Тема. Моделювання взаємозв’язків фінансово-економічних показників
Задачі кореляційного аналізу:
- встановлення взаємозв’язку між змінними;
- відбір найбільш впливових факторів;
- встановлення неочевидних причинних зв’язків.
Основні кількісні показники кореляційного аналізу
(Сукупність даних розглядаємо як множину змінних  , кожна з яких має n спостережень:
, кожна з яких має n спостережень:  ,
,  )
)
І. Коваріація (статистична міра взаємодії двох змінних):
 ,
,
де  - середні
- середні
ІІ. Коефіцієнт парної кореляції (нормована статистична міра взаємодії):
 ,
,
де  - середньоквадратичні відхилення X, Y
- середньоквадратичні відхилення X, Y
Шкала Чеддока
(якісна оцінка коефіцієнта кореляції)

| Оцінка зв’язку |
| 0,1-0,3 | слабкий |
| 0,3-0,5 | помітний |
| 0,5-0,7 | помірний |
| 0,7-0,9 | високий |
| 0,9-1,0 | дуже високий |
Порядок вимірювання щільності статистичного взаємозв’язку двох фінансово-економічних показників
1. Побудова кореляційного поля (Мастер диаграмм → точечная).
2. Розрахунок (функція «Коррел» або Анализ данных → Корреляция).
3. Перевірка на значущість.
Перевірка коефіцієнта парної кореляції на значущість (за t-критерієм Стьюдента)
1. Нульова гіпотеза Н0: rxy=0, конкуруюча гіпотеза Н1: rxy ≠ 0.
2. Спостережене значення критерію перевірки нульової гіпотези: 
3.  - за таблицею критичних точок розподілу Стьюдента за рівнем значущості α та степенем свободи n-2. (або СТЬЮДРАСПОБР).
- за таблицею критичних точок розподілу Стьюдента за рівнем значущості α та степенем свободи n-2. (або СТЬЮДРАСПОБР).
4. 1. Якщо  то немає підстав відкинути Н0, приймають, що rxy=0.
то немає підстав відкинути Н0, приймають, що rxy=0.
4.2. Якщо  то відкидають Н0, приймають Н1, це означає, що на рівні значущості α між змінними X, Y є статистичний зв’язок, який визначається отриманим значенням rxy ≠ 0.
то відкидають Н0, приймають Н1, це означає, що на рівні значущості α між змінними X, Y є статистичний зв’язок, який визначається отриманим значенням rxy ≠ 0.
Приклади для аналізу взаємозв’язку між двома фінансово-економічними показниками
1. Вивчити зв’язок між обсягом строкових депозитів фізичних осіб і розміром середньозваженої процентної ставки:
| Дата | Депозити фізичних осіб | Середньозважена ставка |
| січень 07 | 60 810 | 10,6 |
| лютий | 63 774 | 10,9 |
| березень | 66 312 | 10,8 |
| квітень | 67 702 | 10,7 |
| травень | 69 430 | 10,9 |
| червень | 73 839 | 10,8 |
| липень | 77 159 | 10,8 |
| серпень | 81 178 | 10,9 |
| вересень | 84 466 | 11,0 |
| жовтень | 88 143 | 11,2 |
| листопад | 94 662 | 11,3 |
| грудень | 102 379 | 11,6 |
| січень 08 | 103 991 | 11,5 |
| лютий | 107 463 | 11,3 |
| березень | 111 356 | 11,3 |
| квітень | 116 870 | 11,8 |
| травень | 119 435 | 12,6 |
| червень | 123 293 | 12,9 |
| липень | 125 732 | 13,2 |
| серпень | 128 876 | 13,1 |
| вересень | 129 477 | 13,6 |
| жовтень | 116 514 | 14,1 |
| листопад | 111 825 | 13,9 |
| грудень | 110 016 | 14,9 |
| січень 09 | 106 791 | 15,3 |
| лютий | 101 543 | 14,8 |
| березень | 99 231 | 15,5 |
| квітень | 100 284 | 15,4 |
| травень | 101 298 | 15,4 |
| червень | 103 474 | 15,3 |
| липень | 101 852 | 14,8 |
| серпень | 97 785 | 14,7 |
| вересень | 96 640 | 14,7 |
| жовтень | 96 434 | 14,7 |
| листопад | 97 444 | 14,6 |
Кореляційне поле:

r =0,511095
| r Емп: | 3,415862 |
| r Кр: | 2,034515 |
Зв’язок значущий помірний.
2. Вивчити зв’язок між обсягом наданих кредитів і обсягом коштів юридичних і фізичних осіб
| період | кредити надані | кошти юридичних і фізичних осіб |
| 01.01.2005 | ||
| 01.04.2005 | ||
| 01.07.2005 | ||
| 01.10.2005 | ||
| 01.01.2006 | ||
| 01.04.2006 | ||
| 01.07.2006 | ||
| 01.10.2006 | ||
| 01.01.2007 | ||
| 01.04.2007 | ||
| 01.07.2007 | ||
| 01.10.2007 | ||
| 01.01.2008 | ||
| 01.04.2008 | ||
| 01.07.2008 | ||
| 01.10.2008 | ||
| 01.01.2009 | ||
| 01.04.2009 | ||
| 01.07.2009 | ||
| 01.10.2009 |
До 2008 року:

r=0,991996
| r Емп: | 33,33057 |
| r Кр: | 2,100922 |
Зв’язок значущий дуже високий.
3. Вивчити зв’язок між річною зміною заробітної плати і рівнем безробіття (Великобританія, 1950-1966 рр)
| Рік | Зміна заробітної плати, % | Рівень безробіття |
| 1,8 | 1,4 | |
| 8,5 | 1,1 | |
| 8,4 | 1,5 | |
| 4,5 | 1,5 | |
| 4,3 | 1,2 | |
| 6,9 | 1,0 | |
| 8,0 | 1,1 | |
| 5,0 | 1,3 | |
| 3,6 | 1,8 | |
| 2,6 | 1,9 | |
| 2,6 | 1,5 | |
| 4,2 | 1,4 | |
| 3,6 | 1,8 | |
| 3,7 | 2,1 | |
| 4,8 | 1,5 | |
| 4,3 | 1,3 | |
| 4,6 | 1,4 |

r= - 0,56662
| r Емп: | -2,6633 |
| r Кр: | 2,13145 |
Зв’язок значущий помірний (зворотний).
4. Вивчити зв’язок між показниками діяльності банківської системи України:
| період | кредити надані | кошти юридичних і фізичних осіб | кошти банків | статутний капітал |
| 01.01.2005 | ||||
| 01.04.2005 | ||||
| 01.07.2005 | ||||
| 01.10.2005 | ||||
| 01.01.2006 | ||||
| 01.04.2006 | ||||
| 01.07.2006 | ||||
| 01.10.2006 | ||||
| 01.01.2007 | ||||
| 01.04.2007 | ||||
| 01.07.2007 | ||||
| 01.10.2007 | ||||
| 01.01.2008 | ||||
| 01.04.2008 | ||||
| 01.07.2008 | ||||
| 01.10.2008 | ||||
| 01.01.2009 | ||||
| 01.04.2009 | ||||
| 01.07.2009 | ||||
| 01.10.2009 |
return false">ссылка скрыта
Кореляційна матриця (Анализ данных → Корреляция):
| кредити надані | кошти юридичних і фізичних осіб | кошти банків | статутний капітал | |
| кредити надані | ||||
| кошти юридичних і фізичних осіб | 0,9355038 | |||
| кошти банків | 0,9939058 | 0,92216919 | ||
| статутний капітал | 0,9733798 | 0,85259318 | 0,979724 |
5. Вивчити зв’язок між показниками ефективності роботи підприємств
| № підприємства | Продуктивність праці (млн грн) X | Фондовіддача (грн) Y | Матеріалоємність (%) Z |
| 6,0 | 2,0 | ||
| 4,9 | 0,8 | ||
| 7,0 | 2,7 | ||
| 6,7 | 3,0 | ||
| 5,8 | 1,0 | ||
| 6,1 | 2,1 | ||
| 5,0 | 0,9 | ||
| 6,9 | 2,6 | ||
| 6,8 | 3,0 | ||
| 5,9 | 1,1 | ||
| 5,0 | 0,8 | ||
| 5,6 | 2,2 | ||
| 6,0 | 2,4 | ||
| 5,7 | 2,2 | ||
| 5,1 | 1,3 | ||
| 5,2 | 1,5 | ||
| 7,3 | 2,7 | ||
| 6,1 | 2,4 | ||
| 6,2 | 2,2 | ||
| 5,9 | 2,0 | ||
| 6,0 | 2,0 | ||
| 4,8 | 0,9 | ||
| 7,3 | 3,2 | ||
| 7,2 | 3,3 | ||
| 7,0 | 3,0 |
Кореляційна матриця:
| Продуктивність праці (млн грн) X | Фондовіддача (грн) Y | Матеріалоємність (%) Z | |
| Продуктивність праці (млн грн) X | |||
| Фондовіддача (грн) Y | 0,901636 | ||
| Матеріалоємність (%) Z | -0,65648 | -0,70587 |
Розглянемо сукупність змінних (Y; X1;…;Xm):
| Змінні Номер спостереження | Y | X1 | ............. | Xn |
| y1 | x11 | ... | xm1 | |
| ... | ... | ... | ... | ... |
| n | yn | x1n | ... | xmn |
Кореляційна матриця:

ІІІ. Коефіцієнт множинної кореляції R - показник для вимірювання щільності зв’язку між змінною Y та сукупністю факторів X1, ... ,Xm:

де  - визначник матриці К,
- визначник матриці К,
К11 – алгебраїчне доповнення елемента к11 =1.
IV. Коефіцієнт множинної детермінації R2 (показує, яку долю варіації Y пояснює варіація змінних X1, ... ,Xm)
R та R2 ϵ [0;1]
Перевірка коефіцієнта множинної детермінації R2 на значущість (за F-критерієм Фішера)
1. Нульова гіпотеза Н0: R2=0, конкуруюча гіпотеза Н1: R2 ≠ 0.
2. Спостережене значення критерію перевірки нульової гіпотези: 
n – кількість спостережень,
m – кількість незалежних факторів X1, ... ,Xm.
3. 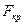 - за таблицею критичних точок розподілу F Фішера-Снедекора за рівнем значущості α та степенями свободи ν1= m та ν2= n-m-1 (або FРАСПОБР).
- за таблицею критичних точок розподілу F Фішера-Снедекора за рівнем значущості α та степенями свободи ν1= m та ν2= n-m-1 (або FРАСПОБР).
4. 1. Якщо  то немає підстав відкинути Н0, приймають, що R2=0.
то немає підстав відкинути Н0, приймають, що R2=0.
4.2. Якщо  то відкидають Н0, приймають Н1, це означає, що на рівні значущості α коефіцієнт детермінації R2 визначається отриманим значенням R2 ≠ 0.
то відкидають Н0, приймають Н1, це означає, що на рівні значущості α коефіцієнт детермінації R2 визначається отриманим значенням R2 ≠ 0.
Приклади для аналізу взаємозв’язку між фінансово-економічними показниками
1. Визначити щільність зв’язку між залежною змінною Y та сукупністю незалежних факторів:
| період | кредити надані Y | кошти юридичних і фізичних осіб X1 | кошти банків X2 | статутний капітал X3 |
| 01.01.2005 | ||||
| 01.04.2005 | ||||
| 01.07.2005 | ||||
| 01.10.2005 | ||||
| 01.01.2006 | ||||
| 01.04.2006 | ||||
| 01.07.2006 | ||||
| 01.10.2006 | ||||
| 01.01.2007 | ||||
| 01.04.2007 | ||||
| 01.07.2007 | ||||
| 01.10.2007 | ||||
| 01.01.2008 | ||||
| 01.04.2008 | ||||
| 01.07.2008 | ||||
| 01.10.2008 | ||||
| 01.01.2009 | ||||
| 01.04.2009 | ||||
| 01.07.2009 | ||||
| 01.10.2009 |
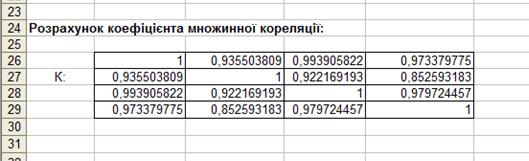


Отже, змінні X1, X2, X3 пояснюють 99% варіації залежної змінної Y.
2. Дослідити щільність зв’язку між залежною змінною Y та сукупністю незалежних факторів:
| Обсяг реалізації товару (млн грн) Y | Місяць X1 | Витрати на рекламу (тис. грн) X2 | Ціна товару (грн) X3 | Ціна товару у конкурента (грн) X4 | Індекс споживчих витрат (%) X5 |
| 4,8 | 14,8 | 17,3 | 98,4 | ||
| 3,8 | 15,2 | 16,8 | 101,2 | ||
| 8,7 | 15,5 | 16,2 | 103,5 | ||
| 8,2 | 15,5 | 104,1 | |||
| 9,7 | |||||
| 14,7 | 18,1 | 20,2 | 107,4 | ||
| 18,7 | 15,8 | 108,5 | |||
| 19,8 | 15,8 | 18,2 | 108,3 | ||
| 10,6 | 16,9 | 16,8 | 109,2 | ||
| 8,6 | 16,3 | 110,1 | |||
| 6,5 | 16,1 | 18,3 | 110,7 | ||
| 12,6 | 15,4 | 16,4 | 110,3 | ||
| 6,5 | 15,7 | 16,2 | 111,8 | ||
| 5,8 | 17,7 | 112,3 | |||
| 5,7 | 15,1 | 16,2 | 112,9 |
Отже, змінні X1, X2, X3, X4, X5 пояснюють 89% варіації залежної змінної Y.
Лінійна модель парної регресії:
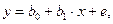
де b0, b1 – коефіцієнти (оцінки невідомих параметрів моделі),
e – випадкова змінна (залишок).
Терміни, позначення, основні формули регресійного аналізу
 - розрахункові значення залежної змінної
- розрахункові значення залежної змінної
| Термін | Сума квадратів відхилень, що пояснює регресію SSR | Сума квадратів помилок SSE | Загальна сума квадратів SST SST= SSR+ SSE |
| Формула | 
| 
| 
|
| Ступінь вільності | n-2 | n-1 |
SST= SSR+ SSE

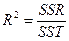
| Термін | Середній квадрат, що пояснює регресію МSR | Середній квадрат помилок МSE | Feмп |
| Формула | SSR/cтуп. вільн.=
= /1
| SSE/cтуп. вільн.=
=  /n-2 /n-2
| МSR/ МSE |
Алгоритм побудови лінійної моделі парної регресії
І. Побудова регресійного рівняння (Анализ данных→Регрессия)
ІІ. Перевірка моделі на адекватність:
ІІ.1. Перевірка моделі на значущість (в цілому та коефіцієнтів).
ІІ.1.1. Перевірка моделі на значущість в цілому (за F-критерієм Фішера).
ІІ.1.2. Перевірка на значущість коефіцієнтів моделі (за t-критерієм Стьюдента).
ІІ.2. Аналіз залишків моделі.
ІІ.2.1. Перевірка випадковості ряду залишків моделі (за методом серій).
ІІ.2.2. Перевірка ряду залишків на відповідність нормальному закону розподілу.
ІІ.2.3. Перевірка ряду залишків на незалежність (на відсутність автокореляції).
ІІ.2.4. Перевірка ряду залишків на гомоскедастичність (рівнозмінюваність залишків).
Розглянемо реалізацію цього алгоритму докладніше на прикладі залежності витрат від доходів:
Приклад 1. Побудувати модель залежності витрат населення на товари та послуги від їхніх доходів (дані за регіонами України, ІІІ квартал 2009 року)
| Регіон (обл.) | ДоходиX | ВитратиY |
| АРМ | ||
| Вінницька | ||
| Волинська | ||
| Дніпр. | ||
| Донецька | ||
| Житомирська | ||
| Закарпатська | ||
| Запорізька | ||
| Ів-Франк | ||
| Київська | ||
| Кіровогр | ||
| Луганська | ||
| Львівська | ||
| Миколаївська | ||
| Одеська | ||
| Полтавська | ||
| Рівненська | ||
| Сумська | ||
| Тернопільська | ||
| Харківська | ||
| Херсонська | ||
| Хмельницька | ||
| Черкаська | ||
| Чернівецька | ||
| Чернігівська | ||
| м.Київ | ||
| м.Севастополь |
(Останній рядок не беремо до уваги через його принципову відмінність – зміна напряму зв’язку, пов’язана з особливістю регіону протягом вказаного періоду).
Для попередньої специфікації виду зв’язку (чи є він лінійним?) представимо залежність між змінними графічно (Мастер диаграмм→точечная):
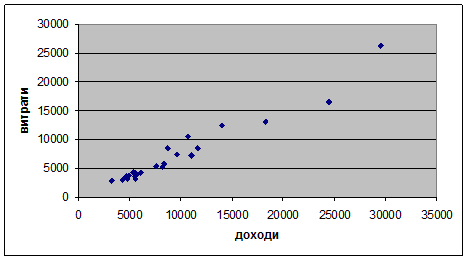
Перша спроба (з вільним членом): вільний член незначущий (виконати самостійно).
Друга спроба (без вільного члена):

Проаналізуємо тепер основні показники отриманої таблиці ВЫВОД ИТОГОВ (як результат кроку І. Побудова регресійного рівняння (Анализ данных→Регрессия).
:
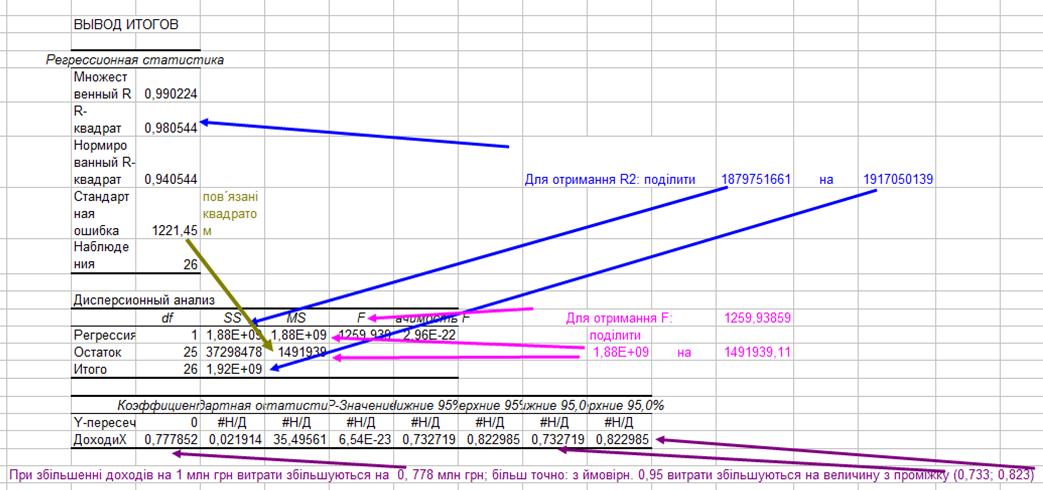


Перейдемо до кроку ІІ:

Перед вивченням результатів кроку ІІ.1.2 розглянемо більш детально основні підходи і формули до перевірки коефіцієнтів моделі на значущість (за t-критерієм Стьюдента).
1. Нульова гіпотеза Н0: bi=0, i=0,1; конкуруюча гіпотеза Н1: bi ≠ 0, i=0,1.
2. Спостережене значення критерію перевірки нульової гіпотези: 
де  - середні квадратичні відхилення коефіцієнтів (в EXCEL: «стандартные ошибки коэффициентов»), які розраховуються за формулами:
- середні квадратичні відхилення коефіцієнтів (в EXCEL: «стандартные ошибки коэффициентов»), які розраховуються за формулами:


де  - середній квадрат помилок рівняння (це «стандартная ошибка» в «выводе итогов»).
- середній квадрат помилок рівняння (це «стандартная ошибка» в «выводе итогов»).
3. - за таблицею критичних точок розподілу Стьюдента за рівнем значущості α та степенем свободи n-2. (або СТЬЮДРАСПОБР).
4. 1. Якщо  то немає підстав відкинути Н0, приймають, що bi =0.
то немає підстав відкинути Н0, приймають, що bi =0.
4.2. Якщо  то відкидають Н0, приймають Н1, це означає, що на рівні значущості α отримані значення коефіцієнтів biє значущими.
то відкидають Н0, приймають Н1, це означає, що на рівні значущості α отримані значення коефіцієнтів biє значущими.

Приклад 2. Побудувати модель залежності обсягу депозитів фізичних осіб від середньозваженої ставки (дані з липня 2006 року до листопада 2009 року)
| Дата | Депозити фізичних осіб Y | Середньозважена ставка X |
| липень06 | 89 073 | 10,30 |
| серпень | 91 590 | 10,20 |
| вересень | 94 266 | 10,50 |
| жовтень | 97 025 | 10,60 |
| листопад | 101 600 | 10,31 |
| грудень | 108 860 | 10,70 |
| січень07 | 111 270 | 10,62 |
| лютий | 115 503 | 10,90 |
| березень | 119 199 | 10,80 |
| квітень | 121 035 | 10,71 |
| травень | 123 312 | 10,91 |
| червень | 129 209 | 10,81 |
| липень | 133 929 | 10,82 |
| серпень | 139 260 | 10,92 |
| вересень | 143 783 | 11,00 |
| жовтень | 148 608 | 11,20 |
| листопад | 157 055 | 11,30 |
| грудень | 167 239 | 11,60 |
| січень08 | 171 326 | 11,50 |
| лютий | 177 223 | 11,32 |
| березень | 182 856 | 11,30 |
| квітень | 189 707 | 11,80 |
| травень | 190 599 | 12,60 |
| червень | 196 893 | 12,90 |
| липень | 201 149 | 13,20 |
| серпень | 204 992 | 13,10 |
| вересень | 207 310 | 13,60 |
| жовтень | 198 392 | 14,10 |
| листопад | 209 024 | 13,90 |
| грудень | 217 860 | 14,90 |
| січень09 | 209 778 | 15,30 |
| лютий | 198 186 | 14,80 |
| березень | 193 437 | 15,50 |
| квітень | 194 561 | 15,40 |
| травень | 195 980 | 15,40 |
| червень | 201 358 | 15,30 |
| липень | 203 576 | 14,80 |
| серпень | 206 368 | 14,70 |
| вересень | 204 963 | 14,70 |
| жовтень | 207 006 | 14,70 |
| листопад | 210 072 | 14,60 |

Отже, маємо регресійне рівняння:
y=-592627+66320,66·x
Отримане рівняння є значущим в цілому і має значущі коефіцієнти.
Розглянемо другий крок перевірки регресійної моделі на адекватність:
ІІ.2. Аналіз залишків моделі.
ІІ.2.1. Перевірка випадковості ряду залишків моделі (за методом серій).
Зауваження. Якщо даний ряд змінних – не часовий, то для перевірки ряду залишків моделі на випадковість впорядкуємо його за зростанням змінної X.
Серія – це послідовність розташованих підряд значень ряду залишків одного знаку (для наочності – будується діаграма залишків).
Сутність методу серій: якщо модель добре відображає досліджувану залежність, то вона часто перетинає лінію графіка вихідних даних, і тоді:
- кількість серій (N) – велика,
- довжина серій (L) – незначна.
Якщо виконується система нерівностей
 ,
,  , ,
, ,
то модель визнається адекватною за критерієм випадковості ряду залишків (на рівні значущості α=0,05).
Якщо хоча б одна з нерівностей не виконується, модель за цим критерієм визнається неадекватною. Одна з найпоширеніших причин невиконання вимоги випадковості ряду залишків – невірна специфікація залежності між змінними (можливо, лінійна залежність погано відображає зв’язок між змінними).
Виконаємо цей крок для приклада 2.

ІІ.2.2. Перевірка ряду залишків на відповідність нормальному закону розподілу
Обчислимо асиметрію As та ексцес Ex для ряду залишків (функції СКОС та ЭКСЦЕСС в EXCEL).
Якщо одночасно виконуються нерівності


то гіпотеза про нормальний розподіл ряду залишків приймається.
В нашому прикладі:

ІІ.2.3. Перевірка ряду залишків на незалежність (на відсутність автокореляції)
Залежність залишків (наявність автокореляції) означає, що не всі фактори відображені в моделі і частково досліджувана закономірність відображається також і в ряді залишків, а це означає неадекватність побудованої моделі процесу, що вивчається.
Один з поширених способів перевірки – за критерієм Дарбіна-Уотсона (див., наприклад, Красникова, Лук’яненко, с.274)
Будемо використовувати ще один загальноприйнятий спосіб перевірки – розрахунок коефіцієнта автокореляції 1-го порядка
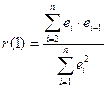 (функція КОРРЕЛ)
(функція КОРРЕЛ)
та перевірка його на значущість (за t-критерієм Стьюдента: якщо  то роблять висновок про наявність автокореляції залишків).
то роблять висновок про наявність автокореляції залишків).
Зауваження. 1. Якщо даний ряд змінних – не часовий, то для перевірки ряду залишків моделі на випадковість впорядкуємо його за зростанням змінної X. 2. Беремо n на одиницю менше (за кількістю членів обох рядів залишків).
Способи усунення автокореляції
1) розгляд сезонної компоненти (у випадку часового ряду);
2) введення до моделі фактора часу;
3) перехід до темпових або відносних показників;
4) включення нових (неврахованих) факторів;
5) побудова авторегресійних моделей (вигляду  ) (Лук’яненко, Красникова, с.278-309) та дистрибутивно-лагових моделей (вигляду
) (Лук’яненко, Красникова, с.278-309) та дистрибутивно-лагових моделей (вигляду  ) (Лук’яненко, Красникова, с.278-309);
) (Лук’яненко, Красникова, с.278-309);
6) використання узагальненого методу найменших квадратів (Лук’яненко, Красникова, с.265-266);
Розглянемо реалізацію цього кроку на прикладі 2:

ІІ.2.4. Перевірка ряду залишків на гомоскедастичність
Гомоскедастичність означає, що дисперсія залишків не залежить від значень факторів (рівнозмінюваність залишків). Один із способів перевірки – побудова і аналіз графіка, що відображає залежність між залишком та незалежною змінною (можна взяти також замість фактора і розрахункове значення залежної змінної – особливо у випадку множинної регресії). Крім того, існує кілька поширених способи перевірки (Лук’яненко, Красникова, с.258-262), скористаємося одним з них - розрахунок коефіцієнта кореляції між модулями залишків і незалежною змінною та перевірка його на значущість. За цим способом значущий і близький до 1 коефіцієнт кореляції підтверджує гіпотезу про гетероскедастичність (тобто відсутність гомоскедастичності).
В разі виявлення гетероскедастичності для побудови регресійної моделі:
1) використовується узагальнений метод найменших квадратів (Лук’яненко, Красникова, с.254-257);
2) вводяться до моделі квадратичні члени незалежної змінної;
3) вводиться до моделі фактор часу;
4) попередньо логарифмують значення змінних.
Повернемося до приклада:


Висновок. Побудована регресійна модель є адекватною і може бути рекомендована до практичного використання.
Продемонструємо на прикладі 2, як здійснюється прогнозування за допомогою рівняння регресії (Лук’яненко, Красникова, с.104-10).
Точкове прогнозне значення змінної Y отримують при підстановці в рівняння регресії (в нашому випадку y=-592627+66320,66·x) значення очікуваної величини X. Візьмемо, наприклад, x=11,8. Тоді yпрогн=-592627+66320,66·11,8= 189956,8.
Розрахуємо довірчий інтервал прогнозу (на рівні значущості α), виходячи з того, що кінцеві значення цього інтервалу знаходяться за формулами:
 ,
,
де - - середній квадрат помилок рівняння (це «стандартная ошибка» в «выводе итогов»);
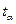 - знаходиться за таблицею критичних точок розподілу Стьюдента за рівнем значущості α та степенем свободи n-2 (або СТЬЮДРАСПОБР).
- знаходиться за таблицею критичних точок розподілу Стьюдента за рівнем значущості α та степенем свободи n-2 (або СТЬЮДРАСПОБР).
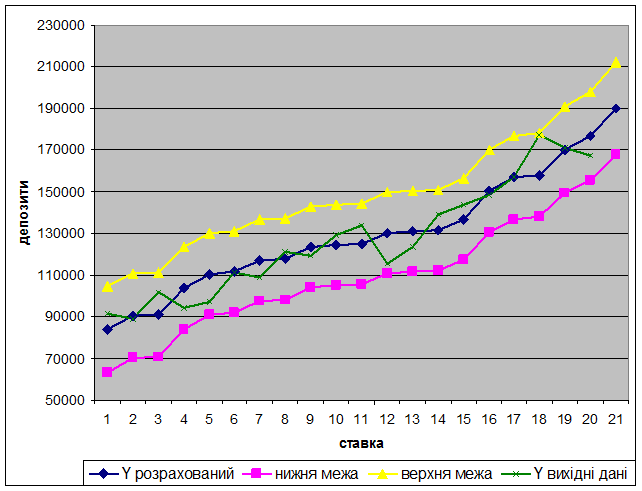
Маємо такі результати розрахунків:
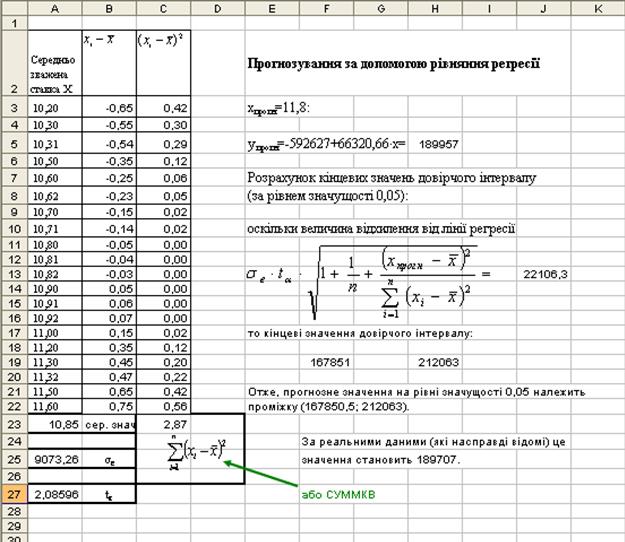
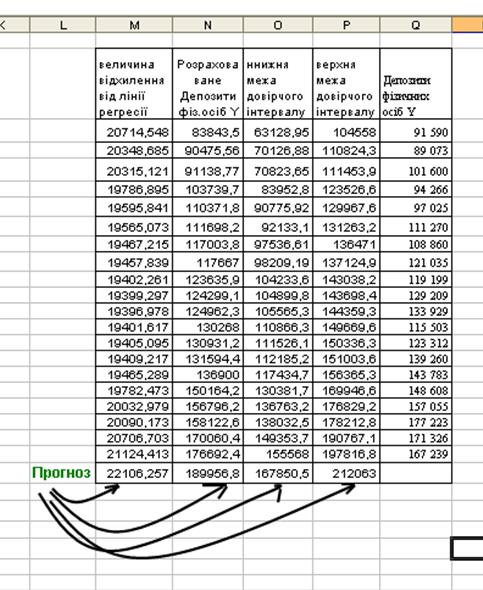
 Прогноз
Прогноз

Лінійна багатофакторна модель:

де a0, a1,…, , am – коефіцієнти (оцінки невідомих параметрів моделі),
e – випадкова змінна (залишок).
Коефіцієнт регресії aj,, j=1,…,m, показує, на яку величину в середньому зміниться результуюча ознака Y, якщо змінну Xj, j=1,…,m, змінити на одиницю виміру.
Більш наочно багатофакторна модель записується у матричному вигляді:
Y = X ∙A + e, де

Оцінки невідомих параметрів моделі знаходяться за формулою: A=(X′∙X)-1∙X′∙Y.
Алгоритм побудови лінійної моделі множинної регресії
І. Підготовчий етап:
І.1. Складання переліку показників і збір статистичної інформації.
І.2. Попередній аналіз даних (перевірка на мультиколінеарність незалежних змінних; відкидання окремих факторів).
ІІ. Побудова регресійного рівняння (Анализ данных→Регрессия)
ІІІ. Перевірка моделі на адекватність:
ІІІ.1. Перевірка моделі на значущість (в цілому та коефіцієнтів).
ІІІ.1.1. Перевірка моделі на значущість в цілому (за F-критерієм Фішера).
ІІІ.1.2. Перевірка на значущість коефіцієнтів моделі (за t-критерієм Стьюдента).
ІІІ.2. Аналіз залишків моделі.
ІІІ.2.1. Перевірка ряду залишків на відповідність нормальному закону розподілу.
ІІІ.2.2. Перевірка ряду залишків на незалежність (на відсутність автокореляції).
ІІІ.2.3. Перевірка ряду залишків на гомоскедастичність (рівнозмінюваність залишків).
Приклад. Побудувати модель залежності змінної Y від сукупності незалежних факторів:
| Обсяг реалізації товару (млн грн) Y | Місяць X1 | Витрати на рекламу (тис. грн) X2 | Ціна товару (грн) X3 | Ціна товару у конкурента (грн) X4 | Індекс споживчих витрат (%) X5 |
| 4,8 | 14,8 | 17,3 | 98,4 | ||
| 3,8 | 15,2 | 16,8 | 101,2 | ||
| 8,7 | 15,5 | 16,2 | 103,5 | ||
| 8,2 | 15,5 | 104,1 | |||
| 9,7 | |||||
| 14,7 | 18,1 | 20,2 | 107,4 | ||
| 18,7 | 15,8 | 108,5 | |||
| 19,8 | 15,8 | 18,2 | 108,3 | ||
| 10,6 | 16,9 | 16,8 | 109,2 | ||
| 8,6 | 16,3 | 110,1 | |||
| 6,5 | 16,1 | 18,3 | 110,7 | ||
| 12,6 | 15,4 | 16,4 | 110,3 | ||
| 6,5 | 15,7 | 16,2 | 111,8 | ||
| 5,8 | 17,7 | 112,3 | |||
| 5,7 | 15,1 | 16,2 | 112,9 |
Переходимо до кроку І.
Перевіряємо незалежні змінні на наявність мультиколінеарності, тобто високої взаємної корельованості поянювальних змінних X1,…,Xm, для чого складається і аналізується кореляційна матриця. Якщо коефіцієнт парної кореляції між двома незалежними змінними більший 0,8, то прийнято вважати, що між цими змінними має місце мультиколінеарність (яку треба усувати або хоча б знижувати). З іншого боку, високий коефіцієнт парної кореляції між Y та окремими незалежними змінними свідчить про щільний зв′язок між ними, отже, про потребу включення до моделі саме таких незалежних зміних.
Способи усунення мультиколінеарності:
1) виключення з моделі одну з двох незалежних змінних, коефіцієнт парної кореляції між якими є високим (Лук′яненко, Краснікова, с.239-241);
2) збільшення спостережень;
3) застосування методу покрокової регресії (Лук′яненко, Краснікова, с.200-201).

Переходимо до побудови регресійного рівняння (крок 2):

Маємо багатофакторне регресійне рівняння:
y= -1471,31+9,568414∙ x2+15,75287∙x5.
Отримане рівняння є значущим в цілому і має значущі коефіцієнти.
Переходимо до аналізу залишків.

Зауважимо, що найчастіше в практичних дослідженнях при побудові моделі множинної регресії інші пункти щодо аналізу залишків вважаються необов′язковими. Отже, можемо на цьому етапі зробити висновок про адекватність побудованої моделі.
Крім того, за допомогою цієї моделі можливе прогнозування (див. формули Лук′яненко, Краснікова, с.196-197)
Особливості використання регресійного аналізу у випадку мультиколінеарності
За допомогою багатофакторного регресійного аналізу вивчимо залежність між обсягами кредитів та активами банків – за банківською системою України, спираючись на дані часового періоду з січня 2005 року до жовтня 2009 року (таблиця 1).
Таблиця 1
| дата | кредити надані Y | кошти юридичних і фізичних осіб X1 | кошти банків X2 | статутний капітал X3 |
| 01.01.05 | 97197,00 | 90934,00 | 20350,00 | 11648,00 |
| 01.04.05 | 94583,00 | 107292,00 | 18046,00 | 12308,00 |
| 01.07.05 | 107618,00 | 116181,00 | 21778,00 | 12721,00 |
| 01.10.05 | 125047,00 | 128904,00 | 24860,00 | 13827,00 |
| 01.01.06 | 156385,00 | 147093,00 | 31998,00 | 16144,00 |
| 01.04.06 | 156554,00 | 151938,00 | 36236,00 | 17005,00 |
| 01.07.06 | 179278,00 | 165059,00 | 46399,00 | 18757,00 |
| 01.10.06 | 209302,00 | 183093,00 | 54659,00 | 21453,00 |
| 01.01.07 | 269688,00 | 202928,00 | 76644,00 | 26266,00 |
| 01.04.07 | 273122,00 | 220515,00 | 86618,00 | 28426,00 |
| 01.07.07 | 316930,00 | 244644,00 | 112691,00 | 31477,00 |
| 01.10.07 | 369845,00 | 282370,00 | 130352,00 | 36808,00 |
| 01.01.08 | 458507,00 | 318388,00 | 168624,00 | 42872,00 |
| 01.04.08 | 484874,00 | 350901,00 | 171587,00 | 49716,00 |
| 01.07.08 | 522026,00 | 379867,00 | 184989,00 | 53239,00 |
| 01.10.08 | 570394,00 | 350901,00 | 171587,00 | 49716,00 |
| 01.01.09 | 792384,00 | 436726,00 | 320838,00 | 82454,00 |
| 01.04.09 | 759664,00 | 336143,00 | 280197,00 | 88245,00 |
| 01.07.09 | 749738,00 | 341196,00 | 294120,00 | 92006,00 |
| 01.10.09 | 747775,00 | 350284,00 | 295284,00 | 104358,00 |
Для того, щоб коефіцієнти регресії можна було порівнювати і, таким чином, розглядати в якості показників впливу факторів X1, X2, X3 на величину Y, будемо шукати коефіцієнти регресії у стандартизованому масштабі, для чого стандартизуємо змінні X1, X2, X3, Y (таблиця 2) за формулами:
 ,
,  (1),
(1),
де  i=1, 2, 3,
i=1, 2, 3,  – середні значення відповідно змінних X1, X2, X3, Y, σi, i=1, 2, 3, σ – середні квадратичні відхилення цих величин.
– середні значення відповідно змінних X1, X2, X3, Y, σi, i=1, 2, 3, σ – середні квадратичні відхилення цих величин.
За нашими даними:  =245267,85,
=245267,85,  =127392,85,
=127392,85,  =40472,30, =372045,55;
=40472,30, =372045,55;
σ1= 106725,378, σ2= 103741,676, σ3= 29596,19, σ= 246678,199.
Таблиця 2
| дата | Y´ | X1´ | X2´ | X3´ |
| 01.01.05 | -1,11 | -1,45 | -1,03 | -0,97 |
| 01.04.05 | -1,12 | -1,29 | -1,05 | -0,95 |
| 01.07.05 | -1,07 | -1,21 | -1,02 | -0,94 |
| 01.10.05 | -1,00 | -1,09 | -0,99 | -0,90 |
| 01.01.06 | -0,87 | -0,92 | -0,92 | -0,82 |
| 01.04.06 | -0,87 | -0,87 | -0,88 | -0,79 |
| 01.07.06 | -0,78 | -0,75 | -0,78 | -0,73 |
| 01.10.06 | -0,66 | -0,58 | -0,70 | -0,64 |
| 01.01.07 | -0,41 | -0,40 | -0,49 | -0,48 |
| 01.04.07 | -0,40 | -0,23 | -0,39 | -0,41 |
| 01.07.07 | -0,22 | -0,01 | -0,14 | -0,30 |
| 01.10.07 | -0,01 | 0,35 | 0,03 | -0,12 |
| 01.01.08 | 0,35 | 0,69 | 0,40 | 0,08 |
| 01.04.08 | 0,46 | 0,99 | 0,43 | 0,31 |
| 01.07.08 | 0,61 | 1,26 | 0,56 | 0,43 |
| 01.10.08 | 0,80 | 0,99 | 0,43 | 0,31 |
| 01.01.09 | 1,70 | 1,79 | 1,86 | 1,42 |
| 01.04.09 | 1,57 | 0,85 | 1,47 | 1,61 |
| 01.07.09 | 1,53 | 0,90 | 1,61 | 1,74 |
| 01.10.09 | 1,52 | 0,98 | 1,62 | 2,16 |
Аналіз матриці коефіцієнтів парної кореляції показує, що залежна змінна Y має тісний зв’язок з усіма змінними X1, X2, X3, які, в свою чергу, тісно пов’язані між собою, що означає наявність мультиколінеарності:
| Y | X1 | X2 | X3 | |
| Y | ||||
| X1 | 0,93550381 | |||
| X2 | 0,99390582 | 0,92216919 | ||
| X3 | 0,97337978 | 0,85259318 | 0,979724 |
Випадок лінійної залежності усіх показників-факторів часто виникає при використанні часових рядів в якості вихідних даних для оцінки параметрів моделі.
Для побудови регресійної моделі за таких умов скористаємося методом покрокової регресії.
1. Серед незалежних змінних обираємо фактор X2, який має найбільш сильний вплив на Y (  ), включаємо його в модель парної регресії. Результати моделювання:
), включаємо його в модель парної регресії. Результати моделювання:
| Регрессионная статистика | |
| Множественный R | 0,993906 |
| R-квадрат | 0,987849 |
| Нормированный R-квадрат | 0,935217 |
| Стандартная ошибка | 0,110233 |
| Наблюдения |
| Дисперсионный анализ | |||||
| df | SS | MS | F | Значимость F | |
| Регрессия | 18,76913 | 18,76913 | 1544,629 | 6,66E-19 | |
| Остаток | 0,230873 | 0,012151 | |||
| Итого |
| Коэффициенты | Стандартная ошибка | t-статистика | P-Значение | |
| Y ´-пересечение | ||||
| X2´ | 0,993906 | 0,025289 | 39,30177 | 1,16E-19 |
Згідно результатів модель має вигляд:
Y´= 0,993906·X2´.
Зауважимо, що має місце значущість як побудованого рівняння регресії (Значимость F=6,66E-19<0,05), так і значущість коефіцієнта регресії (P-Значение=1,16E-19<0,05).
2. Спробуємо вдосконалити отриману модель за рахунок введення додаткової інформації, що міститься в факторах X1 та X3. Для цього розрахуємо парні коефіцієнти кореляції між цими факторами і рядом залишків:
| Залишки | X1´ | X3´ | |
| Залишки | |||
| X1´ | 0,17194991 | ||
| X3´ | -0,0033934 | 0,85259318 |
Згідно алгоритму методу покрокової регресії введемо до моделі змінну X1, оскільки вона має більший (у порівнянні зі змінною X3) коефіцієнт кореляції з рядом залишків.
Результати моделювання: