R Предвыборка данных
Блок предвыборки данных (Prefetch) очень похож по принципу своего действия на блок предсказания ветвлений — с той только разницей, что в данном случае речь идёт не о коде, а о данных. Общий принцип действия такой же: если встроенная схема анализа доступа к данным в ОЗУ решает, что к некоему участку памяти, ещё не загруженному в кэш, скоро будет осуществлён доступ — она даёт команду на загрузку данного участка памяти в кэш ещё до того, как он понадобится исполняемой программе. Результативно работающий блок предвыборки позволяет существенно сократить время доступа к нужным данным, и, соответственно, повысить скорость исполнения программы. К слову: грамотный Prefetch очень хорошо компенсирует высокую латентность подсистемы памяти, подгружая нужные данные в кэш, и тем самым, нивелируя задержки при доступе к ним, если бы они находились не в кэше, а в основном ОЗУ.
R Архитектура EPIC - Explicitly Parallel Instruction Computing и процессор Intel Itanium
Архитектура EPIC основывается на архитектуре VLIW (Very long instruction word — «очень длинная машинная команда») — архитектура процессоров с несколькими вычислительными устройствами. Характеризуется тем, что одна инструкция процессора содержит несколько операций, которые должны выполняться параллельно.
В суперскалярных процессорах также есть несколько вычислительных модулей, но задача распределения между ними работы решается аппаратно. Это сильно усложняет дизайн процессора, и может быть чревато ошибками. В процессорах VLIW задача распределения решается во время компиляции и в инструкциях явно указано, какое вычислительное устройство должно выполнять какую команду.
5. Классификация и типы ВС. Многомашинные и многопроцессорные ВС. Представление ВС на основе распределения потоков команд и данных (классификация Флинна)
R Классификация архитектур по параллельной обработке данных
В 1966 г. М.Флинном (Flynn) был предложен чрезвычайно удобный подход к классификации архитектур вычислительных систем. В его основу было положено понятие потока, под которым понимается последовательность элементов, команд или данных, обрабатываемая процессором. Соответствующая система классификации основана на рассмотрении числа потоков инструкций и потоков данных и описывает четыре архитектурных класса:
SISD = Single Instruction Single Data
MISD = Multiple Instruction Single Data
SIMD = Single Instruction Multiple Data
MIMD = Multiple Instruction Multiple Data
SISD (single instruction stream / single data stream) – одиночный поток команд и одиночный поток данных. К этому классу относятся последовательные компьютерные системы, которые имеют один центральный процессор, способный обрабатывать только один поток последовательно исполняемых инструкций. В настоящее время практически все высокопроизводительные системы имеют более одного центрального процессора, однако каждый из них выполняет несвязанные потоки инструкций, что делает такие системы комплексами SISD-систем, действующих на разных пространствах данных. Для увеличения скорости обработки команд и скорости выполнения арифметических операций может применяться конвейерная обработка. В случае векторных систем векторный поток данных следует рассматривать как поток из одиночных неделимых векторов. Примерами компьютеров с архитектурой SISD могут служить большинство рабочих станций Compaq, Hewlett-Packard и Sun Microsystems.
MISD (multiple instruction stream / single data stream) – множественный поток команд и одиночный поток данных. Теоретически в этом типе машин множество инструкций должно выполняться над единственным потоком данных. До сих пор ни одной реальной машины, попадающей в данный класс, создано не было. В качестве аналога работы такой системы, по-видимому, можно рассматривать работу банка. С любого терминала можно подать команду и что-то сделать с имеющимся банком данных. Поскольку база данных одна, а команд много, мы имеем дело с множественным потоком команд и одиночным потоком данных.
SIMD (single instruction stream / multiple data stream) – одиночный поток команд и множественный поток данных. Эти системы обычно имеют большое количество процессоров, от 1024 до 16384, которые могут выполнять одну и ту же инструкцию относительно разных данных в жесткой конфигурации. Единственная инструкция параллельно выполняется над многими элементами данных. Примерами SIMD-машин являются системы CPP DAP, Gamma II и Quadrics Apemille. Другим подклассом SIMD-систем являются векторные компьютеры. Векторные компьютеры манипулируют массивами сходных данных подобно тому, как скалярные машины обрабатывают отдельные элементы таких массивов. Это делается за счет использования специально сконструированных векторных центральных процессоров. Когда данные обрабатываются посредством векторных модулей, результаты могут быть выданы на один, два или три такта частотогенератора (такт частотогенератора является основным временным параметром системы). При работе в векторном режиме векторные процессоры обрабатывают данные практически параллельно, что делает их в несколько раз более быстрыми, чем при работе в скалярном режиме. Примерами систем подобного типа являются, например, компьютеры Hitachi S3600.
MIMD (multiple instruction stream / multiple data stream) – множественный поток команд и множественный поток данных. Эти машины параллельно выполняют несколько потоков инструкций над различными потоками данных. В отличие от упомянутых выше многопроцессорных SISD-машин, команды и данные связаны, потому что они представляют различные части одной и той же задачи. Например, MIMD-системы могут параллельно выполнять множество подзадач с целью сокращения времени выполнения основной задачи. Большое разнообразие попадающих в данный класс систем делает классификацию Флинна не полностью адекватной. Действительно, и четырехпроцессорный SX-5 компании NEC, и тысячепроцессорный Cray T3E попадают в этот класс. Это заставляет использовать другой подход к классификации, иначе описывающий классы компьютерных систем. Основная идея такого подхода может состоять, например, в следующем. Будем считать, что множественный поток команд может быть обработан двумя способами: либо одним конвейерным устройством обработки, работающем в режиме разделения времени для отдельных потоков, либо каждый поток обрабатывается своим собственным устройством. Первая возможность используется в MIMD-компьютерах, которые обычно называют конвейерными или векторными, вторая – в параллельных компьютерах. В основе векторных компьютеров лежит концепция конвейеризации, т.е. явного сегментирования арифметического устройства на отдельные части, каждая из которых выполняет свою подзадачу для пары операндов. В основе параллельного компьютера лежит идея использования для решения одной задачи нескольких процессоров, работающих сообща, причем процессоры могут быть как скалярными, так и векторными.
R Можно привести следующую классификацию архитектур параллельных ВС :

Машины SIMDраспались на две подгруппы. В первую подгруппу попадают многочисленные суперкомпьютеры и другие машины, которые оперируют векторами, выполняя одну и ту же операцию над каждым элементом вектора. Во вторую подгруппу попадают машины типа ILLIAC IV, в которых главный блок управления посылает команды нескольким независимым АЛУ.
В нашей классификации категория MIMD распалась на мультипроцессоры (машины с памятью совместного использования) и мультикомпьютеры (машины с передачей сообщений). Существует три типа мультипроцессоров. Они отличаются друг от друга по способу реализации памяти совместного использования. Они называются UMA (Uniform Memory Access — архитектура с однородным доступом к памяти), NUMA (NonUniform Memory Access — архитектура с неоднородным доступом к памяти)и СОМА (Cache Only Memory Access — архитектура с доступом только к кэш-памяти).
В машинах UMА каждый процессор имеет одно и то же время доступа к любому модулю памяти. Иными словами, каждое слово памяти можно считать с той же скоростью, что и любое другое слово памяти. Если это технически невозможно, самые быстрые обращения замедляются, чтобы соответствовать самым медленным, поэтому программисты не увидят никакой разницы. Это и значит «однородный». Такая однородность делает производительность предсказуемой, а этот фактор очень важен для написания эффективной программы.
Мультипроцессор NUMA, напротив, не обладает этим свойством. Обычно есть такой модуль памяти, который расположен близко к каждому процессору, и доступ к этому модулю памяти происходит гораздо быстрее, чем к другим. С точки зрения производительности очень важно, куда помещаются программа и данные. Машины СОМА тоже с неоднородным доступом, но по другой причине.
Во вторую подкатегорию машин MIMD попадают мультикомпьютеры, которые в отличие от мультипроцессоров не имеют памяти совместного использования на архитектурном уровне. Другими словами, операционная система в процессоре мультикомпьютера не может получить доступ к памяти, относящейся к другому процессору, просто путем выполнения команды LOAD. Ему приходится отправлять сообщение и ждать ответа. Именно способность операционной системы считывать слово из отдаленного модуля памяти с помощью команды LOAD отличает мультипроцессоры от мультикомпьютеров. Как мы уже говорили, даже в мультикомпьютере пользовательские программы могут обращаться к другим модулям памяти с помощью команд LOAD и STORE, но эту иллюзию создает операционная система, а не аппаратное обеспечение. Разница незначительна, но очень важна. Так как мультикомпьютеры не имеют прямого доступа к отдаленным модулям памяти, они иногда называются машинами NORMA (NO Remote Memory Access — без доступа к отдаленным модулям памяти).
Мультикомпьютеры можно разделить на две категории. Первая категория содержит процессоры МРР (Massively Parallel Processors — процессоры с массовым параллелизмом)— дорогостоящие суперкомпьютеры, которые состоят из большого количества процессоров, связанных высокоскоростной коммуникационной сетью. В качестве примеров можно назвать Cray T3E и IBM SP/2.
Вторая категория мультикомпьютеров включает рабочие станции, которые связываются с помощью уже имеющейся технологии соединения. Эти примитивные машины называются NOW (Network of Workstations — сеть рабочих станций)и COW (Cluster of Workstattions — кластер рабочих станций).
6. Многомашинные ВС. Реализация на основе ЕС ЭВМ. Кластерные ВС.
R Многомашинные ВС используются для повышения производительности, надежности и достоверности вычислений. Исторически они появились перед многопроцессорными.
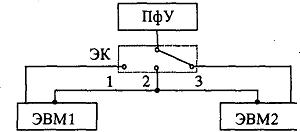
Положения 1 и 3 электронного ключа (ЭК) обеспечивали режим повышенной надежности. При этом одна из машин выполняла вычисления, а другая находилась в «горячем» или «холодном» резерве, т.е. в готовности заменить основную ЭВМ. Положение 2 электронного ключа соответствовало случаю, когда обе машины обеспечивали параллельный режим вычислений. Здесь возможны две ситуации:
а) обе машины решают одну и ту же задачу и периодически сверяют результаты решения. Тем самым обеспечивался режим повышенной достоверности, уменьшалась вероятность появления ошибок в результатах вычислений. Примерно по такой же схеме построены управляющие бортовые вычислительные комплексы космических аппаратов, ракет, кораблей. Например, американская космическая система «Шатл» содержала пять вычислительных машин, работающих по такой схеме;
б) обе машины работают параллельно, но обрабатывают собственные потоки заданий. Возможность обмена информацией между машинами сохраняется. Этот вид работы относится к режиму повышенной производительности. Она широко используется в практике организации работ на крупных вычислительных центрах, оснащенных несколькими ЭВМ высокой производительности.
R Единая система ЭВМ представляет собой семейство программно-совместимых вычислительных машин, предназначенных для решения широкого класса научно-технических, экономических, управленческих и других задач. Разработка начата в 1969 г., а серийное производство ведется с 1971 г.
В рамках ЕС ЭВМ создавались двухмашинные и двухпроцессорные комплексы, которые позволяют повысить производительность и надежность и вместе с тем отличаются относительной простотой, как технической реализации, так и программного обеспечения. Это вовсе не означает, что имеющиеся средства не позволяют создавать, скажем, трех- или четырехмашинные и трех- или четырехпроцессорные комплексы. Дело в том, что такие комплексы будут существенно сложнее и их технико-экономическая эффективность может оказаться недостаточно высокой.
R Кластер — группа компьютеров, объединённых высокоскоростными каналами связи и представляющая с точки зрения пользователя единый аппаратный ресурс.
Один из первых архитекторов кластерной технологии Грегори Пфистер (Gregory F. Pfister) дал кластеру следующее определение: «Кластер — это разновидность параллельной или распределенной системы, которая:
· состоит из нескольких связанных между собой компьютеров;
· используется как единый, унифицированный компьютерный ресурс».
Иными словами, кластер компьютеров представляет собой несколько объединенных компьютеров, управляемых и используемых как единое целое. Они называются узлами и могут быть одно- или мультипроцессорными. В классической схеме при работе с приложениями все узлы разделяют внешнюю память на массиве жестких дисков, используя внутренние дисковые накопители для специальных функций (например, системных).
Обычно различают следующие основные виды кластеров:
- отказоустойчивые кластеры (High-availability clusters, HA)
- кластеры с балансировкой нагрузки (Load balancing clusters)
- высокопроизводительные кластеры (High-performance clusters, HPC)
- grid-системы