Определения. Линейная регрессионная модель для случая одной факторной переменной.
Рассмотрим сначала однофакторную регрессионную модель.
В этом случае имеется n пар наблюдений (xi,yi), i=1,2,…,n, над некоторыми случайными величинами Х={xi} и Y={yi}. Эти наблюдения можно представить точками на плоскости с координатами (xi,yi), получая так называемую диаграмму рассеяния. Задача построения регрессионной модели заключается в том, что необходимо подобрать некоторую кривую (график соответствующей функции) таким образом, чтобы она располагалась как можно “ближе” к этим точкам. Такого рода кривую называют эмпирической или аппроксимирующей кривой. Весьма часто тип эмпирической кривой определяется экспериментальными или теоретическими соображениями (исходя из законов экономической теории), в противном случае выбор кривой осуществить довольно трудно. Иногда точки на диаграмме рассеяния располагаются таким образом, что не наблюдается никакого их группирования, и, соответственно, нет никаких оснований предполагать наличие в наблюдениях какой-либо взаимозависимости.
Таким образом, результатом исследования статистической взаимозависимости на основе выборочных данных является построение уравнений регрессии вида y=f(x).
В самом простом случае предполагается, что f задает уравнение прямой f(x)=a0+a1х. Модель в этом случае имеет вид
уi=a0+a1хi+ei (i=1,2,…,n). (2)
Здесь ei являются вертикальными уклонениями точек (xi,yi) от аппроксимирующей прямой. Вопрос о нахождении формулы зависимости можно ставить после положительного ответа на вопрос о существования такой зависимости, но эти два вопроса можно решать и одновременно.
Для ответа на поставленные вопросы существуют специальные методы и, соответственно, показатели, значения которых определенным образом свидетельствуют о наличии или отсутствии линейной связи между переменными. Такими показателями являются коэффициент корреляции величин Х и Y, а также коэффициенты линейной регрессии a0 и a1, их стандартные ошибки и t-статистики, по значениям которых проверяется гипотеза об отсутствии связи величин Х и Y.
Угловой коэффициент a1 прямой линии регрессии Y на X называют коэффициентом регрессии Y на X и обозначают ryx.
Выражение sх2 = 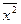 –(
–( 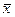 )2 есть выборочная дисперсия Х (или квадрат выборочного среднего квадратического отклонения).
)2 есть выборочная дисперсия Х (или квадрат выборочного среднего квадратического отклонения).
Выборочный коэффициент корреляции определяется равенством

 ryx =(ху – х× у )/(sхsy), (3)
ryx =(ху – х× у )/(sхsy), (3)
где sy есть выборочное среднее квадратическое отклонение Y.
(Верхняя черта, как это принято в теории вероятностей и математической статистике, означает среднее значение выборочной совокупности, в данном случае  ).
).
Коэффициент корреляции измеряет силу (тесноту) линейной связи между Y и X. Он является безразмерной величиной, не зависит от выбора единиц измерения обеих переменных. Для него всегда выполняется 0 £ |ryx| £ 1, и чем ближе его значение к ±1, тем сильнее линейная связь. Коэффициент корреляции будет положительным, если зависимость переменных Х и Y прямо пропорциональная, и отрицательным, – если обратно пропорциональная.
При близости к нулю коэффициента корреляции, например, величин уровней инфляции и безработицы (что имело место фактически в экономике США в 1970-х – 1980-х годах) нужно не говорить сразу о независимости этих показателей, а попытаться построить более сложную (не линейную) модель их связи.
Если формула (1) линейна, то речь идет о линейной регрессии. Формула статистической связи двух переменных называется парной регрессией, зависимость от нескольких переменных – множественной регрессией. Например, Кейнсом была предложена линейная модель зависимости частного потребления С от располагаемого дохода Х: С=С0+ С1Х, где С0 >0 – величина автономного потребления (при уровне дохода Х=0), 1>C1>0 – предельная склонность к потреблению (C1 показывает, на сколько увеличится потребление при увеличении дохода на единицу).
В случае парной линейной регрессии имеется только один объясняющий фактор х и линейная регрессионная модель записывается в следующем виде:
у=a0+a1х+e, (4)
где e – случайная составляющая с независимыми значениями Мe=0, De= s2.