Кластерный анализ в SPSS
Программа SPSS позволяет проводить кластерный анализ не только объектов, но и переменных. В последнем случае кластерный анализ может выступать как более простой и нередко более эффективный аналог факторного анализа.
В данном разделе нами будет рассмотрен алгоритм реализации в программе SPSS иерарического агломеративного кластерного анализа. Рассмотрим его реализацию поэтапно.
1. Запустите программу SPSS при помощи значка на рабочем столе или команды Пуск→Программы→ SPSS for Windows → SPSS 11.5 for Windows. В открывшемся диалоговом окне щелкните на кнопку Сancel (Отмена).
2. Создайте новый файл данных или откройте существующий.
3.
 |
В меню Analyze (Анализ) выберите команду Classifi→Hierarchical Cluster (Классификация→Иерархическая кластеризация). На экране появится диалоговое окно Hierarchical Cluster Analysis (Иерархический кластерный анализ), показанное на рисунке 4.2.
Рис. 4.2 Диалоговое окно Hierarchical Cluster Analysis
Структура окна Hierarchical Cluster Analysis типична для большинства диалоговых окон SPSS. Слева находится список переменных текущего файла данных. Выделите переменные, с помощью которых будет осуществляться процесс кластеризации, и при помощи кнопки со стрелкой перенесите их в поле Variable(s) (Переменные). В поле Label Cases by (Различать объекты по) с помощью кнопки со стрелкой переносится переменная, идентифицирующая объекты.
В поле Cluster (Кластеризация) предусмотрены два переключателя (Объекты) и (Переменные). Маркером помечают один из вариантов процедуры кластеризации. В случае кластеризации переменных поле Label Cases by (Различать объекты по) останется пустым.
В нижней части диалогового окна расположены четыре кнопки, предназначенные для задания дополнительных параметров команды.
4. Настройка кнопки Statistics (Статистики)
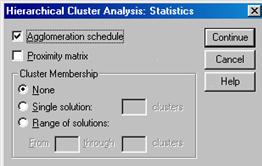 |
При щелчке по кнопке Statistics (Статистики) на экране появляется диалоговое окно Hierarchical Cluster Analysis: Statistics (Иерархический кластерный анализ: Статистики), представленное на рис. 4.3.
Рис. 4.3. Диалоговое окно Hierarchical Cluster Analysis: Statistics
Флажок Agglomeration Schedule (Последовательность слияния) по умолчанию установлен, обеспечивая включение в результаты стандартного компонента вывода кластерного анализа. Флажок Proximity Matrix (Матрица сходства) предназначен для отображения информации о расстояниях между объектами и кластерами. Использование матрицы удобно лишь для небольших файлов данных. Группа Cluster Membership (Кластеры в решении) состоит из трех переключателей, описанных ниже.
None (Нет) - в выводимые результаты включаются все кластеры. Этот вариант установлен по умолчанию.
Single solution (Единственное решение) - позволяет определить точное число выводимых кластеров.
Range of solution (Диапазон решений) - обеспечивает вывод нескольких решений с разным числом кластеров. Так, если ввести в поле (От) число 2. А вполе (До) число 6, то в выводимые результаты будут включены все решения с количеством кластеров от 2 до 6.
5. Настройка кнопки Plots (Диаграммы)
При щелчке по кнопке Plots (Диаграммы) на экране появляется диалоговое окно Hierarchical Cluster Analysis: Plots (Иерархический кластерный анализ: Диаграммы), представленное на рис. 4.4.
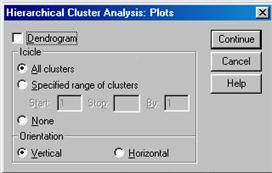 |
Рис. 4.4. Диалоговое окно Hierarchical Cluster Analysis: Plots
Флажок Dendrogram (Дендрограмма) позволяет включить в выводимые результаты дендрограмму.
6. Настройка кнопки Method (Метод)
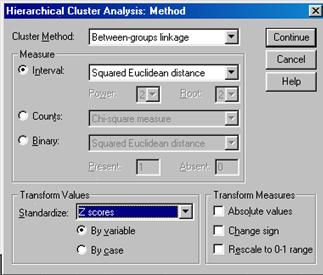 |
При щелчке по кнопке Method (Метод) на экране появляется диалоговое окно Hierarchical Cluster Analysis: Method (Иерархический кластерный анализ: метод), представленное на рис. 4.5.
Рис. 4.5. Диалоговое окно Hierarchical Cluster Analysis: Method
В данном окне раскрывается список Cluster Method (Метод кластеризации), который содержит возможные методы кластеризации объектов, среди них:
Between-groups linkage - метод "межгруппового связывания".
Within- groups linkage - метод "внутригруппового связывания".
Nearest neighbor - метод "одиночного связывания".
Furthest neighbor - метод "полного связывания"
Centroid clustering - метод "центроидной кластеризации".
Wards method - метод Варда.
В раскрывающемся списке Interval (Интервал) по умолчанию выбран пункт Squared Euclidean distance (Квадрат Евклидова расстояния). Это означает, что расстояние между объектами вычисляется как разность квадратов соответствующих переменных этих объектов. Возможен выбор и других мер сходства.
Процедура стандартизации исходных данных выбирается в раскрывающемся списке Standardize (Стандартизация). По умолчанию выбран пункт None (Нет). Однако в случаях, когда стандартизация необходима чаще всего выбирают пункт Z scores (z-шкала).
В группе Transofm Measures (Преобразование значений) имеется три флажка, позволяющих изменить значения переменных: Absolute values (Абсолютные значения), Change Sign (Смена знаков), Rescale to 0-1 (Свести к интервалу 0-1).
7. Настройка кнопки Save (Сохранить)
 |
При щелчке по кнопке Save (Сохранить) на экране появляется диалоговое окно Hierarchical Cluster Analysis: Save New Variables (Иерархический кластерный анализ: сохранение новых переменных), представленное на рис. 4.6.
Рис. 4.6. Диалоговое окно Hierarchical Cluster Analysis:
Save New Variables
С помощью этого окна можно создавать новые переменные значения которых будут хранить вычисленные статистические величины. Если установлен переключатель None (Нет), то никакого сохранения в процессе анализа не производится. В противном случае при выполнении анализа будут созданы переменные, которые окажутся в конце файла данных. После установления соответствующих настроек необходимо с помощью щелчка по кнопке Continue (продолжить) возвратиться в основное диалоговое окно Hierarchical Cluster Analysis.
8. Запуск процедуры выполнения кластерного анализа осуществляется в диалоговом окне окно Hierarchical Cluster Analysis щелчком по кнопке ОК. Кнопка Reset (Сброс) позволяет корректировать настройки.
Контрольные вопросы
1. В чем состоит принципиальное отличие методов многомерных классификаций от комбинационных группировок?
2. Назовите область применения кластерного анализа в маркетинге?
3. Раскройте сущность иерархических агломеративных и дивизимных методов кластерного анализа? В чем их достоинства и недостатки?
4. Раскройте сущность итеративных методов кластерного анализа? В чем их достоинства и недостатки?
5. Раскройте алгоритм реализации иерархического агломеративного кластерного анализа?
6. Что иллюстрирует дендрограмма кластеризации объектов в кластерном анализе?
7. Назовите основные критерии качества классификации объектов в кластерном анализе и их практическую значимость?
8. Раскройте поэтапно алгоритм реализации кластерного анализа в SPSS?
СПИСОК ЛИТЕРАТУРЫ
1. Анурин В., Муромкина И., Евтушенко Е. Маркетинговые исследования потребительского рынка. - СПб.: Питер, 2006. - 260 с.
2. Бернс Э., Буш Р. Основы маркетинговых исследований с использованием Excel. - СПб.: Вильямс, 2006.
3. Белявский И. Маркетинговое исследование: информация, анализ, прогноз. М.: Финансы и статистика, 2001.
4. Власова М.Л. Социологические методы в маркетинговых исследований. - М.: ГУ ВШЭ, 2006.
5. Гмурман В. Е. Теория вероятностей и математическая статистика: Учеб. пособие для вузов. - 8-е изд. - М.: Высшая школа, 2002.
6. Жамбю М. Иерархический кластер-анализ и соответствия. - М.: Финансы и статистика, 1988. - 342 с.
7. Иберла К. Факторный анализ. М.: Статистика, 1980. - 398 с.
8. Коротков А. В. Маркетинговые исследования. - М.: ЮНИТИ-ДАНА, 2005. - 304 с.
9. Мандель И. Д. Кластерный анализ. - М.: Финансы и статистика, 1988. - 176 с.
10. Малхотра К. Маркетинговые исследования и эффективный анализ статистических данных. - М.: Диасофт, 2002.
11. Малхотра К. Маркетинговые исследования: Практическое руководство. 3-е изд. М.: Вильямс, 2002.
12. Многомерный статистический анализ в экономике: Учеб. пособие для вузов / Под ред. В. Н. Тамашевича. - М.: ЮНИТИ-ДАНА, 1999. - 598 с.
13. Математические методы в экономике: Учебник / Под общ. ред. д.э.н., проф. А.В Сидоровича, МГУ им. М.В. Ломоносова. - М.: Издательство "Дом и Сервис", 2001.
14. Моосмюллер Г., Ребик Н.Н. Маркетинговые исследования с SPSS. - М.: Инфра-М, 2007. - 160 с.
15. Наследов А. Д. SPSS: Компьютерный анализ в психологии и социальных науках. - СПб.: Питер, 2007. - 416 с.
16. Пиотровский А., Денисов А. Кластерный анализ как инструмент подготовки эффективных маркетинговых решений // Практический маркетинг. - 2001. - №5.
17. Общая теория статистики: Учебное пособие / Под ред. А.А. Спирина, О.Э. Башиной – М : Финансы и статистика, 1999.
18. Черчилль Г.А. Маркетинговые исследования. - СПб.: Питер, 2007.