Вычисление линейной регрессии
7.1. Линейный регрессионный анализ заключается в подборе графика для набора наблюдений с помощью метода наименьших квадратов. Регрессионный анализ позволяет установить функциональную зависимость между некоторой случайной величиной Y и некоторыми влияющими на Y величинами X. Такая зависимость получила название уравнения регрессии. Различают простую (y=m*x+b) и множественную (y=m1*x1+m2*x2+... + mk*xk+b) регрессию линейного и нелинейного типа.
Для оценки степени связи между величинами используется коэффициент множественной корреляции R Пирсона (корреляционное отношение), который может принимать значения от 0 до 1. R=0, если между величинами нет никакой связи, и R=1, если между величинами имеется функциональная связь. В большинстве случаев R принимает промежуточные значения от 0 до 1. Величина R2 называется коэффициентом детерминации.
Задачей построения регрессионной зависимости является нахождение вектора коэффициентов M модели множественной линейной регрессии, при котором коэффициент R принимает максимальное значение.
Для оценки значимости R применяется F-критерий Фишера, вычисляемый по формуле:
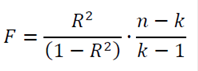
где n – количество экспериментов; k – число коэффициентов модели. Если F превышает некоторое критическое значение для данных n и k и принятой доверительной вероятности, то величина R считается существенной.
7.2. Инструмент Регрессия из Пакета анализа позволяет вычислить следующие данные:
· коэффициенты линейной функции регрессии– методом наименьших квадратов; вид функции регрессии определяется структурой исходных данных;
· коэффициент детерминации и связанные с ним величины (таблица Регрессионная статистика);
· дисперсионную таблицу и критериальную статистику для проверки значимости регрессии (таблица Дисперсионный анализ);
· среднеквадратическое отклонение и другие его статистические характеристики для каждого коэффициента регрессии, позволяющие проверить значимость этого коэффициента и построить для него доверительные интервалы;
· значения функции регрессии и остатки – разности между исходными значениями переменной Y и вычисленными значениями функции регрессии (таблица Вывод остатка);
· вероятности, соответствующие упорядоченным по возрастанию значениям переменной Y (таблица Вывод вероятности).
7.3. Вызовите инструмент создания выборки через Данные> Анализ данных> Регрессия.
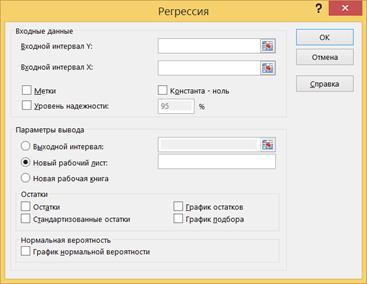
7.4. В поле Входной интервал Y вводится адрес диапазона, содержащего значения зависимой переменной Y. Диапазон должен состоять из одного столбца.
В поле Входной интервал X вводится адрес диапазона, содержащего значения переменной X. Диапазон должен состоять из одного или нескольких столбцов, но не более чем из 16 столбцов. Если указанные в полях Входной интервал Y и Входной интервал X диапазоны включают заголовки столбцов, то необходимо установить флажок опции Метки – эти заголовки будут использованы в выходных таблицах, сгенерированных инструментом Регрессия.
Флажок опции Константа - ноль следует установить, если в уравнении регрессии константа b принудительно полагается равной нулю.
Опция Уровень надежности устанавливается тогда, когда необходимо построить доверительные интервалы для коэффициентов регрессии с доверительным уровнем, отличным от 0.95, который используется по умолчанию. После установки флажка опции Уровень надежности становится доступным поле ввода, в котором вводится новое значение доверительного уровня.
В области Остатки имеются четыре опции: Остатки, Стандартизованные остатки, График остатков и График подбора. Если установлена хотя бы одна из них, то в выходных результатах появится таблица Вывод остатка, в которой будут выведены значения функции регрессии и остатки – разности между исходными значениями переменной Y и вычисленными значениями функции регрессии. В области Нормальная вероятность имеется одна опция – График нормальной вероятности; ее установка порождает в выходных результатах таблицу Вывод вероятности и приводит к построению соответствующего графика.
7.5. Установите параметры в соответствии с рисунком. Проверьте, что в качестве величины Y указана первая переменная (включая ячейку с названием), и в качестве величины X указаны две остальные переменные (включая ячейки с названиями). Нажмите OK.

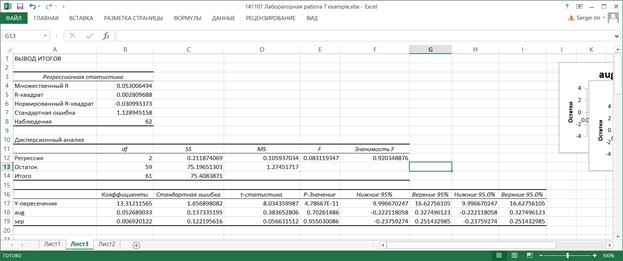
7.6. В таблице Регрессионная статистика приводятся следующие данные.
Множественный R – корень из коэффициента детерминации R2, приведенного в следующей строке. Другое название этого показателя – индекс корреляции, или множественный коэффициент корреляции.
R-квадрат – коэффициент детерминации R2; вычисляется как отношение регрессионной суммы квадратов (ячейка С12) к полной сумме квадратов (ячейка С14).
Нормированный R-квадрат вычисляется по формуле

где n – количество значений переменной Y, k – количество столбцов во входном интервале переменной X.
Стандартная ошибка – корень из остаточной дисперсии (ячейка D13).
Наблюдения – количество значений переменной Y.
7.7. В Дисперсионной таблице в столбце SS приводятся суммы квадратов, в столбце df – число степеней свободы. в столбце MS – дисперсии. В строке Регрессия в столбце f вычислено значение критериальной статистики для проверки значимости регрессии. Это значение вычисляется как отношение регрессионной дисперсии к остаточной (ячейки D12 и D13). В столбце Значимость F вычисляется вероятность полученного значения критериальной статистики. Если эта вероятность меньше, например, 0.05 (заданного уровня значимости), то гипотеза о незначимости регрессии (т.е. гипотеза о том, что все коэффициенты функции регрессии равны нулю) отвергается и считается, что регрессия значима. В данном примере регрессия незначима.
7.8. В следующей таблице, в столбце Коэффициенты, записаны вычисленные значения коэффициентов функции регрессии, при этом в строке Y-пересечение записано значение свободного члена b. В столбце Стандартная ошибка вычислены среднеквадратические отклонения коэффициентов.
В столбце t-статистика записаны отношения значений коэффициентов к их среднеквадратическим отклонениям. Это значения критериальных статистик для проверки гипотез о значимости коэффициентов регрессии.
В столбце P-Значение вычисляются уровни значимости, соответствующие значениям критериальных статистик. Если вычисленный уровень значимости меньше заданного уровня значимости (например, 0.05). то принимается гипотеза о значимом отличии коэффициента от нуля; в противном случае принимается гипотеза о незначимом отличии коэффициента от нуля. В данном примере только коэффициент b значимо отличается от нуля, остальные – незначимо.
В столбцах Нижние 95%и Верхние 95% приводятся границы доверительных интервалов с доверительным уровнем 0.95. Эти границы вычисляются по формулам
Нижние 95% = Коэффициент - Стандартная ошибка * tα;
Верхние 95% = Коэффициент + Стандартная ошибка * tα.
Здесь tα – квантиль порядка α распределения Стьюдента с (n-k-1) степенью свободы. В данном случае α = 0.95. Аналогично вычисляются границы доверительных интервалов в столбцах Нижние 90.0% и Верхние 90.0%.
7.9. Рассмотрим таблицу Вывод остатка из выходных результатов. Эта таблица появляется в выходных результатах только тогда, когда установлена хотя бы одна опция в области Остатки диалогового окна Регрессия.

В столбце Наблюдение приводятся порядковые номера значений переменной Y.
В столбце Предсказанное Y вычисляются значения функции регрессии уi = f(хi) для тех значений переменной X, которым соответствует порядковый номер i в столбце Наблюдение.
В столбце Остатки содержатся разности (остатки) εi=Y-уi , а в столбце Стандартные остатки – нормированные остатки, которые вычисляются как отношения εi / sε. где sε – среднеквадратическое отклонение остатков. Квадрат величины sε вычисляется по формуле

где 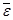 – среднее остатков. Величину
– среднее остатков. Величину 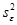 можно вычислить как отношение двух значений из дисперсионной таблицы: суммы квадратов остатков (ячейка С13) и степени свободы из строки Итого (ячейка В14).
можно вычислить как отношение двух значений из дисперсионной таблицы: суммы квадратов остатков (ячейка С13) и степени свободы из строки Итого (ячейка В14).
7.10. По значениям таблицы Вывод остатка строятся два типа графиков: графики остатков и графики подбора (если установлены соответствующие опции в области Остатки диалогового окна Регрессия). Они строятся для каждого компонента переменной X в отдельности.
На графиках остатков отображаются остатки, т.е. разности между исходными значениями Y и вычисленными по функции регрессии для каждого значения компонента переменной X.

На графиках подбора отображаются как исходные значения Y, так и вычисленные значения функции регрессии для каждого значения компонента переменной X.

7.11. Последней таблицей выходных результатов является таблица Вывод вероятности. Она появляется, если в диалоговом окне Регрессия установлена опция График нормальной вероятности.
Значения в столбце Персентиль вычисляются следующим образом. Вычисляется шаг h = (1/n)*100%, первое значение равно h/2, последнее равно 100-h/2. Начиная со второго значения каждое последующее значение равно предыдущему, к которому прибавлен шаг h.
В столбце Y приведены значения переменной Y, упорядоченные по возрастанию. По данным этой таблицы строится так называемый график нормального распределения. Он позволяет визуально оценить степень линейности зависимости между переменными X и Y.
8.Дисперсионный анализ
8.1. Пакет анализа позволяет провести три вида дисперсионного анализа. Выбор конкретного инструмента определяется числом факторов и числом выборок в исследуемой совокупности данных.
Однофакторный дисперсионный анализ используется для проверки гипотезы о сходстве средних значений двух или более выборок, принадлежащих одной и той же генеральной совокупности.
Двухфакторный дисперсионный анализ с повторениями представляет собой более сложный вариант однофакторного анализа, включающий более чем одну выборку для каждой группы данных.
Двухфакторный дисперсионный анализ без повторения представляет собой двухфакторный анализ дисперсии, не включающий более одной выборки на группу. Он используется для проверки гипотезы о том, что средние значения двух или нескольких выборок одинаковы (выборки принадлежат одной и той же генеральной совокупности).
8.2. Однофакторный дисперсионный анализ
8.2.1. Подготовим данные для анализа. Создайте новый лист и скопируйте на него колонки A, B, C, D. Удалите первые две строки. Подготовленные данные можно использовать для проведения Однофакторного дисперсионного анализа.

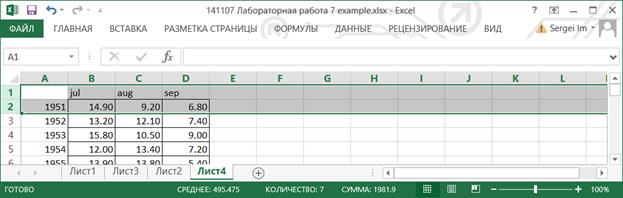
8.2.2. Вызовите инструмент создания выборки через Данные> Анализ данных> Однофакторный дисперсионный анализ.Заполните в соответствии с рисунком. Нажмите OK.
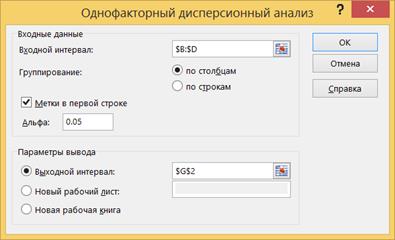
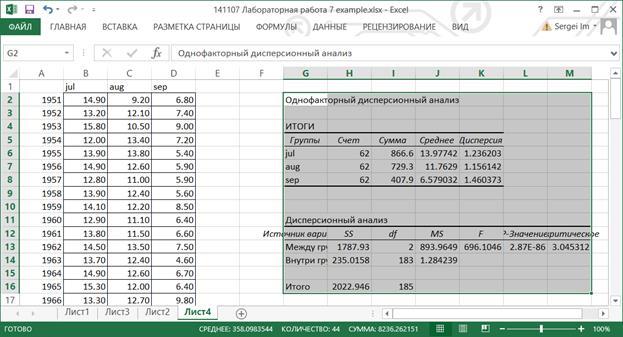
8.2.3. Рассмотрим таблицу Итоги: Счет – число повторений, Сумма – сумма значений показателя по строкам, Дисперсия – частная дисперсия показателя.
8.2.4. Таблица Дисперсионный анализ: первая колонка Источник вариации содержит наименование дисперсий, SS – сумма квадратов отклонений, df – степень свободы, MS – средний квадрат, F-критерий фактического F распределения. P-значение – вероятность того, что дисперсия, воспроизводимая уравнением, равна дисперсии остатков. Оно устанавливает вероятность того, что полученная количественная определенность взаимосвязи между факторами и результатом может считаться случайной. F-критическое – это значение F теоретического, которое впоследствии сравнивается с F фактическим.
8.2.5. Нулевая гипотеза о равенстве математических ожиданий всех выборок принимается, если выполняется неравенство F-критерий < F-критическое. эту гипотезу следует отвергнуть. В данном случае средние значения выборок – значимо различаются.