Вопросы по дисциплине «Управление данными»
1. Банки данных. Основные понятия банков данных и знаний. Предметная область банка данных. Банк данных как автоматизированная система.
Банк данных (система баз данных) – это система специальным образом организованных баз данных, программных, технических, языковых, организационно–методических средств, предназначенных для обеспечения централизованного накопления и коллективного многоцелевого использования данных
Предметная область банка данных — это область применения конкретного БнД.
Различают банки данных, применяемые в сфере управления предприятиями и организациями, транспортом, в медицине, научных исследованиях (пример: биржа занятости)
Требования к БнД:
- адекватность отображения предметной области (полнота, целостность и непротиворечивость данных, актуальность информации);
- возможность взаимодействия пользователей разных категорий и в разных режимах, обеспечение высокой эффективности доступа для разных приложений;
- дружелюбность интерфейсов и малое время на освоение системы;
- обеспечение секретности и конфиденциальности для некоторой части данных; определение групп пользователей и их полномочий;
- обеспечение взаимной независимости программ и данных;
- обеспечение надежности функционирования БнД, защита данных от случайного и преднамеренного разрушения; возможность быстрого и полного восстановления данных в случае их разрушения; технологичность обработки данных, приемлемые характеристики функционирования БнД (стоимость обработки, время реакции системы на запросы, требуемые машинные ресурсы).
2. Понятие СУБД, основные функции СУБД.
СУБД — это программное обеспечение для создания и редактирования баз данных, просмотра и поиска информации в них.
По технологии обработки базы данных делятся на централизованные (хранится в памяти одной машины) и распределенные (БД состоит из нескольких частей, хранимых на нескольких машинах вычислительной сети. Работа с такой базой осуществляется с помощью системы управления распределенной базой данных — СУРБД).
Централизованные базы данных по способу доступа делятся на:
— БД с локальным доступом (данные и процедуры обработки хранятся на 1 машине);
— БД с сетевым доступом. СУБД с удаленным доступом могут быть построены с использованием архитектур файл-сервер и клиент-сервер.
Основные функции СУБД:
- управление данными во внешней памяти (на дисках);
- управление данными в оперативной памяти с использованием дискового кэша;
- журнализация изменений, резервное копирование и восстановление БД после сбоев;
- поддержка языков БД (язык определения данных, язык манипулирования данными).
3. База данных как информационная модель предметной области. Основы теории реляционных баз данных. Архитектура систем базы данных. Обзор промышленных СУБД.
База данных – это интегрированная совокупность структурированных и взаимосвязанных данных, организованная по определенным правилам, которые предусматривают общие принципы описания, хранения и обработки данных. Обычно база данных создается для предметной области.
СУБД – это компьютерная программа, ответственная за создание, редактирование, удаление и, как правило, хранение баз данных или коллекций записей данных.
Тип СУБД определяется моделью баз данных. Модель БД – способ, с помощью которого выполняется хранение, управление и администрирование.
СУБД обеспечивает:
- описание и сжатие данных;
- манипулирование данными;
- физическое размещение и сортировку записей;
- защиту от сбоев, поддержку целостности данных и их восстановление;
- работу с транзакциями и файлами;
- безопасность данных.
Реляционная модель связана с тремя аспектами данных: объектами данных (структурой данных), целостностью данных и обработкой данных. Основной структурной частью (объектом) реляционной модели является отношение.
Промышленные СУБД — такой вид СУБД, который может одновременно обслуживать большое количество пользователей. Основные требования:
- управление данными во внешней памяти (на дисках);
- управление данными в оперативной памяти с использованием дискового кэша;
- журнализация изменений, резервное копирование и восстановление базы данных после сбоев;
- поддержка языков БД (язык определения данных, язык манипулирования данными).
Примерами промышленных СУБД являются системы: Oracle Databse Engine, Microsoft SQL Server, PostgreSQL.
Возможности Oracle Database Engine:
- MVCC — многоверсионность данных для управления параллельными транзакциями
- Секционирование — реализованное во многих СУБД разделение хранимых объектов баз данных на отдельные части с раздельными параметрами физического хранения. Используется в целях повышения управляемости, производительности и доступности для больших баз данных.
- Automatic Storage Management — автоматическое управление хранением файлов БД
- Аналитические функции в SQL — возможности по проведению анализа данных на уровне движка СУБД.
- Многопоточность
- Flashback Query
- RAC — Кластеризация.
- Объектно-ориентированные свойства — поддержка работы с объектами как в ООП
- Automatic Database Diagnostic Monitoring — автоматический мониторинг и диагностика БД для выявления проблем производительности и, возможно, автоматической корректировки (если таковая определена администратором)
- Подсказки для изменения плана выполнения запроса
Возможности PostgreSQL:
- Встроенный процедурный язык PL/pgSQL, во многом аналогичный языку PL/SQL, используемому в СУБД Oracle;
- Скриптовые языки — PL/Lua, PL/LOLCODE, PL/Perl, PL/PHP, PL/Python, PL/Ruby, PL/sh, PL/Tcl и PL/Scheme;
- Классические языки — C, C++, Java (через модуль PL/Java);
- Статистический язык R (через модуль PL/R).
Триггеры определяются как функции, инициируемые DML-операциями. Например, операция INSERT может запускать триггер, проверяющий добавленную запись на соответствия определённым условиям. При написании функций для триггеров могут использоваться различные языки программирования
Многоверсионность (MVCC) — PostgreSQL поддерживает одновременную модификацию БД несколькими пользователями с помощью механизма Multiversion Concurrency Control (MVCC). Благодаря этому соблюдаются требования ACID, и практически отпадает нужда в блокировках чтения.
Наследование — таблицы могут наследовать характеристики и наборы полей от других таблиц (родительских). При этом данные, добавленные в порождённую таблицу, автоматически будут участвовать (если это не указано отдельно) в запросах к родительской таблице.
Возможности Microsoft SQL:
- Analysis Services — являются основными службами по обеспечению быстрого анализа бизнес-данных, интерактивной аналитической обработки (OLAP) и функций интеллектуального анализа данных для использования в приложениях бизнес-аналитики.
- Репликация
- Кластеризация
- Построение отчётов на уровне сервера
- Полнотестовый поиск
- Объектно-ориентированные свойства.
4. Понятие транзакции, свойства транзакции, способы завершения транзакции.
Транзакция — группа последовательных операций с базой данных, которая представляет собой логическую единицу работы с данными. Транзакция может быть выполнена либо целиком и успешно, соблюдая целостность данных и независимо от параллельно идущих других транзакций, либо не выполнена вообще и тогда она не должна произвести никакого эффекта. Транзакции обрабатываются транзакционными системами, в процессе работы которых создаётся история транзакций.
Различают последовательные (обычные), параллельные и распределённые транзакции. Распределённые транзакции подразумевают использование больше чем одной транзакционной системы и требуют намного более сложной логики (например, двухфазный протокол фиксации транзакции). В некоторых системах реализованы автономные транзакции, или под-транзакции, которые являются автономной частью родительской транзакции.
Свойства транзакций:
- Атомарность — гарантирует, что никакая транзакция не будет зафиксирована в системе частично. Будут либо выполнены все её подоперации, либо не выполнено ни одной.
- Согласованность — в соответствии с этим требованием, система находится в согласованном состоянии до начала транзакции и должна остаться в согласованном состоянии после завершения транзакции.
- Изолированность — во время выполнения транзакции параллельные транзакции не должны оказывать влияние на её результат.
- Надежность — независимо от проблем на нижних уровнях (к примеру, обесточивание системы или сбои в оборудовании) изменения, сделанные успешно завершённой транзакцией, должны остаться сохранёнными после возвращения системы в работу.
Возможны два варианта завершения транзакции. Если все операторы выполнены успешно и в процессе выполнения транзакции не произошло никаких сбоев программного или аппаратного обеспечения, транзакция фиксируется.
Фиксация транзакции — это действие, обеспечивающее запись на диск изменений в базе данных, которые были сделаны в процессе выполнения транзакции.
До тех пор пока транзакция не зафиксирована, допустимо аннулирование этих изменений, восстановление базы данных в то состояние, в котором она была на момент начала транзакции. Фиксация транзакции означает, что все результаты выполнения транзакции становятся постоянными. Они станут видимыми другим транзакциям только после того, как текущая транзакция будет зафиксирована. До этого момента все данные, затрагиваемые транзакцией, будут видны пользователю в состоянии на начало текущей транзакции.
Если в процессе выполнения транзакции случилось нечто такое, что делает невозможным ее нормальное завершение, база данных должна быть возвращена в исходное состояние. Откат транзакции — это действие, обеспечивающее аннулирование всех изменений данных, которые были сделаны операторами SQL в теле текущей незавершенной транзакции.
Каждый оператор в транзакции выполняет свою часть работы, но для успешного завершения всей работы в целом требуется безусловное завершение всех их операторов. Группирование операторов в транзакции сообщает СУБД, что вся эта группа должна быть выполнена как единое целое, причем такое выполнение должно поддерживаться автоматически.
5. Основные подходы к обеспечению параллельного выполнения транзакций. Проблемы параллельного выполнения транзакций. Проблема пропавших изменений. Проблема промежуточных данных.
Проблемы, возникающие при параллельном выполнении транзакций:
- Пропавшие изменения — две транзакции одновременно изменяют одну и ту же запись в БД. Изменения, сделанные второй программой, игнорируются первой программой.
- Проблемы промежуточных данных — второе приложение имеет доступ к промежуточным данным, которые сформировало первое приложение.
- Проблемы несогласованных данных
- Проблемы строк-призраков (строк-фантомов).
6. Основные подходы к обеспечению параллельного выполнения транзакций. Проблема несогласованных данных. Проблема данных–призраков.
Несогласованные данные — первое приложение может изменять данные, которые уже прочитало второе приложение.
Строки-призраки — приложение выполняет два одинаковых запроса и получает два разных результата. БД находится в согласованном состоянии, но приложение работает некорректно.
Процедура согласованного выполнения параллельных транзакций
В ходе выполнения транзакции пользователь видит только согласованные данные. Пользователь не должен видеть несогласованных промежуточных данных. Когда в БД две транзакции выполняются параллельно, то СУБД гарантированно поддерживает принцип независимого выполнения транзакций, который гласит, что результаты выполнения транзакций будут такими же, как если бы вначале выполнялась транзакция 1, а потом транзакция 2, или наоборот, сначала транзакция 2, а потом транзакция 1
7. Синхронизация запросов к БД с использованием блокировок. Элементы БД. Необходимость блокировки элементов БД. Элемент как примитив синхронизации.
Основная идея блокировки проста: в случае, когда для выполнения некоторой транзакции необходимо, чтобы некоторый объект базы данных не изменялся непредсказуемо и без ведома этой транзакции, такой объект блокируется.
Эффект блокировки состоит в блокировании доступа к объекту со стороны других транзакций и предотвращении непредсказуемого изменения состояния объекта.
Блокировки накладывают в соответствии с правилами совместимости блокировок, исключающими конфликты: чтение–запись, запись–чтение, запись–запись.
Выбор размера блокируемых элементов
Большие: база данных, совокупность связанных отношений, отношение
(элементы, подобные отношениям)
Малые: совокупность кортежей , отдельные кортежи, компоненты кортежей.
Выбор больших элементов сокращает накладные расходы системы по поддержанию блокировок, тогда как выбор малых элементов дает возможность параллельного исполнения многих транзакций. Блокировка на нижних уровнях приводит к перегрузке менеджера блокировок и, как следствие, к падению производительности системы.
С другой стороны, блокировка на высоком уровне мешает конкурирующим пользователям (транзакциям) получить доступ к нужным записям.
8. Легальное расписание. Бесконечные ожидания. Решение проблемы бесконечного ожидания.Тупики. Способы предотвращения тупиков.
Элемент должен быть блокирован до начала чтения или записи, операция блокирования действует как примитив синхронизации. Если транзакция пытается блокировать уже блокированный элемент, ей придется ждать, пока блокировка не будет снята по команде разблокирования, которая выполняется транзакцией, установившей блокировку каждая программа в конце концов должна разблокировать любой элемент, который она блокировала.
Расписание элементарных шагов двух или более транзакции, такое, что выполняются указанные выше правила, касающиеся блокировок, называется легальным.
Бесконечные ожидания и тупики
T1 : LOCK A;……………………; UNLOCK A;
Т2: LOCK A;……………………; UNLOCK A;
Т3: LOCK A;……………………; UNLOCK A;
Т4: LOCK A;……………………; UNLOCK A;
………………………………………………………..
Состояние такого рода называется бесконечным ожиданием. Система предоставления блокировок должна регистрировать все неудовлетворенные немедленно запросы и предоставлять возможность блокировки элемента после его разблокирования первой запросившей ее транзакции из числа ожидающих стратегия («первым вошел — первым обслуживается») устраняет бесконечные ожидания.
Тупики
Т1: LOCK A; LOCK В; ……………. UNLOCK A; UNLOCK В;
Т2 : LOCK В; LOCK A; …………… UNLOCK В; UNLOCK A;
Ни одна транзакция не может продолжаться. Каждая из них ожидает, пока другая разблокирует требуемый для нее элемент. Поэтому Т1 и Т2 будут ждать бесконечно
Ситуация, при которой каждая из множества S двух или более транзакций ожидает, когда ей будет предоставлена возможность заблокировать элемент, заблокированный в данный момент времени какой-либо иной транзакцией из данного множества S, называется тупиком.
Способы предотвращения тупиков: потребовать, чтобы каждая транзакция единовременно запрашивала все нужные ей блокировки. Пусть система либо полностью удовлетворяет такой запрос, либо не предоставляет вообще никаких блокировок и заставляет данную транзакцию ждать, если один или более требуемых элементов заблокирован другой транзакцией каждая программа в конце концов должна разблокировать любой элемент, который она блокировала.
9. Трехуровневая архитектура СУБД. Средства СУБД для реализации трехуровневой архитектуры.
Основная цель системы управления базами данных заключается в том, чтобы предложить пользователю абстрактное представление данных, скрыв конкретные особенности хранения и управления ими.
Комитет ANSI/SPARC — использование трехуровневого подхода. Основное внимание сконцентрировано на необходимости воплощения независимого уровня для изоляции программ от особенностей представления данных на более низком уровне.
Архитектура, в соответствие с которой СУБД должна обеспечивать три уровня абстракции (представления) данных в настоящее время наиболее распространена.
Наиболее фундаментальным моментом здесь является идентификация трех уровней абстракции, т.е. трех различных уровней описания элементов данных
Они и формируют трехуровневую архитектуру, которая охватывает:
- внешний уровень (Ориентирован на пользователей АИС и связан с их представлениями об информации. На этом уровне БД представляется как совокупность информационных моделей для выполнения тех или иных запросов)
- концептуальный уровень (Определяет общее содержание информационной базы. БД — общая информационная модель предметной области)
- внутренний уровень (Связан со способами фактического хранения данных во внешней памяти компьютера и предназначен для достижения оптимальной производительности и обеспечения экономного использования дискового пространства)
Цель трехуровневой архитектуры — отделение пользовательского представления БД от её физического представления. Ниже внутреннего уровня находится физический уровень, который контролируется операционной системой, но под руководством СУБД. Стандартным языком наиболее распространенных в настоящее время реляционных СУБД является язык SQL (Structured Query Language).
10. Инфологический и даталогический уровни моделирования предметной области. Объекты, атрибуты, связи. Первичный и вторичные ключи. Основные типы абстракции.
Предметная область — множество объектов и отношений (связей) между ними. С наиболее общей точки зрения объект—это то, о чем мы собираем и храним данные. Каждый из объектов выделяется из предметной области описывается при помощи определения совокупности присущих ему свойств.
В общем случае объект идентифицируется набором некоторых атомарных значений, т.е. атрибутов.
Совокупность однородных объектов можно объединить в категорию тип объекта.
Совокупность однородных атрибутов можно объединить категорию тип атрибута.
Все атрибуты заданного типа имеют одинаковый формат, интерпретацию и диапазон значений
Атрибут – поименованная характеристика объекта. Его наименование должно быть уникальным для конкретного типа объекта, но может быть одинаковым для объектов различных типов. Если объект некоторого типа представлен набором атрибутов заданных типов, то различные наборы значений (экземпляров) атрибутов этих типов будут описывать различные экземпляры объектов заданного типа.
Для объектов каждого типа может быть выделен атрибут, или группа атрибутов, значения которых однозначно определяют экземпляры объектов. Такой атрибут (группа атрибутов) называют идентификатором объекта (первичным ключом). Из сказанного следует свойство уникальности первичного ключа.
Наряду с первичными в моделировании данных широко используются вторичные ключи, позволяющие идентифицировать некоторую группу экземпляров объекта заданного типа.
Вторичные ключи широко применяются для поиска в базе данных подмножеств объектов, обладающих заданными свойствами.
Связь – ассоциирование двух или более объектов.
Связи показывают, каким образом объекты соотносятся или взаимодействуют между собой. Связи обеспечивают возможность отыскания одних объектов по значениям других. В моделировании данных выделяют связи: «один к одному», «один ко многим», «многие к одному», «многие ко многим».
Типы абстракции:
Классификация позволяет определить некоторый тип объекта путем соотнесения с ним конкретных экземпляров некоторых объектов.
Обобщение формирует новый тип объекта на основе соотнесения множества типов объектов с общим типом.
Агрегация представляет собой способ абстракции, при котором новый объект формируется на основе связей с другими (базовыми) объектами
11. Инфологическое моделирование: функциональный и предметный подходы к проектированию БД, проектирование с использованием метода «Сущность–связь». Модель «сущность–связь». Связи, классификация и характеристика связей.
Цель инфологического моделирования – обеспечение наиболее естественных для человека способов сбора и представления той информации, которую предполагается хранить в создаваемой базе данных.
Классы семантических моделей:
- Модель сущность – связь
- Бинарные модели данных (модель Сенко, модель Браччи, модель Абриаля и др.)
- Семантические сети (разные виды семантических сетевых моделей данных);
- Инфологические модели, ориентированные на представление структур и данных реального мира. Инфологическая модель здесь рассматривается как расширение модели «сущность – связь»
Цель инфологического моделирования – обеспечение наиболее естественных для человека способов сбора и представления той информации, которую предполагается хранить в создаваемой базе данных.
Модель Чена «сущность – связь» (или «объект – отношение») стала фактическим стандартом при инфологическом моделировании баз данных.
Основными конструктивными элементами инфологических моделей являются сущности, связи между ними и их свойства (атрибуты).
Сущность = Объект
Объектом (сущностью) называется «предмет, который может быть четко классифицирован»
Сущность – это объект, о котором в системе будет накапливаться информация..
тип сущности, экземпляр сущности
Слабая сущность находится в зависимости от некоторого другого объекта, она не может существовать, если не существует этот другой объект.
Сильная сущность существует сама по себе
Слабые: подчинённые, дочерние
Сильные – правильные, базовые основные, родительские, стержневые.
Связь — ассоциирование двух или более сущностей; определяется как «ассоцоация сущностей», при которой каждый экземпляр одной сущности ассоциирован с произвольным (в том числе, и нулевым) количеством экземпляров другой сущности.
существует принципиальная разница между типом связи и экземпляром связи.
Каждая связь характеризуется именем, обязательностью, типом и степенью.
Связь может быть обязательной, если в данной связи должен участвовать каждый экземпляр сущности, необязательной — если не каждый экземпляр сущности должен участвовать в данной связи. Связь может быть обязательной с одной стороны и необязательной с другой стороны. Степень связи определяется количеством сущностей, которые охвачены данной связью. Различают: бинарные связи, тернарные связи, связи более высоких порядков, семантика которых иногда очень сложна.
12. Выбор модели данных. Иерархическая, сетевая и реляционная модели данных, их типы структур, основные операции и ограничений
Известны три разновидности информационно-логической модели:
- иерархическая модель данных (ИМД) основана на графическом способе и предусматривает поиск данных по одной из ветвей "дерева", в котором каждая вершина имеет только одну связь с вершиной более высокого уровня. Для осуществления поиска необходимо указать полный путь к данным, начиная с корневого элемента;
- сетевая модель данных (СМД) также основана на графическом способе, но допускает усложнение дерева без ограничения количества связей, входящих в вершину. Это позволяет строить сложные поисковые структуры;
- в реляционной модели баз данных (РМД) реализуется табличный способ. В РМД таблица называется отношением, строка – кортежем, а столбцы – атрибутами.
13. Реляционная модель данных: понятие отношения, домена, кортежа, атрибута. Представление отношения в виде таблицы. Основные достоинства реляционного подхода.
Реляционная модель связана с тремя аспектами данных: объектами данных (структурой данных), целостностью данных и обработкой данных.
Основной структурной частью (объектом) реляционной модели является отношение.
Отношением R, определенным на множествах D1, D2,…,Dn (n ≥ 1), необязательно различных, называется подмножество декартова произведения D1× D2×…× Dn.
Исходные множества D1, D2,…,Dn называются доменами отношения
Элементы декартова произведения d1× d2×…× dn называются кортежами.
Домен представляет собой именованное множество атомарных значений одного типа. Отношение удобно представить в виде таблицы, столбцы которой соответствуют вхождениям доменов в отношение, а строки – наборам из n значений, взятых их исходных доменов, и расположенным в соответствии с заголовком отношения. Столбцы отношения называют атрибутами, а строки – кортежами. Достоинствами реляционного подхода принято считать следующие свойства: реляционный подход основывается на небольшом числе интуитивно понятных абстракций, на основе которых возможно простое моделирование наиболее распространенных предметных областей; эти абстракции могут быть точно и формально определены; теоретическим базисом реляционного подхода к организации баз данных служит простой и мощный математический аппарат теории множеств и математической логики; реляционный подход обеспечивает возможность ненавигационного манипулирования данными без необходимости знания конкретной физической организации баз данных во внешней памяти.
14. Схема отношения, схема базы данных. Фундаментальные свойства отношений.
Отношение содержит две части: заголовок и тело. Схемы двух отношений называются эквивалентными, если они имеют одинаковую степень и возможно такое упорядочение имен атрибутов в схемах, что на одинаковых местах будут находиться сравнимые атрибуты, т.е. атрибуты, принимающие значения из одного домена.
Схема БД (в структурном смысле) — это набор именованных схем отношений. Тогда реляционная БД – это набор отношений, имена которых совпадают с именами схем отношений в схеме БД.
Отношение – это множество кортежей, соответствующих одной схеме отношения.
Атрибут, значение которого однозначно идентифицирует кортежи, называется ключевым (или просто ключом). Если кортежи идентифицируются только сцеплением значений нескольких атрибутов, то говорят, что отношение имеет составной ключ.
Отношение может содержать несколько ключей. Всегда один из ключей объявляется первичным, его значения не могут обновляться. Все остальные ключи отношения называются возможными (потенциальными или альтернативными) ключами.
Свойства отношений:
• Отсутствуют одинаковые кортежи
• Отсутствует упорядоченность кортежей
• Отсутствует упорядоченность атрибутов
• Все значения атрибутов атомарные
15. Нормализованные отношения. Первичные и вторичные ключи отношений. Моделирование связей в реляционной модели данных. Внешние ключи.
Согласно свойствам отношений, каждый кортеж в целом уникален, однако отдельные атрибуты могут содержать и повторяющиеся значения. Тем не менее, в каждом отношении можно выделить хотя бы одну группу атрибутов, содержащих гарантированно уникальные значения.
Различают простые и составные потенциальные ключи (например, серия и номер паспорта - составной потенциальный ключ, а ИНН — простой).
В каждом отношении можно выделить один или несколько потенциальных ключей. Если таких ключей несколько, один из них выбирается в качестве первичного ключа. Первичные ключи используются в качестве общих столбцов для связывания таблиц. Поэтому в качестве первичного ключа обычно выбирают самый короткий, чаще всего, числовой атрибут, для которого гарантируется не только уникальность, но и неизменность значений. На практике часто невозможно выделить такой атрибут, в этом случае используют дополнительный атрибут, называемый суррогатным ключом, который автоматически заполняется уникальными значениями и никогда не изменяется. Все потенциальные ключи отношения, которые не являются первичным ключом, называются альтернативными ключами. Ни в одном из потенциальных ключей NULL-значения недопустимы. Первичный ключ родительского отношения, экспортированный в дочернее отношение в качестве связующего атрибута, называется внешним ключом дочернего отношения. Посредством внешнего ключа кортежи дочернего отношения ссылаются на соответствующие им кортежи родительского отношения.
16. Целостность реляционных баз данных: Null-значения. Трехзначная логика (3VL).
Целостность данных понимается как правильность данных в любой момент времени при манипулировании данными. Поддержание целостности базы данных может рассматриваться как защита данных от неверных изменений или разрушений.
В классическом понимании поддержка целостности включает 3 части: структурная, языковая, ссылочная. Эти 3 вида целостности определяют допустимую форму представления и обработки информации в реляционных БД. Для определения некоторых ограничений, связанных с содержанием БД, используется другой вид целостности:
• Семантическая целостность;
Структурная целостность подразумевает, что реляционная СУБД может работать только с реляционными отношениями.
Требование структурной целостности осуществляется с помощью двух ограничений:
• при добавлении кортежей в отношение проверяется уникальность их первичных ключей
• не допускается, чтобы какой-либо атрибут, участвующий в первичном ключе, принимал неопределенное значение.
Здесь возникает необходимость рассмотреть проблему неопределенных значений (Null-значений). Неопределенное значение интерпретируется в реляционной модели как значение, неизвестное на данный момент времени. При сравнении неопределенных значений не действуют стандартные правила сравнения: одно Null-значение никогда не считается равным другому Null-значению.
Для выявления равенства значения некоторого атрибута неопределенному применяют стандартные предикаты:
• <Имя атрибута> Is Null
• <Имя атрибута> Is Not Null
Введение Null-значений привело к модификации классической двузначной логики к трехзначной.
17. Реляционная алгебра. Теоретико–множественные операции реляционной алгебры. Реляционное исчисление.
Одним из аспектов реляционной модели данных является обработка данных, осуществляемая с помощью операторов реляционной алгебры. В основном операторы имеют на входе отношения и возвращают отношения в качестве результата.
Реляционная алгебра состоит из восьми операторов: четырех традиционных операций над множествами (теоретико-множественных операций) и четырех специальных реляционных операций.
В манипуляционной части реляционной модели утверждаются два фундаментальных механизма манипулирования реляционными БД — реляционная алгебра и реляционное исчисление. Первый механизм базируется в основном на классической теории множеств, а второй — на математической логике.
В состав теоретико-множественных операций входят операции:
• объединения отношений;
• пересечения отношений;
• взятия разности отношений;
• прямого произведения отношений.
Специальные реляционные операции включают:
• ограничение отношения;
• проекцию отношения;
• соединение отношений;
• деление отношений.
Кроме того, в состав алгебры включается операция присваивания, позволяющая сохранить в базе данных результаты вычисления алгебраических выражений, и операция переименования атрибутов, дающая возможность корректно сформировать заголовок (схему) результирующего отношения.
Главное отличие теоретико-множественных операций (за исключением декартова произведения) от всех других, выполняемых СУБД, состоит в том, что каждая таблица должна иметь одинаковое число колонок и каждая пара колонок для любой позиции таблицы должна быть определена с одинаковым типом и масштабом.
18. Основные положения нормализации отношений. Понятие функциональной зависимости. Типы функциональных зависимостей.
Концепция функциональной зависимости чрезвычайно удобна для анализа структуры данных. Рассматривая любой кортеж Т и два набора атрибутов этого кортежа {Х1,...,Хп} и {Yl,...,Yn} (множества X и Y не обязательно являются взаимоисключающими) говорят, что Y функционально зависит от X, если для каждого возможного значения X существует единственно возможное соответствующее значение Y.
На практике функциональная зависимость — удобный способ отразить тот очевидный факт, что для любого отношения существует некий набор атрибутов, уникальный для каждого кортежа данного отношения, и зная этот набор, можно определить значения других, неуникальных атрибутов.
Если {X} является ключом-кандидатом, то все атрибуты {Y} функционально зависимы от {X}: это следует из определения ключа-кандидата. Если {X} не является ключом-кандидатом, и функциональная зависимость нетривиальна (то есть {Y} не является подмножеством {X}), тогда отношение обязательно будет содержать избыточные данные и дальнейшей нормализации не избежать. До известной степени нормализация — это процесс, конечным результатом которого является диаграмма функциональной зависимости
19. Алгоритм нормализации отношений в первую нормальную форму, во вторую нормальную форму,в третью нормальную форму. Нормализация отношений в нормальную форму Бойса–Кодда.
Первая нормальная форма
Отношение находится в первой нормальной форме (сокращённо 1НФ), если все его атрибуты атомарны, то есть если ни один из его атрибутов нельзя разделить на более простые атрибуты, которые соответствуют каким-то другим свойствам описываемой сущности.
Вторая нормальная форма
Отношение находится во второй нормальной форме, если оно находится в первой нормальной форме, и кроме того, все его атрибуты зависят от полного набора атрибутов ключа-кандидата.
Третья нормальная форма.
Отношение находится в третьей нормальной форме, если оно находится во второй нормальной форме, и кроме того, все неключевые атрибуты совершенно независимы. Первые три нормальные формы были введены доктором Коддом в его оригинальной работе по реляционной теории, и в подавляющем большинстве случаев это все, о чем вам следует беспокоиться.
Нормальная форма Бойса-Кодда
Нормальная форма Бойса-Кодда рассматривается как вариант третьей нормальной формы. Она имеет дело со специальной разновидностью отношений, для которых существует несколько ключей-кандидатов. Фактически, чтобы применять нормализацию по Бойсу-Кодду, нужно сочетание нескольких условий:
• отношение должно иметь не менее двух ключей-кандидатов;
• по крайней мере два ключа-кандидата должны быть составными;
• ключи-кандидаты должны иметь перекрывающиеся атрибуты.
Простейший способ понять, что такое нормальная форма Бойса-Кодда — использовать функциональные зависимости. Нормальная форма Бойса-Кодда, в сущности, равносильна утверждению, что между ключами-кандидатам и отношения нет функциональных зависимостей.
20. Структурированный язык запросов SQL. История развития SQL. Управление базами данных с помощью SQL. Структура операторов и базовые элементы языка. Синтаксис оператора SELECT.
Разрабатываемые в начале 80-х языки запросов можно отнести к двум классам:
1. Алгебраические языки, позволяющие выражать запросы средствами специализированных операторов, применяемых к отношениям (JOIN — соединить, INTERSECT – пересечь, SUBTRACT — вычесть и т.д.).
2. Языки исчисления предикатов представляют собой набор правил для записи выражения, определяющего новое отношение из заданной совокупности существующих отношений.
Сегодня из всех этих языков полностью сохранились и развиваются
QBE (Query-By-Example — запрос по образцу);
SQL (Structured Query Language) – структурированный язык запросов;
Из остальных взяты в расширение внутренних языков СУБД только наиболее интересные конструкции.
Язык SQL стал фактически стандартным языком доступа к базам данных. Все СУБД, претендующие на название "реляционные", реализуют тот или иной диалект SQL:
SQL*Plus корпорации Oracle;
Transact-SQL для СУБД Microsoft SQL Server.
В диалектах язык может быть дополнен операторами процедурных языков программирования.
Основу языка SQL составляют операторы, условно разбитые не несколько групп по выполняемым функциям.
DDL (Data Definition Language) - операторы определения объектов базы данных:
DML (Data Manipulation Language) - операторы манипулирования данными:
DCL (Data Control Language) - операторы контроля данных
Операторы DDL
· CREATE TABLE - создать таблицу;
· ALTER TABLE - изменить таблицу;
· DROP TABLE - удалить таблицу;
…DOMAIN - создать домен;
…INDEX - создать индекс;
…COLLATION - создать последовательность;
…VIEW - создать представление
Операторы DML
· SELECT - отобрать строки из таблиц;
· INSERT - добавить строки в таблицу;
· UPDATE - изменить строки в таблице;
· DELETE - удалить строки в таблице;
Операторы DCL
· CREATE ASSERTION - создать ограничение;
· COMMIT - зафиксировать внесенные изменения;
· ROLLBACK - откатить внесенные изменения.
· GRANT - предоставить привилегии пользователю или приложению на манипулирование объектами;
· REVOKE - отменить привилегии пользователя или приложения.
SELECT SNUM, SFAM, SNAME, SOTCH, STIP
FROM STUDENTS;
или
SELECT * FROM STUDENTS;
21. Дополнительные аспекты реляционной технологии. Представления, их свойства и назначение.
· Проблемы, требующие решения
· Запросы
· Представления
· Курсоры
· Хранимые процедуры
· Триггеры
· Транзакции
· Функции, определяемые пользователем
На любом этапе проектирования можно выделить фрагменты модели, которые представляют интерес с точки зрения определённых групп пользователей. На этапе логического проектирования такие фрагменты принято называть подсхемами.
На физическом уровне подсхемы реализуются с помощью создания представлений.
Представление позволяет:
- скрывать служебную информацию (пользователям она не нужна и не интересна);
- предоставлять пользователям только ту информацию, которая им нужна для выполнения их должностных обязанностей;
- обеспечивать логическую независимость данных, то есть при изменении логической структуры данных не меняются пользовательские программы (так, добавление нового атрибута в таблицу или разбиение одной таблицы на две остаются невидимыми для пользовательских программ).
Механизм создания представлений аналогичен механизму создания запросов. Реально представление – это хранящийся в базе данных под каким-либо именем запрос.
Представление отличается от запроса тем, что при изменении данных в исходных таблицах схемы данных происходят изменения в представлениях, созданных на основании этих таблиц. Для того, чтобы увидеть результат изменения данных в запросе, его необходимо выполнить повторно.
Проектирование представлений – это одна из задач физического этапа проектирования баз данных, которая решается средствами СУБД на основании ранее принятых решений, согласованных с заказчиком.
22. Технология физического хранения и доступа к данным. Основные этапы доступа к базе данных.
Метод физического доступа — совокупность программных средств, обеспечивающих возможность хранения и выборки данных, расположенных на физических устройствах.
В физической БД следует рассматривать методы размещения (запись и хранение) данных и методы доступа (поиск) к ним.
Основными методами хранения и поиска являются физически последовательный, прямой, индексно-последовательный и индексно-произвольный. Для их сравнительной оценки используем два критерия:
- Эффективность хранения — величина, обратная среднему числу байтов вторичной памяти, необходимому для хранения одного байта исходной памяти;
- Эффективность доступа — величина, обратная среднему числу физических обращений, необходимых для осуществления логического доступа.
Выделяют первичные (физически последовательный и произвольный) и вторичные (мультисписковый, инвертированный файлы, двусвязное дерево) методы доступа.
Методы хранения и доступа:
- иерархический последовательный метод доступа (HSAM);
- иерархический прямой метод (HDAM);
- иерархический индексно-последовательный метод (HISAM);
- иерархический индексно-произвольный метод (HIDAM).
23. Технология физического хранения и доступа к данным. Процедура индексирования и хеширования.
Индексно-последовательный метод
Индексный файл упорядочен по первичному ключу (главному атрибуту физической записи). Индекс содержит ссылки не на каждую запись, а на группу записей. Последовательная организация индексного файла допускает, в свою очередь, его индексацию — многоуровневая индексация.
Процедура добавления возможна в двух видах.
- Новая запись запоминается в отдельном файле (области), называемом областью переполнения. Блок этой области связывается в цепочку с блоком, которому логически принадлежит запись. Запись вводится в основной файл
- Если места в блоке основного файла нет, запись делится пополам и в индексном файле создается новый блок.
Наличие индексного файла большого размера снижает эффективность доступа. В большой БД основным параметром становится скорость выборки первичных и вторичных ключей. При большой интенсивности обновления данных следует периодически проводить реорганизацию БД. Эффективность хранения зависит от размера и изменяемости БД, а эффективность доступа - от числа уровней индексации, распределения памяти для хранения индекса, числа записей в БД, уровня переполнения.
Индексно-произвольный метод.
Записи хранятся в произвольном порядке. Создается отдельный файл, хранящий значение действительного ключа и физического адреса (индекса). Каждой записи соответствует индекс. Между вырабатываемым (относительным) адресом и физической записью (абсолютным адресом) существует взаимнооднозначное соответствие.
Хеширование — метод доступа, обеспечивающий прямую адресацию данных путем преобразования значений ключа в относительный или абсолютный физический адрес.
Адрес является функцией значения поля и ключа записи. Записи, приобретающие один адрес, называются синонимами. В качестве критериев оптимизации алгоритма хеширования могут быть: потеря связи между адресом и значением поля, минимум синонимов. Память делится на страницы определенного размера, и все синонимы помещаются в пределах одной страницы или в область переполнения. Механизм поиска синонимов - цепочечный.
Любой элемент хеш-таблицы имеет особый ключ, а само занесение осуществляется с помощью хеш-функции, отображающей ключи на множество целых чисел, которые лежат внутри диапазона адресов таблицы.
Хеш-функция должна обеспечивать равномерное распределение ключей по адресам таблицы, однако двум разным ключам может соответствовать один адрес. Если адрес уже занят, возникает состояние, называемое коллизией, которое устраняется специальными алгоритмами: проверка идет к следующей ячейке до обнаружения своей ячейки. Элемент с ключом помещается в эту ячейку.
Для поиска используется аналогичный алгоритм: вычисляется значение хеш-функции, соответствующее ключу, проверяется элемент таблицы, находящийся по указанному адресу. Если обнаруживается пустая ячейка, то элемента нет.
Размер хеш-таблицы должен быть больше числа размещаемых элементов. Если таблица заполняется на шестьдесят процентов, то, как показывает практика, для размещения нового элемента проверяется в среднем не более двух ячеек. После удаления элемента пространство памяти, как правило, не может быть использовано повторно.
24. Обзор нотаций для построения ER-диаграмм. Нотации IE и IDEF1X.
Типичной формой документирования логической модели предметной области при ER-моделировании являются диаграммы «сущность-связь», или ER-диаграммы (Entity Relationship Diagram). ER-диаграмма позволяет графически представить все элементы логической модели согласно простым, интуитивно понятным, но строго определенным правилам — нотациям.
Для создания ER диаграмм обычно используют одну из двух наиболее распространенных нотаций:
• Integration DEFinition for Information Modeling (IDEF1X). Эта нотация была разработана для армии США и стала федеральным стандартом США. Кроме того, она является стандартом в ряде международных организаций (НАТО, Международный валютный фонд и др.).
• Information Engineering (IE). Нотация, разработанная Мартином (Martin), Финкельштейном (Finkelstein) и другими авторами, используется преимущественно в промышленности.
Построение ER-диаграмм, как правило, ведется с использованием CASE-средств.
25. Проектирование базы данных на основе ER-диаграмм. Получение реляционной схемы из ER-диаграммы.
Сущность на ER-диаграмме представляется прямоугольником с именем в верхней части. В прямоугольнике перечисляются атрибуты сущности, при этом атрибуты, составляющие уникальный идентификатор сущности, подчеркиваются. Каждый экземпляр сущности должен быть уникальным и отличаться от других атрибутов.
Получение реляционной схемы из ER-диаграммы.
1. Каждая простая сущность превращается в таблицу (отношение). Имя сущности становится именем таблицы.
2. Каждый атрибут становится возможным столбцом с тем же именем. Столбцы, соответствующие необязательным атрибутам, могут содержать неопределенные значения; столбцы, соответствующие обязательным атрибутам – не могут. Если атрибут является множественным, то для него строится отдельное отношение.
3. Компоненты уникального идентификатора сущности превращаются в первичный ключ. Если имеется несколько возможных уникальных идентификаторов, выбирается наиболее используемый.
4. Связи «многие к одному» и «один к одному» становятся внешними ключами. Т.е. создается копия уникального идентификатора с конца связи «один», и соответствующие столбцы составляют внешний ключ.
5. Индексы создаются для первичного ключа (уникальный индекс), а также внешних ключей и тех атрибутов, которые будут часто использоваться в запросах.
6. Если в концептуальной схеме присутствуют подтипы, то возможны два варианта.
Все подтипы хранятся в одной таблице, которая создается для самого внешнего супертипа, а для подтипов создаются представления. В таблицу добавляется по крайней мере один столбец, содержащий код типа, и он становится частью первичного ключа. Во втором случае для каждого подтипа создается отдельная таблица (для более нижних – представления) и для каждого подтипа первого уровня супертип воссоздается с помощью представления UNION (из всех таблиц подтипов выбираются общие столбцы – столбцы супертипа).
7. Если остающиеся внешние ключи все принадлежат одному домену, т.е. имеют общий формат, то создаются два столбца: идентификатор связи и идентификатор сущности. Столбец идентификатора связи используется для различных связей. Столбец идентификатора сущности используется для хранения значений уникального идентификатора сущности на дальнем конце соответствующей связи.
Если результирующие внешние ключи не относятся к одному домену, то для каждой связи, покрываемой дугой исключения, создаются явные столбцы внешних ключей.
26. Язык описания и редактирования данных (DDL). Создание и редактирование объектов базы данных (база данных, таблицы, ключи, индексы, связи).
DDL (Data Definition Language) — операторы определения объектов базы данных
Операторы DDL:
· CREATE TABLE - создать таблицу;
· ALTER TABLE - изменить таблицу;
· DROP TABLE - удалить таблицу;
…DOMAIN - создать домен;
…INDEX - создать индекс;
…COLLATION - создать последовательность;
…VIEW - создать представление;
Создание индекса:
CREATE [UNIQUE] INDEX <имя_индекса> ON <имя_таблицы> (<имя_столбца>,...)
27. Формализованное описание отношений. Манипулирование данными в реляционной модели. Операции реляционной алгебры.
Реляционная модель описывает представление данных в виде двумерной таблицы, называемойотношением. Наименованиями столбцов этой таблицы служат имена атрибутов. Рассмотрим формализованное описание соответствующих понятий.
Пусть A1, A2, ..., An имена атрибутов. Каждому имени атрибута Ai соответствует допустимое множество значений, которые может принимать атрибут Ai. Это множество значений Di называется доменом атрибута Ai, i=1,n. По определению, доменыявляются непустыми конечными или счетными множествами. Уточним, что в теории реляционных баз данных доменрассматривается как множество значений одного (причем простого) типа данных. Понятию домена Di соответствует множество значений, стоящих в столбце Ai рассматриваемой таблицы.
Схемой отношения R {A1, A2, ..., An} называется конечное множество имен атрибутов {A1, A2, ..., An}, причем атрибутAi принимает значение из множества Di (i=1, 2, ..., n), где n – арность отношения.
Понятию "схема отношения" соответствует описание структуры двумерной таблицы (имена столбцов и допустимые множества значений).
Пусть 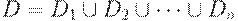 .
.
Отношением r со схемой R называется конечное множество отображений {t1, t2, ..., tp} из множества R: {A1, A2, ..., An} в множество 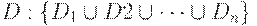 , таких, что
, таких, что  .
.
Отображение tk называется k -м кортежем, n – размерность кортежа.
Понятию k -го кортежа соответствует множество значений, стоящих в k -й строке рассматриваемой таблицы.
Понятию отношения r соответствует множество значений, стоящих во всех строках рассматриваемой таблицы.
Ключом отношения r со схемой R называется минимальное подмножество 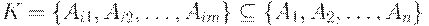 , где
, где 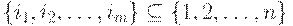 ,такое, что любые два различных кортежа
,такое, что любые два различных кортежа  не совпадают по значениям множества K ={Ai1, Ai2, ..., Aim}.
не совпадают по значениям множества K ={Ai1, Ai2, ..., Aim}.
Совокупность схем отношений, используемых для представления концептуальной модели, называется схемой реляционной базы данных (реляционной моделью данных). Текущие значения соответствующих отношений называются реляционной базой данных.
Для манипулирования данными в реляционной модели используются два формальных аппарата:
• реляционная алгебра, основанная на теории множеств;
• реляционное исчисление, базирующееся на исчислении предикатов первого порядка.
Механизмы реляционной алгебры и реляционного исчисления эквивалентны, т.е. для любого допустимого выражения реляционной алгебры можно построить эквивалентную формулу реляционного исчисления и наоборот.
Операции реляционной алгебры определены на множестве отношений и являются замкнутыми относительно этого множества(образуют алгебру). Оказывается, что любой произвольный запрос к БД можно представить в виде последовательности, составленной из пяти основных операций реляционной алгебры. Рассмотрим эти операции.
Объединение 
Объединением отношений r и s называется множество кортежей, которые принадлежат или r, или s, или им обоим. Для операции объединения требуется одинаковая арность отношений.
Разность r – s
Разностью отношений r и s называется множество кортежей, принадлежащих r, но не принадлежащих s. Для этой операции также требуется одинаковая арность отношений.
Декартово произведение r x s
Пусть r и s – отношения арности k1 и k2 соответственно. Декартовым произведением r x s называется множество кортежей длины k1+k2, первые k1 компонентов которых образуют кортежи, принадлежащие r, а последние k2 – кортежи, принадлежащие s.
Проекция  есть множество кортежей, получаемых из кортежей отношения r выбором столбцов с именамиAi1, Ai2, ..., Aim.
есть множество кортежей, получаемых из кортежей отношения r выбором столбцов с именамиAi1, Ai2, ..., Aim.
Выбор ( селекция ) 
Пусть F – формула, образованная: операндами, являющимися константами или именами атрибутов, арифметическими операторами сравнения, логическими операторами (и, или, не), тогда выбором (селекцией)  называется множество кортежей, компоненты которого удовлетворяют условию, заданному формулой F.
называется множество кортежей, компоненты которого удовлетворяют условию, заданному формулой F.
28. Классификация моделей данных. Даталогические модели (иерархическая, сетевая, реляционная).
Даталогические модели являются моделями концептуального уровня и разрабатываются для конкретной СУБД.
1) иерархическая модель данных (ИМД) основана на графическом способе и предусматривает поиск данных по одной из ветвей «дерева», в котором каждая вершина имеет только одну связь с вершиной более высокого уровня. Для осуществления поиска необходимо указать полный путь к данным, начиная с корневого элемента;
2) сетевая модель данных (СМД) также основана на графическом способе, но допускает усложнение «дерева» без ограничения количества связей, входящих в вершину. Это позволяет строить сложные поисковые структуры;
3) в реляционной модели баз данных (РМД) реализуется табличный способ. В РМД таблица называется отношением, строка – кортежем, а столбцы – атрибутами.
29. Логическая и физическая модели данных. Трехуровневая архитектура ANSI/SPARC.
Предметная область — это часть реального мира, данные о которой мы хотим отразить в базе данных.
Модель предметной области — это наши знания о предметной области
Логическая модель данных. На следующем, более низком уровне находится логическая модель данных предметной области. Логическая модель описывает понятия предметной области, их взаимосвязь, а также ограничения на данные, налагаемые предметной областью.
Логическая модель данных является начальным прототипом будущей базы данных. Логическая модель строится в терминах информационных единиц, но без привязки к конкретной СУБД. Более того, логическая модель данных необязательно должна быть выражена средствами именно реляционной модели данных. Основным средством разработки логической модели данных в настоящий момент являются различные варианты ER-диаграмм.
Физическая модель данных. На еще более низком уровне находится физическая модель данных. Физическая модель данных описывает данные средствами конкретной СУБД. Мы будем считать, что физическая модель данных реализована средствами именно реляционной СУБД, хотя, как уже сказано выше, это необязательно. Отношения, разработанные на стадии формирования логической модели данных, преобразуются в таблицы, атрибуты становятся столбцами таблиц, для ключевых атрибутов создаются уникальные индексы, домены преображаются в типы данных, принятые в конкретной СУБД.
Комитет ANSI/SPARC — использование трехуровневого подхода. Основное внимание сконцентрировано на необходимости воплощения независимого уровня для изоляции программ от особенностей представления данных на более низком уровне.
архитектура, в соответствие с которой СУБД должна обеспечивать три уровня абстракции (представления) данных в настоящее время наиболее распространена.
Наиболее фундаментальным моментом здесь является идентификация трех уровней абстракции, т.е. трех различных уровней описания элементов данных
Они и формируют трехуровневую архитектуру, которая охватывает: внешний уровень, концептуальный уровень, внутренний уровень.
Цель трехуровневой архитектуры заключается в отделении пользовательского представления базы данных от ее физического представления
30. Базы данных в экономических информационных системах.
Базы данных представляют собой качественно новый этап в организации данных. До возникновения технологии баз данных преобладал позадачный подход. При нем приходилось, как говорилось выше, каждый раз повторять операции ввода и вывода информации, потому что каждая программа использовала свои данные, изолированные от других задач.
При решении вопросов экономики и управления предприятием значительно меньше времени будет затрачено на ввод требуемой информации единожды. Любая информация, к примеру о сотрудниках предприятия, может быть сформулирована один раз и быть доступной для всех информационных подсистем (кадровый учет, планирование, финансовое управление и многие другие).
Наряду со снижением трудоемкости возникает другое преимущество использования баз данных – возможность независимости сбора и актуализации данных. Актуализация данных – обновление собранных данных на определенную дату. Данное преимущество обосновывается тремя подходами. Во-первых, появляется возможность разновременной актуализации без опасения по поводу возникновения глобальных ошибок. Во-вторых, появляется возможность модернизировать пакеты прикладных программ, работающие с базой данных, не нарушая функционирование самой базы программ других подразделений. В-третьих, возможность отделения базы данных от прикладных программ позволяет ускорить внедрение или модернизацию средств информационных технологий при разделении работы между группами внедрения или поддержки.
Процедуры актуализации занимают важное место в программном обеспечении баз данных. Если система является совокупностью баз данных отдельных пользователей, то актуализация возлагается на них, и соответствующие программные механизмы применять нет необходимости. В случае, когда база данных используется для системных применений, используется система актуализации. Административное и программное обеспечение последней возлагается на администратора.
Административное обеспечение представляет собой должностные инструкции о порядке ввода информации, сроках, формах актуализации, ответственных за это лицах. При больших размерах базы данных администрируются ее отдельные составные части.