Глава 1. Алгоритмы поиска
Данная глава посвящена решению простой поисковой задачи: находить данные, хранящиеся в памяти компьютера с определённой идентификацией. Например, в вычислительной задаче найти f(x) по значению x и таблице значений функции f; в лингвистической – найти английский эквивалент данного русского слова.
Предположим, что в файле (таблице) хранится множество из N записей и необходимо определить положение соответствующей записи. Каждая запись содержит специальное поле, которое называется ключом, идентифицирующее данную запись. Все N ключей различны, так что каждый ключ однозначно определяет свою запись. Совокупность всех записей называется таблицей. В алгоритмах поиска присутствует так называемый аргумент поиска К, и задача заключается в отыскании записи, имеющей К своим ключом.
Существует две возможности окончания поиска: либо поиск оказался удачным, то есть позволил определить положение соответствующей записи, содержащей К; либо неудачным, то есть показал, что К не может быть найден ни в одной из записей. После неудачного поиска иногда желательно вставить в таблицу новую запись, содержащую К. Алгоритм, который делает это, называется поиском со вставкой.
1. Последовательный поиск
Последовательные поиск реализует следующую процедуру: начни с начала и продвигайся, пока не найдёшь нужный ключ; тогда остановись. Рассмотрим три алгоритма.
Алгоритм S (последовательный поиск).
Имеется таблица записей R1,R2,…,Rn (N≥1), снабжённых ключами K1,K2,…,Kn. Алгоритм предназначен для поиска записи с ключом К.
1. Установить начальное значение i=1;
2. Если Ki=K, то алгоритм завершён (идти на п. 5), запись Ri – искомая;
3. Перейти к следующей записи: i=i+1;
4. Если i≤N, то перейти на шаг 2, иначе – искомой записи в таблице нет;
5. Конец алгоритма.
Время работы алгоритма зависит от количества сравнений. Пусть обращение к записям происходит с равной вероятностью  . Тогда среднее число сравнений
. Тогда среднее число сравнений
 ; СКО числа сравнений ≈0,289N.
; СКО числа сравнений ≈0,289N.

Для ускорения работы алгоритма применяется алгоритм Q(быстрый последовательный поиск) – предполагается, что в конце стоит фиктивная запись RN+1.
1. Установка i=1, KN+1=K;
2. Если Ki=K, то перейти к п.4, иначе
3. Перейти к следующей записи: i=i+1 и вернуться к п.2;
4. Если i≤N, то поиск прошёл удачно, в противном случае – неудачно (i=N+1);
5. Конец.
Ускорение работы алгоритма до 30% по сравнению с алгоритмом S и достигается за счёт удаления одного сравнения из цикла.

Алгоритм Т(последовательный поиск в упорядоченной таблице).

Имеется таблица записей R1,R2,…,Rn,, причём ключи упорядочены по возрастанию: K1<K2<…<KN. Предполагается, что в конце таблицы расположена фиктивная запись RN+1, ключ которой KN+1>>К. Это позволяет избежать зацикливания при K> KN.
Если значение К с равной вероятностью принимает все возможные значения, то в случае удачного поиска алгоритм Т не лучше алгоритма Q. Однако отсутствие нужной записи алгоритм Т позволяет обнаружить примерно в два раза быстрее.
Приведенные выше алгоритмы предполагают отсутствие в таблице совпадающих значений ключей. В противном случае их необходимо модифицировать.
До сих пор предполагалось, что с равной вероятностью может потребоваться поиск любого аргумента, однако часто такое предположение неправомерно.
Пусть ключ Ki будет разыскиваться с вероятностью pi, причём p1+p2+…+pN=1. Время удачного поиска при больших N пропорционально числу сравнений С, среднее значение которого 
 будет минимальна при p1≥p2≥…≥pN, то есть когда наиболее часто используемые записи расположены в начале таблицы.
будет минимальна при p1≥p2≥…≥pN, то есть когда наиболее часто используемые записи расположены в начале таблицы.
Рассмотрим распределение 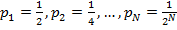

2. Прямой поиск в упорядоченной таблице
 Снимем ограничение иметь лишь последовательный доступ к таблице, при этом получим возможность эффективно использовать отношение порядка в упорядоченной таблице.
Снимем ограничение иметь лишь последовательный доступ к таблице, при этом получим возможность эффективно использовать отношение порядка в упорядоченной таблице.
Бинарный поиск (дихотомический, логарифмический).
Суть его: сначала сравнить К со средним ключом  в таблице; по результату сравнения можно определить, в какой половине таблицы продолжить поиск, применяя при этом ту же процедуру. После не более чем log2N сравнений либо ключ будет найден, либо установлено его отсутствие.
в таблице; по результату сравнения можно определить, в какой половине таблицы продолжить поиск, применяя при этом ту же процедуру. После не более чем log2N сравнений либо ключ будет найден, либо установлено его отсутствие.
Алгоритм В (бинарный поиск). Найти аргумент К в таблице записей R1,R2,…,Rn, ключи которых упорядочены по возрастанию: K1<K2<…<KN. Пусть iнач и iкон – соответственно номера начальной и конечной записей в той области, в которой осуществляется поиск.
⌊·⌋ - целая часть (trunc).

Представим бинарный поиск в виде бинарного дерева решений. Пусть N=16. Тогда «середина»  , => К8 – ключ, соответствующий «середине» и первым (корневым) круглым узлом дерева будет 8.
, => К8 – ключ, соответствующий «середине» и первым (корневым) круглым узлом дерева будет 8.
Если К < К8, то поиск проводится в левом поддереве, сравнивая К с новой «серединой» К4 и т.д. Если К > К8, то поиск идёт в правом поддереве.
Неудачный поиск ведёт в один из внешних квадратных узлов от 0 до N. Например, узел 6 будет достигнут тогда и только тогда, когда К6 < К < К7.

С помощью дерева можно доказать, что справедлива теорема:
При 2k-1≤N≤2k удачный поиск, использующий алгоритм В, требует минимум 1, максимум К сравнений. Неудачный поиск требует k сравнений при N=2k-1 либо k-1 или k сравнений при 2k-1 ≤ N <2k-1.
Следствие: алгоритм В требует максимум [log2N]+1 сравнений, среднее число сравнений при удачном поиске  .
.