SEARCH ENGINES
The same techniques apply to effective research, regardless of whether it is done in the library or on the World Wide Web (although the Web has made the task much easier). If, for example, you were using the library to do research for a term paper, you wouldn't do very well by randomly strolling through the stacks from floor to floor until you found what you wanted. It's equally inefficient to just browse through the Web, going from one link to another until you stumble onto a relevant document.
It's obvious that you would do much better in both cases to conduct a key word search, in which you look for documents on a specific topic. In yesterday's library you would look up the topic in the card catalog; in today's library you would use an online database, and on the Web you would use a search engine, the Web's equivalent of the library's card catalog or database.
A search engine is a program that systematically searches the Web for documents on a specific topic. You enter a query (a key word or phrase) into a search form, and the search engine scans its database to see which documents (if any) are related to the key word you requested. The search engine will list the titles of the documents it finds, together with a link to each document. Some search engines also display an abstract of each document to help you determine its relevancy to your query.
Many search engines are available, each of which uses its own database of Web documents. Each database stores information about each document it contains, typically the document's URL (i.e., its Web address), key words that describe the document, and selected information from the document. Some databases store only the document's title, others contain the first few lines of text, and still others contain every word in the document. Each engine uses its own version of a special program known as a spider to automatically search the Web on a periodic basis, looking for new pages to add to its database.
Some search engines are better than others, but there is no consensus on the "best" engine. In any event, a search engine is only as good as its database and the algorithm it uses to search that database for relevant documents. The larger the database, the greater the number of hits (documents matching your query) that are returned.
A large number of hits, however, does not necessarily guarantee a successful search, because you also need to be concerned with the relevancy of those hits. In other words, the mere fact that a document contains a key word or phrase does not mean the document is useful to you. If, for example, you were searching for information on airline reservations, you might not be interested in the home page of a specific travel agent. And while you might be interested in the home page of a specific airline, you might be better served by a document that lets you access the flight schedule of several airlines.
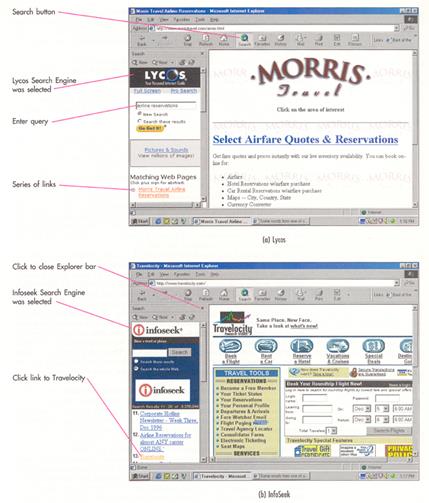
Assume, for example, that you are planning a trip and that you want the cheapest and/or most convenient flight from Fort Lauderdale to San Francisco. Any query that specific, however, would be unlikely to return any hits at all. You might begin, therefore, by searching the Web for a site that lets you make an airline reservation, then once you found such a site, search for the specific flight. The process is illustrated in Figure 4.
The easiest way to initiate a search is to click the Search button on the Standard Buttons toolbar. This opens the Explorer bar and displays the Search pane that is visible in Figures 4a and 4b. The latter contains a text box in which you enter the search criteria, after which you see the results of the search. We selected the Lycos and Infoseek engines in Figures 4a and 4b, respectively, and used the same query, "airline reservations," for both.
The results of the search are displayed as a series of links underneath the list box. The results are different because each engine uses a different database, as well as a different search algorithm. In other words, the same query produces different results with different engines, and thus it is important to use multiple engines for the most complete results. Note, too, that you can click any link in the left pane to display the corresponding document in the right pane.
The document in Figure 4b looked promising, so we decided to explore it further. We were required to enter a personal profile, obtain a username and password, but there was no charge to do so. We were then able to enter the parameters of our desired flight in Figure 4c, after which we were presented with a series of flights that met our requirements in Figure 4d. There was no obligation, whatsoever. We could make the reservation online through the Travelocity site, we could call the airline to make the reservation directly, or we could contact a travel agent to do it for us.
The point of this example is not to make an actual reservation, but to illustrate the mechanics of searching the Web. Think for a minute about what was accomplished. You were looking for information on a flight from Fort Lauderdale to San Francisco. You used a search engine to look through millions of Web documents for information on airline reservations, which in turn led you to a site that let you search for a specific flight. All of this was accomplished in minutes, and the information you retrieved is as complete as that provided by any airline or travel agent.
This example also illustrates the difference between a generalized Web search versus a specific site search. This two-step approach is very common and is used in a variety of instances. The following exercise has you look for the e-mail address of one of the authors. In so doing, you will search the Web for the University of Miami (the author's place of employment), then search the UM site for information about the author himself. Note, too, that the UM site, like many other universities, provides links to a host of campus information. Hence, you can also use the exercise as a guide to learn more about your own college or university.