Предварительный анализ многомерных данных. Диаграмма рассеивания
Наиболее распространенными задачами прикладной статистики являются задачи определения и описания зависимости между признаками. На этапе предварительного анализа таблицы многомерных данных исследуется степень линейной зависимости признаков, которая оценивается с помощью парных коэффициентов ковариации и парных коэффициентов корреляции. Коэффициент ковариации между двумя признаками  и
и  рассчитывается по формуле:
рассчитывается по формуле:
 (3.11)
(3.11)
Коэффициент корреляции определяется через коэффициент ковариации по формуле:
 (3.12)
(3.12)
Коэффициент корреляции обладает следующими свойствами:
1. Если между случайными признаками и существует положительная линейная связь, то  , если связь отрицательная, то
, если связь отрицательная, то  (рис. 3.18 - а,б).
(рис. 3.18 - а,б).
2. Коэффициент корреляции является безразмерной величиной.
3. 
4. Чем ближе  по модулю к 1, тем сильнее линейная связь между случайными признаками и .
по модулю к 1, тем сильнее линейная связь между случайными признаками и .
5. Если  , то линейная связь отсутствует. Близость к нулю коэффициента корреляции говорит об отсутствии линейной связи между признаками, но не исключает иные виды связи и зависимости (рис. 3.18 - в).
, то линейная связь отсутствует. Близость к нулю коэффициента корреляции говорит об отсутствии линейной связи между признаками, но не исключает иные виды связи и зависимости (рис. 3.18 - в).

Рис. 3.18. Варианты связи между случайными признаками  и
и
Приведем пример расчета коэффициентов ковариации и корреляции в таблице EXCEL. Рассчитаем эти коэффициенты для двух пар признаков ( -
-  ) и (
) и ( -
-  ). Расчеты приведены на рис. 3.19 и рис. 3.20.
). Расчеты приведены на рис. 3.19 и рис. 3.20.

Рис. 3.19. Табличный расчет коэффициентов ковариации и корреляции
пар признаков (- ) и (- ).

Рис. 3.20. Результаты расчета коэффициентов ковариации и корреляции
пар признаков (- ) и (- ).
Расчет коэффициента ковариации между двумя признаками в EXCEL можно выполнить и с помощью функции КОВАР (рис. 3.20 -3.21).

Рис. 3.21. Диалоговое окно функции КОВАР
Обычно парные коэффициенты таблицы данных со многими признаками сводятся в матрицы, которые называются соответственно ковариационной и корреляционной матрицей. Расчет ковариационной и корреляционной матриц производится с помощью программ, включенных в настраиваемый пакет “Анализ данных” (рис. 3.22). Интерфейс программ Ковариация и Корреляция приведены на рис. 3.23 и 3.25. Результаты расчета ковариационной и корреляционной матриц по данным таблицы данных приведены на рис. 3.24 и 3.26.

Рис. 3.22. Список программ пакета “Анализ данных”

Рис. 3.23. Диалоговое окно программы Ковариация

Рис. 3.24. Результаты расчета ковариационной матрицы

Рис. 3.25. Диалоговое окно программы Корреляция

Рис. 3.26. Результаты расчета корреляционной матрицы
На этапе предварительного анализа очень полезно построить точечные графики совместного распределения пар признаков. В точечной диаграмме каждой паре значений двух признаков ставится в соответствие отдельная точка. Значения признаков определяют координаты точек на плоскости координат двух признаков. Такие графики называются диаграммами рассеивания. Диаграммы рассеивания дают почву для выработки статистических гипотез. В EXCEL диаграммы рассеивания строится с помощью диаграммы Точечная (Мастер диаграмм) (рис. 3.27). Рассмотрим примеры диаграмм рассеивания для некоторых пар признаков таблицы данных. Диаграмма рассеивания признаков  и
и  приведена на рис. 3.28. Признаки и имеют равномерное распределения. Точки на диаграмме равномерно покрывают квадрат со сторонами равными единице.
приведена на рис. 3.28. Признаки и имеют равномерное распределения. Точки на диаграмме равномерно покрывают квадрат со сторонами равными единице.

Рис. 3.27. Мастер диаграмм (Точечная)

Рис. 3.28. Диаграмма рассеивания признаков и
Диаграмма рассеивания признаков  и приведена на рис. 3.29. Признаки и имеют стандартное нормальное распределения. Коэффициент корреляции этой пары признаков
и приведена на рис. 3.29. Признаки и имеют стандартное нормальное распределения. Коэффициент корреляции этой пары признаков  , то есть очень близок к нулю. Признаки линейно независимы. Диаграмма такой пары признаков имеет форму круга. Плотность точек понижается при удалении от центра круга с координатами (0;0).
, то есть очень близок к нулю. Признаки линейно независимы. Диаграмма такой пары признаков имеет форму круга. Плотность точек понижается при удалении от центра круга с координатами (0;0).
Диаграмма рассеивания признаков и приведена на рис. 3.30. Признак имеет равномерное распределении на интервале (0,1). Признак имеет нормальное распределение с параметрами 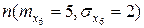 . Однако, эти признаки имеют достаточно высокий коэффициент корреляции
. Однако, эти признаки имеют достаточно высокий коэффициент корреляции  . Связь имеет отрицательный характер. Связь между признаками объясняется тем, что значения признака были получены путем преобразования значений признака .
. Связь имеет отрицательный характер. Связь между признаками объясняется тем, что значения признака были получены путем преобразования значений признака .

Рис. 3.29. Диаграмма рассеивания признаков и

Рис. 3.30. Диаграмма рассеивания признаков и
Рассмотрим еще один важный вид диаграмм рассеивания. Это диаграммы рассеивания классифицированных данных (рис. 3.32). Примерами таких данных могут быть антропологические данные двух рас или данные двух выборок, полученных при разных условиях. Известны несколько форм представления классифицированных данных. Первая форма это расположение данных классов в одних и тех же столбцах. Классы данных располагаются один под другим. При этом в таблице данных должен быть столбец, содержащий номера классов. Второй способ – расположение классов в различных столбцах таблицы. Применяется реже., потому что количество наблюдений в классах должно совпадать. Рассмотрим таблицу данных, сформированную путем моделирования. Будем считать, что признаки и представляют собой выборку из первого класса, признаки и выборку из второго класса. При этом количество наблюдений в обоих классах одинаково и равно 100 (вторая форма представления данных). Для построения диаграммы рассеивания воспользуемся все той же точечной диаграммой ECSEL. Только теперь будем вводить два ряда данных (рис. 3.31).

Рис. 3.31 Определение параметров для классифицированных данных
Диапазоны значений признаков по классам определяются как ряды данных и определяются отдельно по каждому классу. Рядов (классов) может быть множество. Добавление рядов осуществляются нажатием кнопки ”Добавить”.
Из рис. 3.32 можно видеть, что классы данных хорошо различимы. При этом второй класс гораздо более размытый.

Рис. 3.32. Диаграмма рассеивания классифицированных данных