Определение переменных и ввод данных в программу SPSS.
Как уже было отмечено выше, прежде чем непосредственно приступать к анализу данных в программе SPSS, необходимо определенным образом сформировать базу для работы. Поскольку работа ведется преимущественно с количественными данными, а основной инструментарий количественных исследований в социологии – анкетный опрос, то в данной работе мы будем рассматривать пример организации данных в программе SPSS на основе социологической анкеты.
Первым шагом организации вода данных в программу SPSS является кодирование самой анкеты. Важность этого этапа не стоит недооценивать, так как пренебрежение данным этапом зачастую приводит к ошибкам, определенных нами выше как пользовательские. Чаще всего последствия таких ошибок – недостаточность (пропуск) или, напротив, - избыточность (ввод одной анкеты по 2 и более раза) данных, что может оказать довольно существенное влияние на результат обработки данных. Кодирование анкеты предполагает наличие двух процедур:
- Нумерация анкет по порядку – процедура, позволяющая вести контроль за количеством анкет и устранить как избыточность, так и недостаток данных.
- Нумерация (кодирование) самих вопросов анкеты – процедура позволяющая организовать вопросы анкеты и привести их в соответствие с требованиями программы. Рассмотрим этот шаг подробнее.
Когда исследователь разрабатывает анкету, он уже должен держать в голове возможности ее обработки в соответствующей программе. Однако, как уже было отмечено выше, с точки зрения мотивации респондента и правил драматургии анкеты как инструментария, не всегда вопросы организованы в наиболее удобном для обработки виде. По этой причине нумерация и кодировка вопросов для ввода в программу SPSS должна быть проведена заранее. Это во многом облегчает опрераторскую работу как по определению переменных в самой программе, так и по непосредственному вводу данных. Когда речь заходит о достаточно большом объеме данных – этот фактор приобретает особенное значение, т.к. позволяет сократить время на ввод данных.
Рассмотрим конкретный пример. Пусть у нас есть анкета, фрагмент которой выглядит следующим образом:

Рис.8. Фрагмент анкеты.
Перед нами 4 вопроса анкеты, которые в принципе уже пронумерованы. Однако нумерация вопросов анкеты в виде, предлагаемом респонденту, отличается от нумерации, используемой для ввода данных в программу. Ключевое отличие заключается в том, что респонденту предлагаются вопросы, а исследователь на этапе обработки данных имеет дело с переменными, которые принимают случайные значения. При организации подготовки данных анкеты для ввода в программу SPSS необходимо пронумеровать именно переменные, которые в дальнейшем будут подвергаться обработке, а также пронумеровать варианты ответов, так как варианты – это конкретные возможные значения, которые может принимать переменная. Та же самая анкета при нумерации переменных для ввода в SPSS будет иметь следующий вид.
 |
Рис.9. Анкета, пронумерованная для ввода данных в программу SPSS.
В круглых скобках представлена нумерация переменных, а в фигурных скобках - нумерация значений, которая может принимать та или иная переменная. Поясним некоторые моменты, которые могут вызвать недопонимание.
Первое – в анкете мы видели 4 вопроса, однако при нумерации переменных у нас получилось 7 переменных. Дело в том, что четвертый вопрос анкеты представляет собой фактически объединение трех переменных (отношение к Президенту, отношение к Правительству и отношение к Парламенту), каждая из которых может принимать случайные значения. По этой причине мы не имеем права объединять эту переменную в одну. Кроме того, выше мы отмечали, что необходимо пронумеровать сами анкеты. По этой причине вопросы начинают нумероваться с цифры 2. Первая переменная – это порядковый номер анкеты.
Второе – отсутствует нумерация ответов по второму вопросу. В данном случае мы имеем дело с метрической шкалой и предлагаем респонденту числовую оценку своего возраста. Следовательно, мы не можем точно описывать все множество ответов респондентов.
Наконец, третье – обратите внимание на нумерацию значений по третьей переменной и по переменным 4-6. К сожалению, многие исследователи игнорируют эту особенность, которая может повлиять на результаты обработки данных. Переменные с третьей по шестую представлены порядковой (ранговой) шкалой. Соответственно – значения, которые могут принимать эти переменные упорядочены, т.е. ранжированы и имеют относительно друг друга некоторый ранг. Общий принцип ввода данных в программу SPSS должен быть основан на правиле: ранговые шкалы вводятся (нумеруются) в порядке возрастания, т.е. большее значение соответствует большему рангу, меньшее – меньшему, т.к. нумерация в данном случае представляет именно ранг.[9]
В рассматриваемом нами примере в третьей переменной возможные значения идут от минимального к максимальному (среднее образование – низшая ступень, ученая степень – высшая). По этой причине в данном случае можно нумерацию вариантов ответов оставить в таком же виде: первый вариант – наименьший ранг (1), последний – наибольший (5). А вот переменные с 4 по 6 напротив представлены в обратном порядке – от максимального к минимальному[10], поэтому и нумерация идет обратная.
После того, как анкета была закодирована, можно приступать к процедуре определения переменных в программе SPSS. Рассмотрим эту процедуру подробнее.
Определение переменных в программе SPSS происходит в поле Variable View. Для того чтобы переменная была введена в программу нужно заполнить все поля, определив ключевые характеристики переменной. Возьмем вышеобозначенный пример. Первая переменная, как мы договорились, - это номер анкеты.
В поле Variable View в первой строке в столбце Nameвведите название (имя) переменной –number[11].
Если на этом этапе завершить процедуру определения переменной, то все остальные поля определяться автоматически на основе тех параметров, которые заложены в программу по умолчанию. Иногда можно воспользоваться таким упрощенным способом, однако, на практике далеко не всегда стоит его использовать, так как не всегда программа предлагает именно те параметры, которые соответствуют переменной. Например – по умолчанию в SPSS устанавливается метрическая шкала переменной, что для большинства вопросов не справедливо. Кроме того – для удобства пользования и работы с массивами данных очень важно определить метку переменной Label,которая в дальнейшем будет использоваться для обозначения переменной в отчетах и таблицах. По этой причине продолжим последовательно определять характеристики переменной number.[12]
В поле определения типа переменной (Type) нужно выбрать значение numeric – число. Этот тип является основным и в социологических исследованиях используется преимущественно только он или же (редко) string – строковая переменная, способная принимать буквенное значение. Строковая переменная используется для открытых вопросов. Однако, как уже было отмечено выше, такого рода информация в программе не обрабатывается статистическим инструментарием и по этой причине ее лучше не использовать либо попытаться перевести в числовую форму. В программе SPSS по умолчанию стоит тип переменной numeric, поэтому в дальнейшем для ускорения процедуры определения переменной можно просто пропускать характеристику Type.
Аналогично можно пропустить значения параметров width и decimals, которые, как уже было отмечено выше влияют преимущественно на удобство вывода информации. Первая переменная определяет разрядность и по умолчанию стоит цифра 8. Для нумерации анкет этого – более чем достаточно, так как в реальной практике очень редко бывают выборки даже с объемом в 10 000 человек (5 разрядов). Вместе с тем для прочих переменных (например, для дохода) – этого может оказаться недостаточно. Переменная decimals отвечает за количество десятичных знаков после запятой. Поскольку для нумерации мы используем целые числа, то можно здесь поставить 0.
Следующий параметр label – метка переменной, то имя, которое будет появляться в отчетах. В нашем случае это – «номер анкеты».
Поскольку мы имеем дело с переменной, которая имеет потенциально бесконечное число значений, то переменная values не заполняется и остается при значении по умолчанию – none (отсутствуют).
Следующий очень важный параметр для работы с переменными – это missing – фиксирование пропусков. Учет пропущенных значений чрезвычайно важен, так как в противном случае программа может давать некорректные данные, которые в дальнейшем приведут к неправильной интерпретации. Приведем пример. Пусть у нас опрошено 100 человек. При этом на какой-либо вопрос ответило только 80. Если мы не учитываем пропуски, то при подсчете частот процентный показатель будет браться от 100, а не от действительных 80 (5 человек будет при отсутствии пропусков составлять 5%, а при учете пропусков – 6,25%), что исказит истинную картину. Рассмотрим варианты учета пропусков в программе SPSS.

Рис.10. Определение пропусков значений в SPSS.
Для того чтобы вызвать подменю с установками типа пропуска значений, нужно щелкнуть мышью в ячейке столбца missing на символе  . Как видно из рисунка. Программа предлагает пользователю выбрать один из трех вариантов учета пропущенных значений:
. Как видно из рисунка. Программа предлагает пользователю выбрать один из трех вариантов учета пропущенных значений:
1. No missing values – значение, которое присутствует по умолчанию и в большинстве случаев подходит для учета пропусков. При активации этого варианта программа считает пропущенными значениями незаполненные ячейки.
2. Discrete missing values – дискретные (точные) пользовательские значения, которыми обозначаются пропуски. Программа позволяет задавать от 1 до 3-х значений, при вводе которых программа автоматически будет считать это как пропуск. Довольно часто исследователь при разработке анкеты указывает такие возможности в качестве варианта ответов. Чаще всего используется число 99.
3. Range plus one optional discrete missing value – возможность учета ранжированных значений, автоматически определяемых как пропуск + одно пользовательское дискретное значение. Довольно удобная опция, которая дополнительно позволяет исключить ошибочные вводы данных. Например при определении переменной возраста, если выборка состоит из людей в возрасте от 18 лет, можно установить в качестве пропусков нижнюю границу 18, верхнюю 100. В таком случае автоматически возраст респондентов менее 18 и более 100 лет считаются как пропуски.
В нашем случае для переменной, определяющей номер анкеты, можно смело оставлять параметр missing без изменений.
Следующие два параметра columns и align также можно оставить без изменений, так как они не влияют на расчеты, а показывают ширину столбца (которую в случае необходимости можно изменить так же, как и в Excel – простым растягиванием с помощью мыши в рабочем поле data view) и выравнивание в столбце (по правому краю – по умолчанию, по левому краю, и по центру).
Наконец, последний очень важный параметр – определение типа шкалы, по которой измеряется переменная – measure. В програмее присутствует возможность выбора из трех вариантов (см. рис.11)

Рис.11. Определение шкалы переменной.
Программа дополнительно в графическом виде предлагает подсказку (линейка для метрической шкалы (scale), гистограмма для ранговой (ordinal) и круги Эйлера для номинальной (nominal)). В нашем случае для определения номера анкеты следует выбрать номинальную.
После того, как мы задали параметры, можно говорить о том, что в программе была определена переменная number, обозначающая нумерацию анкет в исследовании.
Остальные переменные из нашего примера определяются в соответствии с такими же правилами и в таком же порядке. По этой причине остановимся только на специфических отличиях.
Переменная пол чаще всего определяется в параметре name как sex. В данном случае отличие будет заключаться в том, что переменная может принимать фиксированное число значений. По этой причине нужно определить ее значения.
В столбце values нужно щелкнуть мышью на символе . Раскроется дополнительное меню.
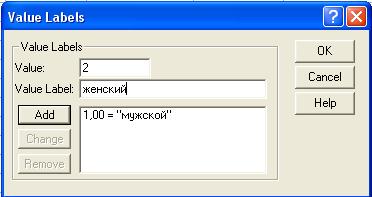
Рис.12 Определение значений переменной.
В окошке value нужно указать номер, значение переменной. Поскольку тип переменной был определен как числовой (numeric), то и значения – число. В окне value label требуется ввести значение переменной. В нашем примере мы закодировали числом 1 – мужской пол и числом 2 – женский. После определения значений нужно нажать кнопку add для того, чтобы значение добавилось. После определения значений переменных – нажимаем кнопку ОК.
Остальные параметры – аналогичны предыдущему примеру с определением нумерации анкет.
Следующая переменная – количество лет – практически полностью идентична первой (номер анкеты) за исключением того, что тип шкалы – scale. Четвертый вопрос (образование) аналогичен вопросу про пол, только изменяются значения переменной и тип шкалы ordinal.наконец последние вопросы, как уже было отмечено выше вводятся отдельно. Они полностью идентичны вопросу про образование. Для упрощения определения переменных можно использовать прием копирования. Например – вопросы относительно оценки деятельности Президента, Правительства и Парламента имеют одинаковые варианты ответа. Соответственно можно сделать следующее:
1. Определить первую переменную – оценка Президента.
2. Щелкнуть мышью в ячейке значений (values) и, щелкнув правой клавишей выбрать copy.
3. При определении остальных переменных в параметре values щелкнув правой клавишей мыши выбрать paste.
Если при определении переменных вдруг понадобиться дополнительно вставить еще одну переменную, то можно сделать это аналогично вставке строки в программе Excel: выделить мышью номер строки с переменной, перед которой нужно вставить дополнительную переменную и из списка выбрать insert variables.

Рис.13. Вставка дополнительной переменной в SPSS.
После того, как мы определили переменные, можно непосредственно перейти к процедуре ввода данных. Для этого нужно перейти в поле программы data view, которая будет иметь следующий вид.
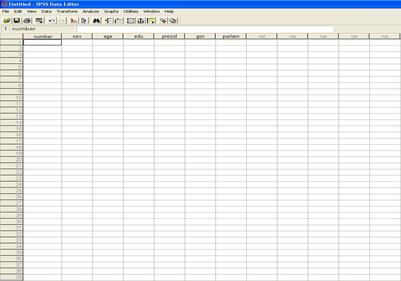
Рис. 14. Рабочее поле программы для ввода данных.
Как видно из рисунка, столбцы приняли обозначение в соответствии с тем, которые были определены в параметре name переменных. В дальнейшем ввод переменных осуществляется непосредственно в ячейки в виде цифр.
Например. Первая анкета принадлежит мужчине,30-летнего возраста, который имеет высшее образование, оценивший деятельность Президента как «положительно», Правительства как «скорее положительно» и Парламента как «скорее отрицательно». В таком случае нужно в первой строке в первой ячейке поставить цифру 1(номер анкеты), во второй ячейке – 1 (мужской пол), в третьей – 30 (возраст), в четвертой 4 (высшее образование), в пятой – 5 (положительная оценка Президента), в шестой – 4 (скорее положительная оценка Правительства) и в седьмой – 2 (скорее отрицательная оценка Парламента).
В программе SPSS в верхней части на панели управления есть кнопка  , которая осуществляет переключение между значениями переменной и метками переменной. Если нажать на нее, то в поле программы вместо значений появятся соответствующие метки. При активации данной функции ввод данных можно осуществлять на основе выбора из раскрывающегося списка. Однако при большом объеме выборки такой способ ввода данных более длителен и поэтому менее предпочитаем.
, которая осуществляет переключение между значениями переменной и метками переменной. Если нажать на нее, то в поле программы вместо значений появятся соответствующие метки. При активации данной функции ввод данных можно осуществлять на основе выбора из раскрывающегося списка. Однако при большом объеме выборки такой способ ввода данных более длителен и поэтому менее предпочитаем.
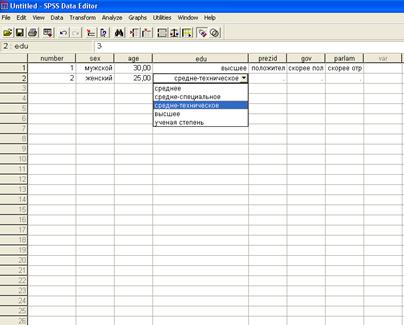
Рис.15. Ввод данных при активации функции показа значения переменных.
Аналогичным образом осуществляется ввод остальных данных. Важно помнить, что каждая строка – это отдельная анкета, а столбец – переменная. После ввода данных можно переходить к процедуре анализа. Однако, прежде чем непосредственно рассматривать анализ данных мы остановимся еще на одной особенности определения переменной со множественными ответами.