Архитектура информационно-аналитических систем
Архитектура информационно-аналитических систем (ИАС) в обобщенном виде представлена на рис. 2.1.
Рис. 2.1. Обобщенная архитектура информационно-аналитических систем
Подсистема ввода первичных данных в ИАС реализуется в большинстве случаев средствами OLTP-систем (OLTP- Online Transaction Processing), основной задачей которых является транзакционная обработка данных. Выполнение аналитических функций в этих системах имеет ряд ограничений, обусловленных снижением быстродействия системы при выполнении аналитических запросов и наличием фиксированного периода, в котором возможен анализ данных.
Для снятия этих ограничений данные загружаются в подсистему хранения, в основе которой лежит хранилище данных (ХД).
Хранилище данных – ядро информационно-аналитической системы, поскольку именно от егоорганизации зависит возможность и качество анализа данных. Хранилище данных представляет собой предметно-ориентированный, интегрированный, редко меняющийся, поддерживающий хронологию набор данных, организованный для целей поддержки принятия решений [5]. Предметная ориентация позволяет отразить в хранилище данные, специфичные для различных предметных областей (финансы, продажи и маркетинг, управление складами, производство ит.д.), а интеграция предполагает, что данные, хранящиеся в ХД, приводятся к единому формату. Поддержка хронологии означает, что все данные в ХД соответствуют последовательным интервалам времени.
В архитектуре ИАС применяется несколько различных подходов к организации хранилищ данных. Вариант с физическим хранилищем предполагает загрузку данных из OLTP-систем в ХД, где данные приводятся к единому формату, фильтруются, агрегируется, а запросы адресуются непосредственно к ХД (рис.2.2).
Рис. 2.2. Архитектура информационно-аналитических систем с физическим ХД
Такая архитектура предъявляет повышенные требования к безопасности данных как с точки зрения доступа к ним, так и с точки зрения эффективного хранения больших объемов данных.
Возможен вариант создания виртуального хранилища. В этом случае данные не копируются в единое хранилище, а извлекаются и интегрируются непосредственно в момент формирования аналитического запроса. Данный подход, несмотря на возможность работы с реальными детализированными данными, имеет ряд недостатков. К ним можно отнести увеличение времени обработки запроса, обязательная доступность всех источников информации и возможность обработки только тех исторических данных, которые содержатся в OLTP-системе в данный период времени
Вариант информационно-аналитической системы с созданием независимых витрин данных отличается простотой их организации, поскольку каждая витрина оперирует с данными одной предметной области (задачи). Недостатками автономных витрин данных является необходимость хранить одинаковые данные в разных витринах данных. Кроме того, в ряде случаев возникает ситуация, при которой пользователям необходимы данные из нескольких витрин одновременно, а отсутствие консолидированности данных на уровне независимых витрин не позволяет этого сделать.
В последнее время наибольшее распространение получили информационно-аналитические системы с хранилищем и витринами данных (рис. 2.3).
Рис. 2.3. Архитектура информационно- аналитических систем с ХД и ВД
Такая архитектура позволяет обеспечить получение общей картины деятельности компании за счет наличия централизованного хранилища, упрощает процесс добавления новых витрин, однако обладает избыточностью, так как данные хранятся и в ХД и в ВД.
Все данные в ХД подразделяются на три категории:
- детальные данные;
- агрегированные данные;
- метаданные.
Детальные данные переносятся в ХД непосредственно из OLTP-систем. Их обычно подразделяют на измерения и факты. Измерениями называют наборы данных, необходимые для описания событий (например, название региона, ФИО клиента, наименование товара и т.д.). Факты ─ это данные, отражающие суть события (например, объем продаж в регионе, число обращений клиента на сервисное обслуживание и т.д.).
На основании детальных данных формируются агрегированные данные, представляющие собой суммы фактических данных по измерениям. Ключевым элементом в ХД являются метаданные ‒ данные о данных [5]. Они содержат всю информацию, необходимую для извлечения, преобразования и загрузки данных из различных источников, а также для последующего использования и интерпретации данных, содержащихся в ХД.
Одним из критериев эффективности работы информационно-аналитических систем является скорость выполнения сложных запросов и прозрачность структуры хранения информации. Для обеспечения достижимости этих критериев в настоящее время используется два подхода к построению хранилищ данных. Первый подход основан на применении многомерной модели данных, а второй подход использует реляционную модель. В обоих случаях данные организованы в виде некоторого гиперкуба, который может быть реализован как отдельная многомерная структура, так и в рамках реляционных таблиц. Оси куба являются измерениями, по которым откладывают параметры, относящиеся к анализируемой предметной области, например, названия товаров и названия месяцев года. На пересечении осей измерений располагаются данные, количественно характеризующие анализируемые факты, например, объемы продаж, выраженные в единицах продукции (рис. 2.4).

Рис. 2.4. Представление данных в виде гиперкуба
В процессе поиска и извлечения из гиперкуба нужной информации над его измерениями производится такие операции как срез, вращение, консолидация и детализация [5,6]. При выполнении операции срез формируется подмножество гиперкуба, в котором значение одного или более измерений фиксировано (например, значения параметров для фиксированного измерения «Город»). Операция вращения изменяет порядок представления измерений, обеспечивая представление куба в более удобной для восприятия форме. Консолидация − операция перехода от детального представления данных к агрегированному. Например, показатели для отдельных городов могут быть просуммированы с целью получения показателей для всего региона, а показатели для отдельных дней могут быть «свернуты» до показателей за целый год. Операция детализации − это действие над данными, обратное операции консолидации.
При использовании многомерной модели данные хранятся в виде упорядоченных многомерных массивов, а гиперкуб представляется в виде одной плоской таблицы (рис. 2.5).

Рис. 2.5. Представление многомерных данных
Применение многомерных моделей данных в ХД целесообразно при небольших объемах данных, стабильном наборе информационных измерений, а также в случаях, когда время ответа системы на нерегламентированные запросы является наиболее критичным параметром или предполагается использование сложных встроенных функций для выполнения кроссмерных вычислений над ячейками гиперкуба, в том числе возможность написания пользовательских функций.
При применении реляционной модели данных для построения хранилища данные организуются специальным образом. Чаще всего используется радиальная схема, получившая название «звезда» (рис. 2.6). В этой схеме, представленной в качестве примера, используется два типа таблиц: таблица фактов (Order) и таблицы измерений (Customer, Product). Если в анализе участвуют связанные измерения, то целесообразно использовать схему «снежинка» (рис. 2. 7).
return false">ссылка скрыта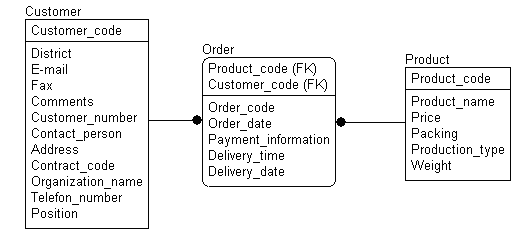
Рис. 2.6. Модель данных в виде схемы типа «звезда»

Рис. 2.7. Модель данных в виде схемы типа «снежинка»