Концептуальные модели данных
Ядром любой БД является модель данных (МД), которая представляет собой множество структур данных, ограничений целостности и операций манипулирования данными. С помощью МД могут быть представлены объекты предметной области и взаимосвязи между ними [10].
Наиболее распространенные МД уже были перечислены ранее. По способу установления связей между данными СУБД основывается на использовании трех основных видов модели: иерархической, сетевой, реляционной. Однако различия между этими моделями постепенно стираются, что обусловлено, прежде всего, интенсивными работами в области баз знаний (БЗ) и объектно-ориентированной информационной технологией.
Каждая из указанных моделей обладает характеристиками, делающими ее наиболее удобной для конкретных приложений. В частности, структура иерархических и сетевых СУБД часто не может быть изменена после ввода данных, тогда как структура реляционных СУБД изменяема в любое время. С другой стороны, для больших БД, структура которых остается длительное время неизменной, и постоянно работающих с ними приложений с интенсивными потоками запросов на БД-обслуживание, именно иерархические и сетевые СУБД являются самыми эффективными, так как обеспечивают более быстрый доступ к информации БД, чем реляционные [1, 2].
Иерархическая модель данных.Иерархическая структура представляет совокупность элементов, связанных между собой по определенным правилам. Объекты, связанные иерархическими отношениями, образуют ориентированный граф (перевернутое дерево). К основным понятиям иерархической структуры относятся: уровень, элемент (узел), связь.
Узел — это совокупность атрибутов данных, описывающих некоторый объект. На схеме иерархического дерева узлы представляются вершинами графа.
Каждый узел на более низком уровне связан только с одним узлом, находящимся на более высоком уровне. Иерархическое дерево имеет только одну вершину (корень дерева), не подчиненную никакой другой вершине и находящуюся на самом верхнем (первом) уровне. Зависимые (подчиненные) узлы находятся на втором, третьем и т. д. уровнях. Количество деревьев в БД определяется числом корневых записей. К каждой записи БД существует только один (иерархический) путь от корневой записи. Каждому узлу структуры соответствует один сегмент, представляющий собой поименованный линейный кортеж полей данных. Каждому сегменту (кроме S1-корневого) соответствует один входной и несколько выходных сегментов. Каждый сегмент структуры лежит на единственном иерархическом пути, начинающемся от корневого сегмента (рис. 3.2).
В настоящее время СУБД, поддерживающие на концептуальном уровне только иерархические модели, не разрабатываются. Как правило, системы, использующие иерархический подход, допускают связывание древовидных структур между собой и/или установление связей внутри них. Это приводит к сетевым дата-логическим моделям СУБД.

Рис. 3.2. Иерархическая модель данных
К основным недостаткам иерархических моделей следует отнести:
1. неэффективность реализации отношений типа N:N;
2. медленный доступ к сегментам данных нижних уровней иерархии;
3. четкую ориентацию на определенные типы запросов и др.
В связи с этими недостатками ранее созданные иерархические СУБД подвергаются существенным модификациям, позволяющим поддерживать более сложные типы структур, в первую очередь, сетевые и их модификации (рис. 3.3) [11].
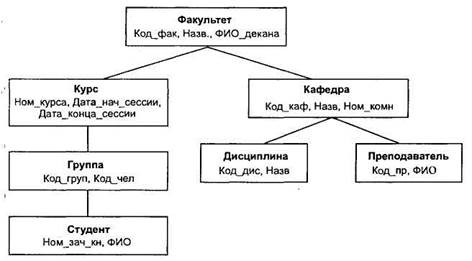
Рис. 3.3. Фрагмент иерархической модели данных
Сетевая модель данных. Всетевой структуре при тех же основных понятиях (уровень, узел, связь) каждый элемент может быть связан с любым другим элементом. Сетевая модель СУБД во многом подобна иерархической: если в иерархической модели для каждого сегмента записи допускается только один входной сегмент при N выходных, то в сетевой модели допускается несколько входных сегментов наряду с возможностью наличия сегментов без входов с точки зрения иерархической структуры [12]. Графическое изображение структуры связей сегментов такого типа моделей представляет собой сеть. Сегменты данных в сетевых БД могут иметь множественные связи с сегментами старшего уровня. При этом направление и характер связи в сетевых БД не являются столь очевидными, как в случае иерархических БД, поэтому имена и направление связей должны идентифицироваться при описании БД (рис. 3.4).
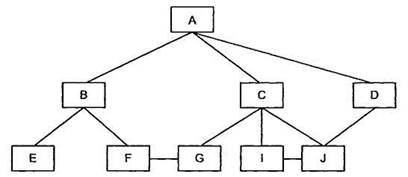
Рис. 3.4. Фрагмент сетевой модели данных
Таким образом, под сетевой СУБД понимается система, поддерживающая сетевую организацию: любая запись, называемая записью старшего уровня, может содержать данные, которые относятся к набору других записей, называемых записями подчиненного уровня. Возможно обращение ко всем записям в наборе, начиная с записи старшего уровня. Обращение к набору записей реализуется по указателям.
В рамках сетевых СУБД легко реализуются и иерархические даталогические модели. Сетевые СУБД поддерживают сложные соотношения между типами данных, что делает их пригодными во многих приложениях. Однако пользователи таких СУБД ограничены связями, определенными для них разработчиками БД-приложений. Более того, подобно иерархическим сетевые СУБД предполагают разработку БД приложений опытными программистами и системными аналитиками.
Среди недостатков сетевых СУБД следует особо отметить проблему обеспечения сохранности информации в БД.
Реляционная модель данных.Понятие реляционный (от англ. relation — отношение) связано с разработками известного американского специалиста в области систем баз данных, сотрудника фирмы IBMдоктора Е. Кодда (Codd E.F., A Relational Model of Data for Large Shared Data Banks. CACM 13: 6, June 1970), который впервые употребил термин «реляционная модель данных».
В течение долгого времени реляционный подход рассматривался как удобный формальный аппарат анализа БД, не имеющий практических перспектив, так как его реализация требовала слишком больших машинных ресурсов. Только с появлением персональных ЭВМ реляционные и близкие к ним системы стали самыми распространенными.
Реляционная модель данных (РМД) представляет собой набор сведений, сгруппированных в одну или несколько таблиц. Таблицу можно представить как двумерный массив или набор записей одинаковой структуры. Записи называют рядами. Таблица состоит из рядов и столбцов. Число столбцов и записей для каждой таблицы теоретически не ограничено. Каждый столбец имеет определенный тип, неизменный для каждой записи внутри таблицы. Множество возможных значений конкретного столбца называется доменом. Значение каждого атрибута должно быть атомарным, неделимым. Каждый ряд таблицы описывает некий отдельный объект. Связь между таблицами существует на логическом уровне и определяется предметной областью за счет логических связей.
Достоинства РМД:
1. нефункциональность языка запроса (SQL) — «что» найти, а не «как» найти. Реляционные СУБД поддерживают Structured Query Language (SQL) — язык структурированных запросов;
2. высокая стандартизованность;
3. наличие четких математических основ для работы с данными.
Недостаток — ограниченность набора возможных типов данных.
Объектно-реляционные модели данных(ОРМД). Расширению возможностей реляционных БД способствует применение в концепции БД понятия объекта, аналогичного понятию объекта в объектно-ориентированном программировании. Это расширение достигается за счет использования таких объектно-ориентированных компонентов, как пользовательские типы данных, инкапсуляция, полиморфизм, наследование, переопределение методов и т. п.
К сожалению, до настоящего времени разработчики не пришли к единому мнению о том, как следует определять ОРМД [2]. Модели, поддерживаемые различными производителями СУБД, существенно отличаются по своим функциональным характеристикам, поэтому о включении объектов в РМД можно говорить только как об общем направлении развития БД. О перспективах этого направления свидетельствует тот факт, что ведущие фирмы-производители СУБД, в числе которых Oracle, Informix и INGRES, расширили возможности своих продуктов до объектно-реляционной СУБД (ОРСУБД).
В большинстве реализаций ОРМД объектами признаются агрегат и таблица (отношение), которая может входить в состав другой таблицы. Методы обработки данных представлены в виде хранимых процедур и триггеров, которые являются процедурными объектами БД, и связаны с таблицами. На внутреннем (физическом) уровне все данные ОРБД хранятся в виде отношений, и ОРСУБД поддерживают язык SQL.
Объектно-ориентированные модели данных.Еще один подход к построению БД — использование объектно-ориентированных моделей данных (ООМД). Моделирование данных в ООМД базируется на понятии объекта. Для ООМД, как и в случае с ОРМД, не существует общепризнанной модели данных [2].
При создании объектно-ориентированных СУБД (ООСУБД) используются разные методы, а именно: встраивание в объектно-ориентированный язык средств для работы с БД; создание объектно-ориентированных библиотек функций для работы с СУБД; расширение существующего языка работы с БД объектно-ориентированными функциями; создание нового языка и новой объектно-ориентированной модели данных.
К достоинствам ООМД относят широкие возможности моделирования предметной области, выразительный язык запросов и повышенную производительность. Эти модели обычно применяются для сложных предметных областей, для моделирования которых не хватает функциональности реляционной модели (например, систем автоматизации проектирования, издательских систем и т. п.).
Среди недостатков ООМД следует отметить отсутствие универсальной модели, недостаток опыта создания и эксплуатации ООБД, сложность использования и недостаточность средств защиты данных.
В 1997 г. рабочая группа Object Database Management Group (ODMG), образованная фирмами-производителями ООСУБД, выпустила стандарт ODMG 2.0 для ООСУБД, в котором описана объектная модель, язык определения запросов, язык объектных запросов и связующие языки C++, Smalltalk и Java.