АДАПТИВНЫЙ БАЙЕСОВ ПОДХОД ПРИ ПАРАМЕТРИЧЕСКОЙ АПРИОРНОЙ НЕОПРЕДЕЛЕННОСТИ
Конкретные приложения рассматриваемых здесь методов в последующих главах будут применены в основном к задачам синтеза информационных систем в условиях параметрической априорной неопределенности, простейшим примером которых является первый из примеров § 6.1. Поэтому рассмотрим этот случай наиболее детально с доведением результатов до максимально возможной в условиях общей постановки задач степени конкретности.
При параметрической априорной неопределенности (гл. 3) функция правдоподобия Р (х|l,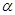 l) задается с точностью до совокупности неизвестных параметров l = {l(1),..., l(l)}, а плотность априорного распределения вероятности р(l|b) для l с точностью до совокупности неизвестных параметров b = {b(1),..., b(m)}, причем пространства Аl и В - некоторые заданные подмножества евклидова пространства соответствующей размерности. Обозначим полную совокупность неизвестных параметров, включающую в себя все частные совокупности l и совокупность b, через g, тогда совместная плотность вероятности х и l, может быть записана в виде
l) задается с точностью до совокупности неизвестных параметров l = {l(1),..., l(l)}, а плотность априорного распределения вероятности р(l|b) для l с точностью до совокупности неизвестных параметров b = {b(1),..., b(m)}, причем пространства Аl и В - некоторые заданные подмножества евклидова пространства соответствующей размерности. Обозначим полную совокупность неизвестных параметров, включающую в себя все частные совокупности l и совокупность b, через g, тогда совместная плотность вероятности х и l, может быть записана в виде
 (6.2.1)
(6.2.1)
где р(x,l|g) - известная функция всех своих аргументов, удовлетворяющая обычным требованиям к плотности совместного распределения вероятности. Апостериорное распределение вероятности и апостериорный риск определяются обычными соотношениями
 (6.2.2)
(6.2.2)
 (6.2.3)
(6.2.3)
и в общем случае зависят от совокупности неизвестных параметров g. В частном случае, когда апостериорное распределение либо только значение u0 = u0(х, g). Для которого достигается минимум апостериорного риска, то есть удовлетворяется уравнение
 (6.2.4)
(6.2.4)
не зависит от g, априорная неопределенность не является существенной, а правило решения u0(х,g)=u0(х) является равномерно наилучшим правилом решения. Поэтому в любой конкретной задаче с априорной неопределенностью прежде всего следует проверить, решив уравнение (6.2.4), существует либо нет равномерно наилучшее решение.
Если априорная неопределенность является существенной, то решение уравнения (6.2.4) зависит от g и представляет собой функцию u0(х,g), описывающую оптимальное байесово правило решения для известного значения g (при отсутствии априорной неопределенности).
Поскольку истинное значение g неизвестно, то ни величина апостериорного риска (6.2.3), ни правило решения u0(х,g) не определены и необходимо применить адаптивный байесов подход, введя новую меру ожидаемых потерь - какую-либо оценку апостериорного риска, не зависящую от неизвестного значения g, Естественной оценкой величины R(u,x,g), обеспечивающей полное сохранение последующего байесова формализма, является
 (6.2.5)
(6.2.5)
где  = (x) - некоторая оценка значения g, найденная по данным наблюдения х. При подстановке (6.2.5) вместо неизвестного значения R(u,x,g), уравнение (6.2.4), которое определяет правило решения, обеспечивающее минимум ожидаемых потерь при каждом значении х, получим правило решения
= (x) - некоторая оценка значения g, найденная по данным наблюдения х. При подстановке (6.2.5) вместо неизвестного значения R(u,x,g), уравнение (6.2.4), которое определяет правило решения, обеспечивающее минимум ожидаемых потерь при каждом значении х, получим правило решения
 (6.2.6)
(6.2.6)
отличающееся от оптимального байесова правила только заменой g оценочным значением = (x).
Таким образом, использование оценки апостериорного риска (6.2.5) позволяет не решать заново задачу минимизации ожидаемых потерь; структура правила решения остается такой же, как при отсутствии априорной неопределенности (известном значении g), а неопределенность правила решения устраняется заменой неизвестного значения g оценочным значением .
Адаптивное байесово правило решения (6.2.6) внешне выглядит очень привлекательным: оно универсально, обладает хорошими конструктивными качествами, так как позволяет просто взять готовое решение байесовой задачи и заменить в нем g на , и на примерах § 6.1 показало свою высокую эффективность. Однако прежде чем рекомендовать его широкое использование, необходимо, разумеется, выяснить два вопроса:
1)какую именно оценку = (x) следует использовать в (6.2.5), (6.2.6);
2)удовлетворяет ли правило решения (6.2.6) какому-либо из рассмотренных в гл.4 принципов оптимальности или хотя бы является близким к наилучшему с точки зрения того или иного принципа предпочтения правилу.
Если объем имеющихся данных наблюдения таков, что можно оценить значение g с высокой точностью, то ответ на первый из этих вопросов некритичен. В качестве (x) можно использовать любую оценку с малым отклонением от истинного значения g, что автоматически приводит к малому отклонению риска правила решения (6.2.6) от риска абсолютно оптимального байесова правила решения при известном значении g. Детальный вид оценки (х) определяется в этом случае в основном соображениями, связанными с простотой реализации алгоритма оценивания вектора g. Практически такая свобода действий допустима в асимптотическом случае, когда совокупность имеющихся данных наблюдения описывается вектором х = {х1,..., хn} с большим числом компонент хn, каждая из которых зависит от g.
При ограниченном объеме данных наблюдения выбор оценки (x) подставляемой в правило решения (6.2.6), следует производить более аккуратно, так, чтобы выполнить основное требование обеспечения наименьшего из возможных отклонений риска правила решения (6.2.6) от риска байесова правила решения с известным значением g. С целью детализации критерия выбора наилучшей оценки (x) рассмотрим величину среднего риска для правила решения (6.2.6) при каком-либо значении у
 (6.2.7)
(6.2.7)
и сравним ее с величиной среднего риска для оптимального байесова решения u0(x,l) при том же значении g.
 . (6.2.8)
. (6.2.8)
Для этого составим разность
 (6.2.9)
(6.2.9)
где
 (6.2.10)
(6.2.10)
Очевидно, что разность R(,g) неотрицательна. Это следует из того, что при любом g правило решения u0(x,l) минимизирует величину среднего риска. Более того, функция  (,g,х) из (6.2.10) также неотрицательна, поскольку при любых значениях х и g она представляет собой разность значений апостериорного риска для двух решений u1 = u0(x, ) и u2 = u0(x, g), а именно второе решение соответствует минимальному значению апостериорного риска.
(,g,х) из (6.2.10) также неотрицательна, поскольку при любых значениях х и g она представляет собой разность значений апостериорного риска для двух решений u1 = u0(x, ) и u2 = u0(x, g), а именно второе решение соответствует минимальному значению апостериорного риска.
При этом R(,g) и (,g,х) обладают следующим свойством:
 (6.2.11)
(6.2.11)
Величина DR(, g) является функционалом оценки = (x), который, вообще говоря, может принимать различные значения при разных g. Попытаемся выбрать оценку g(х) так, чтобы обеспечить равномерно наилучшее приближение среднего риска правила решения u(x) = u0(x, g) к минимальному байесову риску правила решения u0(х, g) с известным значением g. Как известно, требование равномерно наилучшего приближения означает, что максимальное отклонение должно быть минимальным, поэтому наилучшую оценку g(x) = g0(x) следует выбирать, исходя из условия
 (6.2.12)
(6.2.12)
Таким образом, с учетом (6.2.9) наилучшая оценка 0(x) является минимаксной оценкой параметра  плотности распределения вероятности
плотности распределения вероятности
 (6.2.13)
(6.2.13)
относительно функции потерь (, g, х) из (6.2.10). В гл. 5 мы показали, что при некоторых ограничениях на функцию потерь (5.2.1) и распределение вероятности данных наблюдения (5.2.2) минимаксной оценкой является оценка максимального правдоподобия, то есть наилучшая оценка 0(x) совпадает с оценкой максимального правдоподобия
 (6.2.14)
(6.2.14)
которая определяется из уравнения правдоподобия
 (6.2.15)
(6.2.15)
или при отсутствии ограничений на область Г ={Аl, В} значений g из эквивалентного ему уравнения
 (6.2.16)
(6.2.16)
где
 (6.2.17)
(6.2.17)
- оператор градиента, ставящий в соответствие любой функции от g вектор-столбец частных производных этой функции по всем компонентам вектора g.
При использовании оценки максимального правдоподобия g* = g*(x), определяемой уравнениями (6.2.15), (6.2.16), адаптивное байесово правило решения (6.2.6) принимает вид
 , (6.2.18)
, (6.2.18)
и мы получаем замкнутую конструктивную процедуру нахождения правила решения в условиях априорной неопределенности, которое содержит следующие элементы:
- отыскание оптимального байесова правила решения uo(x, g) для фиксированного значения g путем минимизации апостериорного риска R(u, x, g) из (6.2.3) (во многих случаях это означает просто взять готовое решение соответствующей задачи при отсутствии априорной неопределенности);
- нахождение оценки максимального правдоподобия g* = g*(x) путем решения уравнений правдоподобия (6.2.15) или (6.2.16);
- замена в оптимальном байесовом правиле решения u0(x, g) неизвестного значения g на его оценочное значение g* = g*(x).
При слабых ограничениях на функцию потерь (, g, х), при которых оценка максимального правдоподобия g* является минимаксной оценкой, эта процедура обеспечивает получение правила решения u(х) (6.2.18), которое дает равномерно наилучшее приближение к среднему риску абсолютно оптимального байесова правила решения с известным значением g.
Указанные ограничения обычно выполняются, если множество значений  непрерывно, а также в ряде других случаев. Мы не будем заниматься специально детальным анализом условий совпадения оценки максимального правдоподобия g*(х) с минимаксной оценкой go(x) определяемой из (6.2.12). Конечно, могут быть ситуации, когда y0(х) лучше, чем g*(x), в смысле точности приближения среднего риска правила решения u0(x, g0(х)) к среднему риску байесова правила u0(x, g), и, взяв действительно минимаксную оценку, можно было бы получить лучшие результаты, чем с оценкой максимального правдоподобия. Примером подобного рода является случай, когда значение g задает априорное распределение на дискретном множестве значений l, а данные наблюдения х относятся только к одному из возможных значений l. В этом и некоторых подобных случаях оптимальное значение g0(х) получается константой, не зависящей от х, что довольно очевидно заранее и существенно упрощает нахождение правила решения. Однако такие ситуации сравнительно редки, а сама оценка при условии единственности решения уравнения максимального правдоподобия, как уже неоднократно отмечалось, обладает следующими качествами: она обязательно совпадает с эффективной (имеющей наименьшее возможное рассеяние) оценкой, если последняя существует; с ростом объема данных наблюдения, по которым вычисляется оценка максимального правдоподобия, она сходится к истинному значению оцениваемого параметра и при этом является асимптотически нормальной и асимптотически эффективной. Имея в виду эти высокие достоинства, а также универсальность и относительную простоту метода максимального правдоподобия, благодаря которым могут быть разработаны стандартные процедуры нахождения оценки g*, можно в общем случае ограничиться оценками максимального правдоподобия, оставив попытки их улучшения для конкретных задач, где такая возможность имеется.
непрерывно, а также в ряде других случаев. Мы не будем заниматься специально детальным анализом условий совпадения оценки максимального правдоподобия g*(х) с минимаксной оценкой go(x) определяемой из (6.2.12). Конечно, могут быть ситуации, когда y0(х) лучше, чем g*(x), в смысле точности приближения среднего риска правила решения u0(x, g0(х)) к среднему риску байесова правила u0(x, g), и, взяв действительно минимаксную оценку, можно было бы получить лучшие результаты, чем с оценкой максимального правдоподобия. Примером подобного рода является случай, когда значение g задает априорное распределение на дискретном множестве значений l, а данные наблюдения х относятся только к одному из возможных значений l. В этом и некоторых подобных случаях оптимальное значение g0(х) получается константой, не зависящей от х, что довольно очевидно заранее и существенно упрощает нахождение правила решения. Однако такие ситуации сравнительно редки, а сама оценка при условии единственности решения уравнения максимального правдоподобия, как уже неоднократно отмечалось, обладает следующими качествами: она обязательно совпадает с эффективной (имеющей наименьшее возможное рассеяние) оценкой, если последняя существует; с ростом объема данных наблюдения, по которым вычисляется оценка максимального правдоподобия, она сходится к истинному значению оцениваемого параметра и при этом является асимптотически нормальной и асимптотически эффективной. Имея в виду эти высокие достоинства, а также универсальность и относительную простоту метода максимального правдоподобия, благодаря которым могут быть разработаны стандартные процедуры нахождения оценки g*, можно в общем случае ограничиться оценками максимального правдоподобия, оставив попытки их улучшения для конкретных задач, где такая возможность имеется.