tx - стандартизованные переменные:

для которых среднее значение равно нулю:

а среднее квадратическое отклонение равно единице:

bj, j= l,2,...,k- стандартизованные коэффициенты регрессии.
Нетрудно установить зависимость между коэффициентами "чистой" регрессии βj и стандартизованными коэффициентами регрессии b},j=l,2,...,k, a именно:
 (5.8)
(5.8)
Причем 
Соотношение (5.8) позволяет переходить от уравнения вида (5.7) к уравннию вида (5.1).
Стандартизованные коэффициенты регрессии показывают, на сколько "сигм" изменится в среднем результат (У), если соответствующий фактор X изменится на одну "сигму" при неизменном среднем уровне других факторов.
В силу того, что все переменные центрированы и нормированы, коэффициенты bj,j=1,2,...,k, сравнимы между собой (в этом их отличие от  . Сравнивая их друг с другом, можно ранжировать факторы по силе их воздействия на результат, что позволяет произвести отсев факторов - исключить из модели факторы с наименьшими значениями bj.
. Сравнивая их друг с другом, можно ранжировать факторы по силе их воздействия на результат, что позволяет произвести отсев факторов - исключить из модели факторы с наименьшими значениями bj.
Оценки МНК , j=0,2,...,k являются наиболее эффективными (в смысле наименьшей дисперсии) оценками в классе линейных несмещенных оценок (теорема Гаусса-Маркова).
Как было уже указано раньше, достоинством метода множественной регрессии является возможность выделения влияния каждого из факторов Xj в условиях, когда воздействие многих переменных на результат эксперимента не удается контролировать. Степень раздельного влияния каждого из факторов характеризуется оценками ,j=l,2,...,k.
5.3 Парная и частная корреляция в КЛММР
В случаях, когда имеется одна независимая и одна зависимая переменные, естественной мерой зависимости (в рамках линейного подхода) является выборочный (парный) коэффициент корреляции между ними.
Использование множественной регрессии позволяет обобщить это понятие на случай, когда имеется несколько независимых переменных. В этом случае необходима корректировка, так как высокое значение коэффициента корреляции между зависимой и какой-либо независимой переменной может означать высокую степень линейной зависимости, но может означать и то, что третья переменная оказывает значительное влияние на две первых и, что именно она служит основной причиной их высокой корреляции. Поэтому необходимо найти "чистую" корреляцию между двумя переменными, исключив влияние других факторов путем расчета коэффициента частной корреляции.
Коэффициенты частной корреляции для уравнения регрессии с двумя независимыми переменными рассчитываются как:
 (5.9)
(5.9)
 (5.10)
(5.10)
 (5.11)
(5.11)
где  - коэффициент частной корреляции между у и хпри исключенном влиянии
- коэффициент частной корреляции между у и хпри исключенном влиянии ;
;
 - коэффициент частной корреляции между у и х2 при исключенном влиянии
- коэффициент частной корреляции между у и х2 при исключенном влиянии 
 коэффициент частной корреляции между хи x2, исключающий
коэффициент частной корреляции между хи x2, исключающий
влияние у.
Коэффициенты частной корреляции более высоких порядков можно определить через коэффициенты частной корреляции более низких порядков по следующей рекуррентной формуле:
 (5.12)
(5.12)
Коэффициенты частной корреляции широко используются на стадии формирования модели, при отборе факторов.
Так, например, при построении многофакторной модели применяется метод исключения переменных, в ходе которого строится уравнение регрессии с полным набором переменных, затем рассчитывается матрица частных коэффициентов корреляции. Далее проверяется статистическая значимость каждого из коэффициентов согласно t-критерию Стьюдента. Независимая переменная, имеющая наименьшую и несущественную корреляцию с зависимой переменной, исключается. Затем строится новое уравнение регрессии, и процедура продолжается до тех пор, пока не окажется, что все частные коэффициенты корреляции статистически значимы, то есть существенно отличаются от нуля.
Проверка статистической значимости частного коэффициента корреляции суть проверка гипотезы о том, что он равен нулю

Рассчитывается статистика:
 (5.13)
(5.13)
Вывод о значимости частного коэффициента корреляции делается при /t/>t£, где  соответствующее табличное значение t-распределения с (n- (k+1)) степенями свободы.
соответствующее табличное значение t-распределения с (n- (k+1)) степенями свободы.
Список рекомендуемой литературы:: /1, 6, 7, 9, 10, 11/
ТЕМА 6 - Коэффициент детерминации
План лекции:
1. Множественный коэффициент корреляции и множественный коэффициент детерминации
2. Оценка качества модели множественной регрессии
6.1 Множественный коэффициент корреляции и множественный коэффициент детерминации
Множественный коэффициент корреляции используется в качестве меры степени тесноты статистической связи между результирующим показателем (зависимой переменной) у и набором объясняющих (независимых) переменных X1,x2,...,xk или, иначе говоря, оценивает тесноту совместного влияния факторов на результат.
Множественный коэффициент корреляции может быть вычислен по ряду формул, в том числе:
- с использованием матрицы парных коэффициентов корреляции
 R
R (6.1)
(6.1)
где  - определитель матрицы парных коэффициентов корреляции
- определитель матрицы парных коэффициентов корреляции
Y,X1,X2,...,Xk,
 - определитель матрицы межфакторной корреляции x1,x2,...,xk ;
- определитель матрицы межфакторной корреляции x1,x2,...,xk ;
- стандартизованных коэффициентов регрессии  . и парных коэффициентов корреляции
. и парных коэффициентов корреляции 
 (6.2)
(6.2)
Для модели, в которой присутствуют две независимые переменные, формула упрощается
 (6.3)
(6.3)
Квадрат множественного коэффициента корреляции равен коэффициенту детерминации R2. Как и в случае парной регрессии, R2 свидетельствует о качестве регрессионной модели и отражает долю общей вариации результирующего признака у, объясненную изменением функции регрессии f(x)). Кроме того, коэффициент детерминации может быть найден по формуле
 (6.4)
(6.4)
Однако использование R в случае множественной регрессии является не вполне корректным, так как коэффициент детерминации возрастает при добавлении регрессоров в модель. Это происходит потому, что остаточная дисперсия уменьшается при введении дополнительных переменных. И если число факторов приблизится к числу наблюдений, то остаточная дисперсия будет равна нулю, и коэффициент множественной корреляции, а значит и коэффициент детерминации, приблизятся к единице, хотя в действительности связь между факторами и результатом и объясняющая способность уравнения регрессии могут быть значительно ниже.
в случае множественной регрессии является не вполне корректным, так как коэффициент детерминации возрастает при добавлении регрессоров в модель. Это происходит потому, что остаточная дисперсия уменьшается при введении дополнительных переменных. И если число факторов приблизится к числу наблюдений, то остаточная дисперсия будет равна нулю, и коэффициент множественной корреляции, а значит и коэффициент детерминации, приблизятся к единице, хотя в действительности связь между факторами и результатом и объясняющая способность уравнения регрессии могут быть значительно ниже.
Для того чтобы получить адекватную оценку того, насколько хорошо вариация результирующего признака объясняется вариацией нескольких факторных признаков, применяют скорректированный коэффициент детерминации
 (6.5)
(6.5)
Скорректированный коэффициент детерминации всегда меньше R2. Кроме того, в отличие от R2, который всегда положителен,  может принимать и отрицательное значение.
может принимать и отрицательное значение.
6.2 Оценка качества модели множественной регрессии
Проверка качества модели множественной регрессии может быть осуществлена с помощью дисперсионного анализа.
Как уже было отмечено, сумма квадратов отклонений от среднего в выборке равна сумме квадратов отклонений значений , полученных по уравнению регрессии, от выборочного среднего У плюс сумма квадратов отклонений от линии регрессии Y.