Основные этапы решения задач с помощью ИНС
При построении модели ИНС прежде всего необходимо точно определить задачи, которые будут решаться с ее помощью. Из исходной информации необходимо исключить все сведения, не относящиеся к исследуемой проблеме. В то же время следует располагать достаточным количеством примеров для обучения ИНС. Все примеры желательно разбить на два множества: обучающее – на котором подбираются значения весов, и валидационное – на котором оцениваются предсказательные способности сети. Должно быть еще и третье – тестовое множество, которое вообще не влияет на обучение и используется лишь для оценки предсказательных возможностей уже обученной сети.
На практике оказывается, что для хорошего обобщения достаточно, чтобы размер обучающего множества N удовлетворял следующему соотношению:
N = O(W/ε),
где W – общее количество свободных параметров (т.е. синаптических весов и порогов) сети; ε – допустимая точность ошибки классификации; О() – порядок заключенной в скобки величины. Например, для ошибки в 10% количество примеров обучения должно в 10 раз превосходить количество свободных параметров сети.
1. Кодирование входов и выходов.
ИНС представляет собой распределённый числовой процессор, поэтому для представления нечисловых данных нужен числовой код. Например, буквы в словах можно кодировать в соответствии с одной из общепринятых таблиц кодировки или задать собственную таблицу.
Можно выделить два основных типа нечисловых переменных: упорядоченные (называемые также ординальными – от англ. order – порядок) и категориальные. В обоих случаях переменная относится к одному из дискретного набора классов (c1, c2, … , cn). Но в первом случае эти классы упорядочены – их можно ранжировать, тогда как во втором такая упорядоченность отсутствует. В качестве примера упорядоченных переменных можно привести сравнительные категории: плохо - хорошо - отлично, или медленно - быстро. Категориальные переменные просто обозначают один из классов, являются именами категорий. Например, это могут быть имена людей.
2. Нормировка данных.
Эффективность нейросетевой модели повышается, если диапазоны изменения входных и выходных величин приведены к некоторому стандарту, например [0,1] или [-1,1]. Кроме этого, нормированные величины безразмерны.
Приведение данных к единичному масштабу обеспечивается нормировкой каждой переменной на диапазон разброса ее значений. В простейшем варианте это - линейное преобразование:
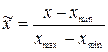
Такая нормировка оптимальна при распределении величины, близком к равномерному. При наличии редких выбросов необходима нормировка на основе статистических характеристик данных:
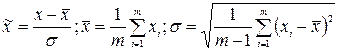
Однако, теперь нормированные величины не принадлежат гарантированно единичному интервалу, более того, максимальный разброс значений заранее не известен. Для входных данных это может быть и не важно, но если выходные нейроны – сигмоидные, они могут принимать значения лишь в единичном диапазоне. Выход из этой ситуации – использовать для предобработки данных функцию активации тех же нейронов:

3. Удаление избыточности.
Для проблем со множеством факторов часто наблюдается избыточность данных: можно описать данные меньшим количеством признаков, сохранив при этом большую часть информации. Здесь чаще всего используются анализ главных компонентов и корреляционный анализ. Первый способ заключается в том, что исключаются признаки с небольшой дисперсией, второй – в выявлении пар сильно связанных признаков и удалении одного из них.
4. Конструирование нейросетей с различными параметрами.
Решение этой проблемы во многом определяется опытом исследователя. Число входных и выходных элементов сети с прямой связью и обратным распространением ошибок обычно диктуется рассматриваемой проблемой – числом входных признаков и числом известных классов. Размеры скрытого слоя обычно находятся экспериментально. Обычно начинают с одного скрытого слоя, который содержит 30-50% числа входных элементов. В случае нескольких скрытых слоёв, рекомендуется в каждом последующем слое использовать в два раза меньше нейронов, чем в предыдущем.
5. Отбор оптимальных сетей.
Критерий оптимальности также определяется рассматриваемой проблемой. В качестве такого может быть принят минимум ошибок при классификации, максимальная скорость реакции и т.п.
6. Оценка значимости предсказаний.
Проводится тестирование полученной модели ИНС на тестовой примеров. Если сеть не может обобщать свои возможности на неизвестные ей данные, то она не представляет практической ценности. В статистике известна зависимость между ожидаемой ошибкой на обучающей и тестовой выборках для линейных моделей при среднеквадратическом определении ошибки:

Здесь P – число свободных параметров модели. В случае нейронных сетей число свободных параметров определяется архитектурой: числом слоев, количеством нейронов сети и набором весов связей между нейронами сети. Предполагается, что данные выборки зашумлены независимым стационарным шумом с нулевым средним и дисперсией σ2. Это условие может быть применено к нелинейным моделям, если считать их локально-линейными в окрестности каждой точки. На основе этого предположения строится ряд асимптотических оценок обобщающей способности сети:
– критерий Акаика:  ;
;
– байесовский критерий:  ;
;
– финальная ошибка предсказания  ;
;
– обобщённая кросс-валидация:  и др.
и др.