Построение иерархии диаграмм потоков данных
При построении иерархии потоков данных целесообразно пользоваться следующими рекомендациями:
- Размещать на каждой диаграмме от 3 до 6-7 процессов. Верхняя граница соответствует человеческим возможностям одновременного восприятия и понимания структуры сложной системы с множеством внутренних связей, нижняя граница выбрана по соображениям здравого смысла: нет необходимости детализировать процесс диаграммой, содержащей всего один или два процесса.
- Не загромождать диаграммы не существенными на данном уровне деталями.
- Декомпозицию потоков данных осуществлять параллельно с декомпозицией процессов. Эти две работы должны выполняться одновременно, а не после завершения другой.
- Выбирать ясные, отражающие суть дела имена процессов и потоков, при этом стараться не использовать аббревиатуры.
Первым шагом при построении иерархии DFD является построение контекстных диаграмм. Обычно при проектировании относительно простых ИС строится единственная контекстная диаграмма со звездообразной топологией, в центре которой находится так называемый главный процесс, соединенный с приемниками и источниками информации, посредством которых с системой взаимодействуют пользователи и другие внешние системы. Количество потоков на контекстной диаграмме должно быть по возможности небольшим, поскольку каждый из них может быть в дальнейшем разбит на несколько потоков на следующих уровнях диаграммы.
Внешние сущности выделяются по отношению к основному процессу. Для их определения необходимо выделить поставщиков и потребителей основного процесса, т.е. все объекты, которые взаимодействуют с основным процессом. На этом этапе описание взаимодействия заключается в выборе глагола, дающего представление о том, как внешняя сущность использует основной процесс или используется им. Например, основной процесс – "учет обращений граждан", внешняя сущность – "граждане", описание взаимодействия – "подает заявления и получает ответы". Этот этап является принципиально важным, поскольку именно он определяет границы моделируемой системы.
Для всех внешних сущностей строится таблица событий, описывающая их взаимодействие с основным потоком. Таблица событий включает в себя наименование внешней сущности, событие, его тип (типичный для системы или исключительный, реализующийся при определенных условиях) и реакцию системы.
Если же для сложной системы ограничиться единственной контекстной диаграммой, то она будет содержать слишком большое количество источников и приемников информации, которые трудно расположить на листе бумаги нормального формата, и кроме того, единственный главный процесс не раскрывает структуры распределенной системы. Признаками сложности (в смысле контекста) могут быть:
·наличие большого количества внешних сущностей (десять и более);
·распределенная природа системы;
·многофункциональность системы с уже сложившейся или выявленной группировкой функций в отдельные подсистемы.
Для сложных ИС строится иерархия контекстных диаграмм. При этом контекстная диаграмма верхнего уровня содержит не единственный главный процесс, а набор подсистем, соединенных потоками данных. Контекстные диаграммы следующего уровня детализируют контекст и структуру подсистем.
Иерархия контекстных диаграмм определяет взаимодействие основных функциональных подсистем проектируемой ИС как между собой, так и с внешними входными и выходными потоками данных и внешними объектами (источниками и приемниками информации), с которыми взаимодействует ИС.
Разработка контекстных диаграмм решает проблему строгого определения функциональной структуры ИС на самой ранней стадии ее проектирования, что особенно важно для сложных многофункциональных систем, в разработке которых участвуют разные организации и коллективы разработчиков.
После построения контекстных диаграмм полученную модель следует проверить на полноту исходных данных об объектах системы и изолированность объектов (отсутствие информационных связей с другими объектами).
Для каждой подсистемы, присутствующей на контекстных диаграммах, выполняется ее детализация при помощи DFD. Каждый процесс DFD, в свою очередь, может быть детализирован при помощи DFD или миниспецификации. При детализации должны выполняться следующие правила:
·правило балансировки - означает, что при детализации подсистемы или процесса детализирующая диаграмма в качестве внешних источников/приемников данных может иметь только те компоненты (подсистемы, процессы, внешние сущности, накопители данных), с которыми имеет информационную связь детализируемая подсистема или процесс на родительской диаграмме;
·правило нумерации - означает, что при детализации процессов должна поддерживаться их иерархическая нумерация. Например, процессы, детализирующие процесс с номером 12, получают номера 12.1, 12.2, 12.3 и т.д.
Миниспецификация (описание логики процесса) должна формулировать его основные функции таким образом, чтобы в дальнейшем специалист, выполняющий реализацию проекта, смог выполнить их или разработать соответствующую программу.
Миниспецификация является конечной вершиной иерархии DFD. Решение о завершении детализации процесса и использовании миниспецификации принимается аналитиком исходя из следующих критериев:
·наличия у процесса относительно небольшого количества входных и выходных потоков данных (2-3 потока);
·возможности описания преобразования данных процессом в виде последовательного алгоритма;
·выполнения процессом единственной логической функции преобразования входной информации в выходную;
·возможности описания логики процесса при помощи миниспецификации небольшого объема (не более 20-30 строк).
Спецификации должны удовлетворять следующим требованиям:
·Для каждого процесса нижнего уровня должна существовать одна и только одна спецификация.
·Спецификация должна определять способ преобразования входных потоков в выходные.
·Нет необходимости (по крайней мере на стадии формирования требований) определять метод реализации этого преобразования.
·Спецификация должна стремиться к ограничению избыточности - не следует переопределять то, что уже было определено на диаграмме.
·Набор конструкций для построения спецификаций должен быть простым и понятным.
Фактически спецификации представляют собой описания алгоритмов задач, выполняемых процессами. Спецификации содержат:
·Номер и/или имя процесса.
·Списки входных и выходных данных.
·Тело (описание процесса), являющееся спецификацией алгоритма или операции, трансформирующей входные потоки данных в выходные.
При построении иерархии диаграмм потоков данных переходить к детализации процессов следует только после определения содержания всех потоков и накопителей данных, которое описывается при помощи структур данных. Для каждого потока данных формируется список всех его элементов данных, затем элементы данных объединяются в структуры данных, соответствующие более крупным объектам данных (например, строкам документов или объектам предметной области). Каждый объект должен состоять из элементов, являющихся его атрибутами. Структуры данных могут содержать альтернативы, условные вхождения и итерации.
Условное вхождение означает, что данный компонент может отсутствовать в структуре (например, структура «данные о страховании» для объекта «служащий»).
Альтернатива означает, что в структуру может входить один из перечисленных элементов.
Итерация означает вхождение любого числа элементов в указанном диапазоне (например, элемент «имя ребенка» для объекта «служащий»).
Для каждого элемента данных может указываться его тип (непрерывные или дискретные данные). Для непрерывных данных может указываться единица измерения (кг, см и т.п.), диапазон значений, точность представления и форма физического кодирования. Для дискретных данных может указываться таблица допустимых значений.
После декомпозиции основного процесса для каждого подпроцесса строится аналогичная таблица внутренних событий.
Следующим шагом после определения полной таблицы событий выделяются потоки данных, которыми обмениваются процессы и внешние сущности. Простейший способ их выделения заключается в анализе таблиц событий. События преобразуются в потоки данных от инициатора события к запрашиваемому процессу, а реакции – в обратный поток событий. После построения входных и выходных потоков аналогичным образом строятся внутренние потоки. Для их выделения для каждого из внутренних процессов выделяются поставщики и потребители информации. Если поставщик или потребитель информации представляет процесс сохранения или запроса информации, то вводится хранилище данных, для которого данный процесс является интерфейсом.
После построения законченной модели системы ее необходимо верифицировать (проверить на полноту и согласованность). В полной модели все ее объекты (подсистемы, процессы, потоки данных) должны быть подробно описаны и детализированы. Выявленные недетализированные объекты следует детализировать, вернувшись на предыдущие шаги разработки. В согласованной модели для всех потоков данных и накопителей данных должно выполняться правило сохранения информации: все поступающие куда-либо данные должны быть считаны, а все считываемые данные должны быть записаны. Непротиворечивость системы обеспечивается выполнением наборов формальных правил о возможных типах процессов: на диаграмме не может быть потока, связывающего две внешние сущности – это взаимодействие удаляется из рассмотрения; ни одна сущность не может непосредственно получать или отдавать информацию в хранилище данных – хранилище данных является пассивным элементом, управляемым с помощью интерфейсного процесса; два хранилища данных не могут непосредственно обмениваться информацией – эти хранилища должны быть объединены.
Кроме основных элементов, в состав DFD входят словари данных, которые являются каталогами всех элементов данных, присутствующих в DFD, включая групповые и индивидуальные потоки данных, хранилища и процессы, а также все их атрибуты.
К преимуществам методики DFD относятся:
·возможность однозначно определить внешние сущности, анализируя потоки информации внутри и вне системы;
·возможность проектирования сверху вниз, что облегчает построение модели "как должно быть";
·наличие спецификаций процессов нижнего уровня, что позволяет преодолеть логическую незавершенность функциональной модели и построить полную функциональную спецификацию разрабатываемой системы.
К недостаткам модели отнесем: необходимость искусственного ввода управляющих процессов, поскольку управляющие воздействия (потоки) и управляющие процессы с точки зрения DFD ничем не отличаются от обычных; отсутствие понятия времени, т.е. отсутствие анализа временных промежутков при преобразовании данных (все ограничения по времени должны быть введены в спецификациях процессов).
На рис. 8 приведен пример DFD-схемы бизнес-процесса "Оформлении и выдача трудовой книжки сотруднику при увольнении", разработанной в нотации Гейна-Сарсона, а на рис. 9-в нотации Йордона-Де Марко.
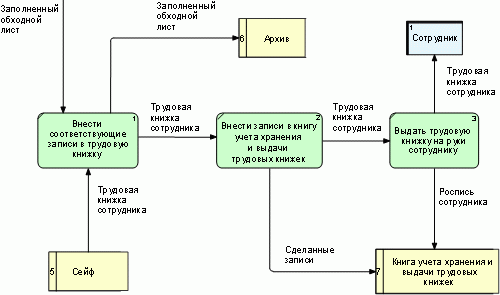
Рис. 8. DFD-схема бизнес-процесса "Оформлении и выдача трудовой книжки сотруднику при увольнении" в нотации Гейна-Сарсона.
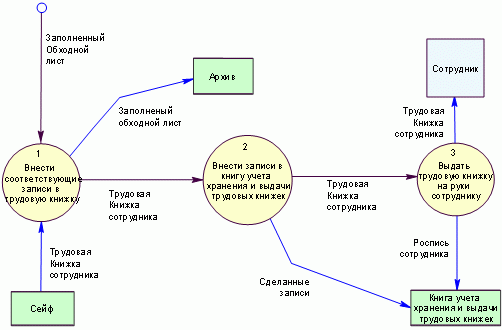
Рис. 9. DFD-схема бизнес-процесса "Оформлении и выдача трудовой книжки сотруднику при увольнении" в нотации Йордона-Де Марко.
IDEF3
Этот метод предназначен для моделирования последовательности выполнения действий и взаимозависимости между ними в рамках процессов. Модели IDEF3 могут использоваться для детализации функциональных блоков IDEF0, не имеющих диаграмм декомпозиции.
Нотация IDEF3 использует категорию Сценариев (Scenario) для упрощения структуры описаний сложного многоэтапного процесса. IDEF3 осуществляет реализацию следующей информации о процессе:
·объекты, участвующие в описании операции;
·функции, которые выполняют эти объекты;
·взаимосвязь между процессами;
·состояния и изменения, которым подвергаются объекты;
·время выполнения и контрольные точки синхронизации работ;
·ресурсы, необходимые для выполнения работ.
Существует два типа диаграмм в стандарте IDEF3:
1. PFDD - диаграммы описания последовательности этапов процесса.
2. OSTN - диаграммы состояния объекта и его изменений в процессе.
На рис. 10 изображена диаграмма PFDD, показывающая процессы создания программного обеспечения. Прямоугольники на диаграмме PFDD называются функциональными элементами или элементами поведения (UOB) и обозначают событие, стадию процесса или принятие решения (рис. 11). Каждый UOB имеет конкретное имя (функция, процесс, действие, акт, событие, сценарий, процедура, операция, решение), отображаемое в глагольном наклонении и уникальный номер (номер действия обычно предваряется номером его родителя, например, 1.1.). В правом нижнем углу UOB элемента располагается ссылка на какие-либо элементы функциональной модели IDEF0 или на отделы, конкретных исполнителей, выполняющие конкретный процесс.
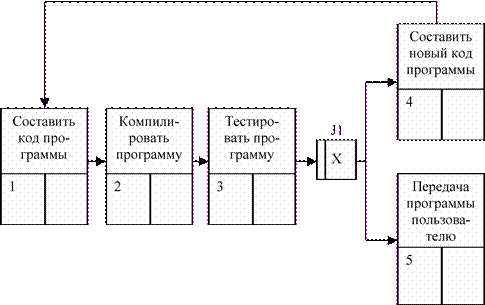
Рис. 10. PFDD-диаграмма создания электронной программы.
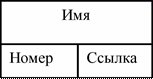
Рис. 11. Функциональный элемент (UOB).
Стрелки или линии являются отображением хода выполнения операций между UOB-блоками в ходе процесса (рис. 12).

а) б) в)
Рис. 12. Стрелки для отображения хода выполнения операции
Линии в нотации IDEF3 бывают следующих видов:
1. Временное предшествование или старшая (Temporal precedence, рис. 12, а) - сплошная линия, связывающая UOB. Рисуется слева направо или сверху вниз. Исходное действие должно завершиться, прежде чем конечное действие сможет начаться.
2. Нечеткое отношение (Relationship link, рис. 12, б) - пунктирная линия, использующаяся для изображения связей между UOB в том случае, если конечное действие сможет начаться и даже завершиться до того момента, когда завершится исходное действие.
3. Объектный поток (Object flow, рис. 12, в) - стрелка с двумя наконечниками используется для описания того факта, что объект (деталь) используется в двух или более единицах работы, например, когда объект порождается в одной работе и используется в другой (т.е. выход исходного действия является входом конечного действия). Исходное действие должно завершиться, прежде чем конечное действие сможет начаться. Наименования потоковых связей должны чётко идентифицировать объект, который передается с их помощью.
Все связи в IDEF3 являются однонаправленными.
Завершение одного действия может инициировать начало выполнения сразу нескольких других действий, или наоборот, определенное действие может требовать завершения нескольких других действий до начала своего выполнения (ветвление процесса). Ветвление процесса отражается с помощью специальных блоков, называемых перекрестками. Каждый перекресток (Junction) имеет свой определенный идентификационный номер (на рис. 10 J1 - перекресток). Перекресток не может использоваться одновременно для слияния и для разветвления. При вводе перекрестка в диаграмму необходимо указать тип перекрестка. Типы перекрестков представлены в таблице 2.
Таблица 2. Описание типов перекрестков.
| Обозначение | Наименование | Смысл для стрелок слияния | Смыл для стрелок разветвления |
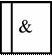
| Асинхронное И (asynchronous AND) | Все предшествующие процессы должны быть завершены | Все следующие процессы должны быть запущены |

| Cинхронное И (synchronous AND) | Все предшествующие процессы завершены одновременно | Все следующие процессы запускаются одновременно |

| Асинхронное ИЛИ (asynchronous OR) | Один или несколько предшествующих процессов должны быть завершены | Один или несколько следующих процессов должны быть запущены |

| Синхронное ИЛИ (synchronous OR) | Один или несколько предшествующих процессов завершаются одновременно | Один или несколько следующих процессов запускаются одновременно |

| Исключающее ИЛИ(XOR, exclusive OR) | Только один предшествующий процесс завершен | Только один следующий процесс запускается |
Пояснение: Перекресток "Исключающий ИЛИ" обозначает, что после завершения работы "A" (рис. 13), начинает выполняться только одна из трех расположенных параллельно работ B, С или D в зависимости от условий 1, 2 и 3. Перекресток "И" обозначает, что после завершения работы "A", начинают выполняться одновременно три параллельно расположенные работы B, С и D. Перекресток "ИЛИ" обозначает, что после завершения работы "A", может запуститься любая комбинация трех параллельно расположенных работ B, С и D. Например может запуститься только одна из них, могут запуститься три работы, а также могут запуститься двойные комбинации В и С, либо C и D, либо B и D. Перекресток "Исключающий ИЛИ" является самым неопределенным, так как предполагает несколько возможных сценариев реализации бизнес-процесса и применяется для описания слабо формализованных ситуаций.

Рис. 13. Применение перекрестков "Исключающий ИЛИ", "И" и "ИЛИ" - схемы расхождения.
4

Рис. 14. Применение перекрестков "Исключающий ИЛИ", "И" и "ИЛИ" - схемы схождения.
Сценарий, отображаемый на диаграмме (рис. 10), можно описать в следующем виде. Программный код, подготовленный к компиляции, компилируется в компиляторе программ. В процессе компиляции создается исполнительный файл программы. После этого, производится тестирование программы, после которой начинается этап проверки программного продукта. Если тест подтверждает недостаточное качество программы, то она заново пропускается через этап создания программного кода. Если программа успешно проходит контроль качества, то она отправляется пользователю.
Метод IDEF3 позволяет декомпозировать действие несколько раз, что обеспечивает документирование альтернативных потоков процесса в одной модели.
Каждый функциональный блок UOB может иметь последовательность декомпозиций. Номера UOB дочерних диаграмм имеют сквозную нумерацию, т.е., если родительский UOB имеет номер "1", то блоки UOB на его декомпозиции будут соответственно иметь номера "1.1", "1.2" и т.д.
Если диаграммы PFDD представляют технологический процесс "С точки зрения наблюдателя", то другой класс диаграмм IDEF3 - OSTN позволяет рассматривать тот же самый процесс "С точки зрения объекта". На рис. 15 представлено отображение процесса создания электронной программы с точки зрения OSTN диаграммы. Состояния объекта (в нашем случае электронной программы) и изменение состояния являются ключевыми понятиями OSTN диаграммы. Состояния объекта отображаются окружностями, а их изменения направленными линиями. Каждая линия имеет ссылку на соответствующий функциональный блок UOB, в результате которого произошло отображаемое ей изменение состояния объекта.
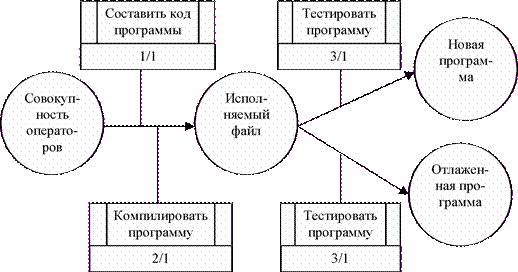
Рис. 15. Пример OSTN-диаграммы создания электронной программы.
На схеме бизнес-процесса также можно использовать такой элемент как "объект- ссылка", который связывается с работами и перекрестками. Ссылки обеспечивают более полное понимание, дополнительный смысл и упрощение описания процесса. Ссылки позволяют:
·обращаться к ранее определенному действию;
·организовывать циклы;
·уточнять работу перекрестков;
·связывать элементы диаграммы с каким-либо внешним объектом;
·комментировать различные элементы диаграммы.
Ссылка изображается в виде прямоугольника. В верхней его части указывается тип ссылки и ее имя.

Рис. 16. Ссылки
Ссылки могут быть различного типа. Список типов ссылок приведен в таблице 3.
Таблица 3. Типы ссылок.
| Тип ссылки | Назначение |
| OBJECT | Описывает участие важного объекта в действии. |
| GOTO | Позволяет применять на диаграмме циклический переход. В том случае, когда все действия цикла находятся в рамках одной диаграммы, цикл можно изобразить стрелкой, которая будет указывать на начало цикла. Тогда ссылка будет связана с перекрестком, управляющим циклом. |
| UOB | Предназначена для многократного вызова какого-либо действия в рамках одной модели |
| NOTE | Позволяет прокомментировать присутствие какого-либо элемента на диаграмме. |
| ELAB (elaboration) | Применяется для уточнения использования ветвления стрелок на перекрестках. |
Примеры использования ссылок различного типа приведены на рис. 17.
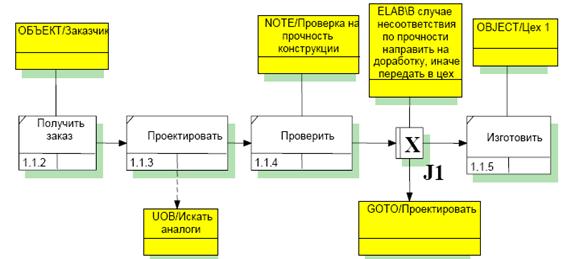
Рис. 17. Примеры использования ссылок различного типа
Таким образом, можно сделать следующие выводы по практическому использованию: применение универсальных графических языков моделирования IDEF0, IDEF3 и DFD обеспечивает логическую целостность и полноту описания, необходимую для достижения точных и непротиворечивых результатов на этапе анализа.
По диаграммам делаем следующий вывод: наиболее существенное различие между разновидностями структурного анализа заключается в их функциональности.
Модели SADT (IDEF0) наиболее удобны при построении функциональных моделей. Они наглядно отражают функциональную структуру объекта: производимые действия, связи между этими действиями. Таким образом, четко прослеживается логика и взаимодействие процессов организации. Главным достоинством нотации является возможность получить полную информацию о каждой работе, благодаря ее жестко регламентированной структуре. С ее помощью можно выявить все недостатки, касающиеся как самого процесса, так и то, с помощью чего он реализуется: дублирование функций, отсутствие механизмов, регламентирующих данный процесс, отсутствие контрольных переходов и т.д.
DFD позволяет проанализировать информационное пространство системы и используется для описания документооборота и обработки информации. Поэтому, диаграммы DFD применяют в качестве дополнения модели бизнес-процессов, выполненной в IDEF0.
IDEF3 хорошо приспособлен для сбора данных, требующихся для проведения анализа системы с точки зрения рассогласования/согласования процессов во времени.
Нельзя говорить о достоинствах и недостатках отдельных нотаций. Возможны ситуации, при которых анализ IDEF0 не обнаружил недостатков в деятельности организации с точки зрения технологического или производственного процесса, однако это не является гарантией отсутствия ошибок. Поэтому в следующем этапе анализа необходимо перейти к исследованию информационных потоков с помощью DFD и затем объединить эти пространства с помощью последней нотации - IDEF3.
Сегодня для описания функциональности разработки предлагаются различные инструменты. Например:
· CASE-средство AllFusion Process Modeler (BPwin) компании Computer Associates. AllFusion Process Modeler наряду с ERwin Data Modeler (ERwin), входит в состав пакета программных средств AllFusion Modeling Suite. Основным преимуществом данного инструмента является присутствие нотаций IDEF и DFD, которые распространены в российских компаниях и принята в России на уровне стандарта, а также связь с продуктом Erwin, используемым для проектирования структур данных.
· CASE-средство Silverrun американской фирмы Сomputer Systems Advisers, Inc. (CSA) используется для анализа и проектирования ИС бизнес-класса [22] и ориентировано в большей степени на спиральную модель ЖЦ. Оно применимо для поддержки любой методологии, основанной на раздельном построении функциональной и информационной моделей (диаграмм потоков данных и диаграмм "сущность-связь").
· CASE.Аналитик 1.1 является практически единственным в настоящее время конкурентоспособным отечественным CASE-средством функционального моделирования. Его основные функции:
o построение и редактирование DFD;
o анализ диаграмм и проектных спецификаций на полноту и непротиворечивость;
o получение разнообразных отчетов по проекту;
o генерация макетов документов в соответствии с требованиями ГОСТ 19.ХХХ и 34.ХХХ.
· Также существует множество программ для рисования различных диаграмм, например, MS Visio или Dia.
Лекция 5
ТЕМА: Проектирование с использованием метода «сущность-связь».
Литература: 1. Карпова И.П. Проектирование реляционных баз данных //методические указания к курсовому проектированию по курсу "Базы данных"
2. http://citforum.ru/database/dblearn/dblearn08.shtml -Пушников А.Ю. Введение в системы управления базами данных// Учебное пособие.
В реальном проектировании структуры базы данных применяется так называемое, семантическое моделирование. Семантическое моделирование представляет собой моделирование структуры данных, опираясь на смысл этих данных. В качестве инструмента семантического моделирования используются различные варианты диаграмм сущность-связь (ER - Entity-Relationship), которые могут быть относительно легко отображены в любую систему баз данных.
Первый вариант модели сущность-связь был предложен в 1976 г. Питером Пин-Шэн Ченом. В дальнейшем многими авторами были разработаны свои варианты подобных моделей (нотация Мартина, нотация IDEF1X, нотация Баркера и др.). Кроме того, различные CASE-средства используют несколько отличающиеся друг от друга нотации ERD. Одна из наиболее распространенных нотаций предложена Баркером и используется в Oracle Designer. В CASE-средстве SilverRun используется один из вариантов нотации Чена. CASE-средства ERwin, ER / Studio, Design / IDEF используют методологию IDEF 1Х. По сути, все варианты диаграмм сущность-связь исходят из одной идеи - рисунок всегда нагляднее текстового описания. Все такие диаграммы используют графическое изображение сущностей предметной области, их свойств (атрибутов), и взаимосвязей между сущностями.
Мы опишем работу с ER-диаграммами близко к нотации Баркера, как довольно легкой в понимании основных идей.