Числа с плавающей запятой
Вычислительные системы широко используют представление чисел с плавающей точкой. Идея этого представления состоит в том, чтобы нормализовать позиционную двоичную дробь, избавившись от незначащих старших нулевых битов освободив место для (возможно) значащих младших разрядов. Сдвиг, который нужен для нормализации, записывается в битовом поле, называемое порядком. Само же число называется мантиссой.
Пример.Число 0072.3500(10) -до нормализации и 0,7235х102 -после.
В двоичной СС запись будет следующей: до нормализации -001001000,100011 и после -1001000100011 х 27
Целая часть Дробная часть
| , | До нормализации |
15 6 5 0
| После нормализации |
Порядок =7 мантисса
В форме представления с плавающей запятой (точкой) число изображается в виде двух групп цифр:
• мантисса;
• порядок.
При этом абсолютная величина мантиссы должна быть меньше 1, а порядок должен быть целым числом.
Например, приведенные ранее числа в нормальной форме запишутся следующим образом:
+0,721355 х 103;
+0,328 х 10-3;
-0,103012026 х 105.
Нормальная форма представления обеспечивает большой диапазон отображения чисел и является основной в современных компьютерах.
В форме с плавающей запятой числа представляются в виде произведений:
C = qП ∙M = X∙ M (1.7)
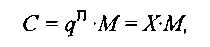 где q — основание системы счисления (обычно целая степень числа 2);
где q — основание системы счисления (обычно целая степень числа 2);
П — порядок числа длиной k+1 (целое число со знаком, где к –число знач.цифр);
М— мантисса числа длиной г +1 (правильная дробь со знаком);
X - характеристика числа.
Знак всего числа определяется знаком мантиссы.
Для мини-компьютеров основания порядка и мантиссы совпадают (далее предполагается этот случай), а для больших машин — они различны. Представление числа формулой (1.7) называют также полулогарифмическим, потому что только часть числа — характеристика — представляется в логарифмической форме.
Следует заметить, что все числа с плавающей запятой хранятся в машине в так называемом нормализованном виде.
Нормализованным называют такое число, старший разряд мантиссы которого больше нуля. У нормализованных двоичных чисел, следовательно, 0,5 < │М│< I.
Нормализованные, т. е. приведенные к правильной дроби, числа:
10,3510 = 0,103510 x 10+2;
0,000072458 = 0,72458 х 8 -4;
F5C,9B16 = 0,F5C9B16 x 16+3;
В памяти ЭВМ числа с ПТ хранятся в двух форматах:
• слово — 32 бита, или 4 байта;
• двойное слово — 64 бита, или 8 байт.
Разрядная сетка для чисел с ПТ имеет следующую структуру:
• нулевой разряд — это знак числа (0 — «минус», 1 — «плюс»);
• с 1 по 7 разряд записывается порядок в прямом двоичном коде, пустые разряды заполняются нулями. В первом разряде указывается знак порядка (1 — «плюс» или 0 — «минус»);
• с 8 по 31 (63) указывается мантисса, слева направо без нуля целых в прямом двоичном коде и для отрицательных чисел и пустые разряды заполняются нулями.
Мантисса называется нормализованной, если ее значение определяется неравенством вида
 ≤ |M| < 1 т.е. для основания q = 2 имеем: 0,5 < М< 1.
≤ |M| < 1 т.е. для основания q = 2 имеем: 0,5 < М< 1.
| Пример 1.3 Иллюстрация записи числа с плавающей запятой: А2 = 21∙110,111 = 22∙11,0111 = 24∙0,110111 |
Значение порядка (П = 1, 2 и 4) указывает на количество позиций, на которые "плавает" запятая.
Формат числа с плавающей запятой в 16-разрядной сетке показан на рис. 1.8. Тут для модулей порядка и мантиссы отведено соответственно пять (с 10 по 14) и девять (с 0 по 8) разрядов. Запятая в порядке размещена (условно) после младшего разряда, а в мантиссе — перед старшим. Знаки порядка и мантиссы размещены перед их старшими разрядами.
15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0 Нумерация разрядов числа
| +/- | Порядок | +/- | Мантисса |
Рисунок 1.8 –Формат чисел в форме плавающей запятой
Абсолютное значение числа С в форме с плавающей запятой с учетом формул (1.7), (1.9) и (1.13) изменяется в пределах
Xmin Mmin = Cmin ≤ |C| ≤ Cmax = Xmax Mmax (1.8)
где Xmin =2-Пmax ( Пmax = 2r -1, где r –разрядность модуля порядка )
Mmin =2-1
Xmax =2+Пmax
Mmax =1-2-k (k –разрядность модуля мантиссы)
Диапазон представления чисел в форме с плавающей запятой
| Пример 1.4 Рассчитать значение диапазона ДC для числа С при г = 5, к = 9. С учетом выражения (1.15) получаем: если Пmax = 2r -1= 25 – 1 = 31 то DC =2+Пmax+1 =231+1= 232 что приблизительно соответствует десятичному числу 1032∙0,3 ≈ 109. Диапазон представления чисел с плавающей запятой приблизительно больше в Пmax раз диапазона представления чисел в форме с фиксированной запятой. |
Абсолютная погрешность представления чисел в форме с плавающей запятой зависит от погрешности мантиссы и порядка числа:
∆С = ∆М∙2±П; ∆М =2(k+1) (1.10)
где ∆M— погрешность представления мантиссы.
Минимальная и максимальная относительные погрешности представления чисел в форме с плавающей запятой не зависят от характеристики (она записывается в числителе и знаменателе выражения и потому сокращается).
С учетом формул (1.14) и (1.16) относительные погрешности рассчитывают из соотношений:
δCmin =  =
= 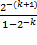 = 2-(k+1) ; δCmax =
= 2-(k+1) ; δCmax = 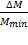 =
=  = 2-k (1.11)
= 2-k (1.11)
Из выражений (1.17) следует, что относительные погрешности представления чисел в форме с плавающей запятой практически постоянны во всем диапазоне чисел.
| 1.4 Представление информации в микропроцессорах класса Pentium |
Рассмотрим представления операндов в 32-разрядных микропроцессорах класса Pentium. В них используются такие типы данных: целые числа, вещественные числа, двоично-десятичные числа и строки битов, байтов и слов. Целые числа представляются со знаком и без знака в форматах байта, полуслова, слова, двойного и учетверенного слова длиной соответственно 8, 16, 32, 64 и 128 бит (рис. 1.9).
31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
| +/- | байт |
| +/- | Полуслово |
| +/- | Слово |
Рисунок 1.9 – Форматы целых чисел со знаком
Над числами в этих форматах выполняются операции сложения, вычитания, умножения, деления. Диапазоны представления знаковых и беззнаковых значений в данных форматах представлены в табл. 1.4.
| Формат числа | Диапазон представления чисел | |
| без знака | со знаком | |
| Байт | 0...255 | -128. .. + 127 |
| Полуслово | 0...65535 | -32768...+32767 |
| Слово | 0...4∙109 | -2∙109...+2∙109 |
| Двойное слово | 0...5∙10'9 | -2,5∙10,9...+2,5∙1019 |
Вещественные числа представлены в формате с плавающей запятой в коротком (32 бит), длинном (64 бит) и расширенном (80 бит) форматах (рис. 1.10). Числа с плавающей запятой длиной 32 и 64 бит, которые используются во многих компьютерах, обычно называют числами с одинарной (32разряда) и двойной точностью (64 разряда).
Расширенный формат (80 разрядов) характерен только для процессоров класса Pentium.
31 30 24 23 0
| +/- | Порядок = 8 | Мантисса (24 бит) |
63 62 53 52 0
| +/- | Порядок (11 бит) | Мантисса (53 бит) |
79 78 64 63 0
| +/- | Порядок (15 бит) | Мантисса (64 бит) |
Рисунок 1.10 – Форматы чисел с плавающей запятой: короткий, длинный и расширенный
В данных форматах чисел с плавающей запятой используются смещенные порядки ПСМ:
П + 127 для r = 8
ПСМ = П + ∆П = П + 2r-1 – 1 =П + 1023 для r = 11
П + 16383 для r = 15
Где: П — значение истинного порядка;
∆П = 2Г-' - 1 — смещение;
г — длина порядка, которая равна 8, 11 или 15 бит соответственно для короткого, длинного и расширенного формата.
Значение ПСМ всегда положительное, поэтому знаковый разряд не нужен. Представление порядка со смещением упрощает операции сравнения чисел с плавающей запятой, что особенно важно для алгоритмов сортировки.
Значение числа с плавающей запятой и смещенным порядком определяется по формуле
С = (-1)S  (F0 , F1 , . . . Fi , . . . Fn)
(F0 , F1 , . . . Fi , . . . Fn)
где S — знак числа; п — число, которое для разных форматов равно 23, 52 или 63.
В машине мантисса представлена в нормализованной форме, которая состоит из целой части F0 = 1 и дроби в таком виде:
M = 1, F1 , F2 , . . . Fi , . . . Fn
В коротком и длинном форматах бит F0 при передаче чисел и хранении их в памяти не фигурирует. Это — скрытый (неявный) бит, который в нормализованном числе всегда равен единице.
| Пример 1.5 Представить десятичное число -247,375 в коротком формате. Двоичный код этого числа равен -11110111,011; истинный порядок будет +7 (запятая сдвигается влево на семь разрядов), а смещение достигнет значения Псм = 127 + 7 = 134. С учетом скрытого бита F0 - 1 имеем: Знак Порядок Мантисса 1 10000110 ,1110 1110 1100 0000 0000 0000. |
Параметры форматов вещественных чисел представлены в табл. 1.5.
| Параметры | Формат | ||
| короткий | длинный | расширенный | |
| Длина формата, бит | |||
| Длина мантиссы, бит | |||
| Длина порядка, бит | |||
| Смещение порядка | + 127 | + 1023 | +16383 |
| Диапазон | 10±38 | 10±308 | 10±4932 |
Числа в коротком и длинном форматах существуют только в памяти. При загрузке чисел в одном из этих форматов в микропроцессор они автоматически преобразуются в 80-битный формат, который используется только для внутренних oneраций. Аналогично данные из процессора преобразуются в короткий или длинный формат для хранения в памяти.
Точность вычислений чисел с плавающей запятой возрастает с увеличением длины мантиссы. Диапазон представления чисел с плавающей запятой зависит от длины порядка и основания счисления q. В машинах ЕС ЭВМ значение q = 16. В процессорах Pentium диапазон представления чисел в коротком формате для q = 2 находится в пределах 10±38. Если же для этого формата взять основание q = 16, то получим значение диапазона в пределах 10±152.
В микропроцессорах Pentium используются двоично-десятичные цифры в таких форматах:
• восьмиразрядные упакованные, которые содержат в одном байте две десятичные цифры в коде 8421, например, 3910 = 0011 10012-10;
• восьмиразрядные неупакованные, которые содержат одну десятичную цифру в байте (младшая тетрада) вместе с признаком (зоной) 00112 в международном коде ASCII,
например, 4910 = 0011 0100 0011 10012-10
Представление десятичного числа 136492 в неупакованном и упакованном форматах показано на рис. 1.11;
7 0 7 0 7 0 7 0 7 0 7 0
| 0011 0001 | 0011 0011 | 0011 0110 | 0011 0100 | 0011 1001 | 0011 0010 | Неупакованный формат |
| 0001 0011 | 0110 0100 | 1001 0010 | Упакованный формат |
Рисунок 1.11 – Представление десятичных цифр в различных форматах
• 80-разрядные упакованные, в которые записываются 19 десятичных цифр (19 тетрад), и в старшую тетраду (20 тетрада) записывается знак числа.
| 1.5 Информационные меры |
В теории передачи и преобразования информации установлены информационные меры количества и качества информации — семантические, структурные, статистические.
Ø Семантический подход позволят выделить полезность или ценность информационного сообщения. В структурном аспекте рассматривают строение массивов информации и их измерение простым подсчетом информационных элементов или комбинаторным методом.
Ø Структурный подход используют для оценки возможностей информационных систем вне зависимости от условий их применения. При использовании структурных мер информации учитывают только дискретное строение сообщения, количество содержащихся в нем информационных элементов, связей между ними. При структурном подходе различают геометрическую, комбинаторную и аддитивную меры информации.
§ Геометрическая мера определяет параметры геометрической модели информационного сообщения (длина, площадь, объем) в дискретных единицах. Эту меру применяют как для оценки информационной емкости всей модели, так и для оценки количества информации в одном сообщении.
§ В комбинаторной мере количество информации I определяют количеством комбинаций элементов (символов), которые совпадают с числом:
• сочетаний из q элементов по п:

например, для множества цифр 1, 2, 3, 4 можно составить шесть сочетаний по две цифры: 12, 13, 14, 23, 24, 34;
• перестановок I = q!,
например, для множества букв а, в, с можно получить шесть перестановок: авс, асе, вас, вса, сав, сва;
• размещений с повторениями из q элементов по п:
Например, для q = 0, 1 и n = 3 имеем: 000, 001, 010, 011, 100, 101, 110, 111.
§ Широкое распространение получила аддитивная мера.
Пусть N—число равновероятных сообщений, п — их длина, q — число букв алфавита, используемого для передачи информации. Количество возможных сообщений длины п равняется числу размещений с повторениями
N = qn. (1.11)
Эту меру наделяют свойством аддитивности, чтобы она была пропорциональна длине сообщения и позволяла складывать количество информации ряда источников. Для этого Хартли предложил логарифмическую функцию как меру количества информации (I):
I = log N = n log q. (1.12)
Количество информации, которое приходится на один элемент сообщения, называется энтропией (H).
H = I/n = log q. (1.13)
Основание логарифма зависит от выбора единицы количества информации. Если для алфавита используют двоичные цифры 0 и 1, то за основание логарифма принимают q = 2, в результате чего
I = n log2 2 = п.
При длине п = 1 получают I = 1 и это количество информации называют битом.
Передача сообщения длиной п = 1 эквивалентна выбору одного из двух возможных равновероятных сообщений — одно из них равно единице, другое — нулю. Двоичное сообщение длины п содержит п битов информации. Если основание логарифма равно 10, то количество информации измеряется в десятичных единицах — дитах, причем 1 дит = 3,32 бита.
Например, текст составлен из 32 букв алфавита и передается последовательно по телетайпу в двоичном коде. При этом количество информации I = log2N = log232 = 5 битов.
Далее используются логарифмы с основанием два.
Ø В общем случае сообщения появляются с разной вероятностью. Статистическая мера использует вероятностный подход к оценке количества информации. Согласно Шеннону каждое сообщение характеризуется вероятностью появления, и чем она меньше, тем больше в сообщении информации. Вероятность конкретных типов сообщений устанавливают на основе статистического анализа.
Пусть сообщения образуются последовательной передачей букв некоторого алфавита:
х1, ..., хi ..., хq
с вероятностью появления каждой буквы: р(х1) = р1, ..., p(xi) =рi ..., р(хq) = рq,
при этом выполняется условие: р1 + ... + рi + ... + рq = 1.
Множество с известным распределением элементов называют ансамблем. Согласно Шеннону количество информации, которое содержится в сообщении хi, рассчитывают по формуле:

Для абсолютно достоверных сообщений рi = 1, тогда количество информации I(xi) = 0; при уменьшении значения pi количество информации увеличивается.
Пусть в ансамбле все буквы алфавита х1, ..., хi ... , хq — равновероятны, то есть p1 = р2 = ... = рq = 1/q, и статистически независимы. Тогда количество информации в сообщении длиной n букв с учетом выражения (1.4)
 (1.14)
(1.14)
что совпадает с мерой Хартли в соответствии с выражениями (1.11) и (1.12).
Согласно Шеннону информация — это снятие неопределенности, что понимают следующим образом. До опыта событие (например, появление буквы хi) характеризуют малой начальной вероятностью рн, которой соответствует большая неопределенность. После опыта неопределенность уменьшается, поскольку конечная вероятность рк > рн. Уменьшение неопределенности рассчитывают как разность между начальным IHи конечным IК значениями количества информации.
Например, для рH = 0,1 и рK = 1 получим:
∆I = IH – IK = log  - log
- log 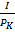 = log 10 – log 1 = 3.32
= log 10 – log 1 = 3.32
Пусть сложное сообщение характеризуется алфавитом из букв х1, х2, ..., хq, их вероятностями р1, р2, .... рq и частотой появления каждой буквы m1, m2, ..., mq. Все сообщения статистически независимы, при этом m1, + m2 + ... + mq = m.
Общее количество информации для всех q типов сообщений с учетом выражения (1.14)

Среднее значение количества информации на одно сообщение (энтропия) согласно формуле Шеннона

где при большом значении m отношение mi/m характеризует вероятность рi каждой буквы. Выражение log1/pi, рассматривают как частную энтропию, которая характеризует информативность буквы xi, а энтропию Н— как среднее значение частных энтропии. При малых значениях pi частная энтропия велика, а с приближением pi, к единице она приближается к нулю (рис. 1.5, а).
Функция η = (Pi) = pi log1/p, отражает вклад буквы хi в энтропию Н. Как видим, при pi = 1 эта функция равна нулю, затем возрастает до своего максимума и при уменьшении рi приближается к нулю. Функция η(pi) при значении pi = 0,37 имеет максимум 0,531.
Интерес представляют сообщения с использованием двухбуквенного алфавита х1 и х2 (например, цифры 0 и 1).
Поскольку при q = 2 вероятность букв алфавита p1 +p2 = 1, то можно положить, что p1 = р и р2 = 1 -р. Тогда энтропию определяют соотношением:
 (1.15)
(1.15)
график которой показан на рис.1.5, б. Он образуется суммированием двух графиков, определяющих энтропию каждой из двух букв. Из графиков видно, что при p = 0 или р = 1 энтропия равна нулю и неопределенность полностью снимается. Это означает, что с вероятностью, равной единице, можно знать, каким будет следующее сообщение.

Энтропия двухбуквенных сообщений достигает максимального значения, равного 1 биту, при р = 0,5, и ее график симметричен относительно этого значения. Это тот случай, когда наиболее трудно предугадать, какое сообщение будет следующим, — то есть ситуация наиболее неопределенная.
В общем случае энтропия обладает следующими свойствами.
1. Энтропия — величина вещественная, непрерывная, ограниченная и неотрицательная.
2. Энтропия равна нулю, если сообщение заранее известно. В этом случае некоторое сообщение задано с вероятностью рi = 1, а вероятность остальных равна нулю.
3. Энтропия максимальна, если все сообщения равновероятны: р1 =р2 = ... = рq = 1/q...
В этом случае на основании выражения (1.15) получим:

что совпадает с выражением (1.3). В этом случае оценки количества информации по Хартли и Шеннону совпадают.
4. При неравных вероятностях количество информации по Шеннону меньше меры Хартли.
5. При объединении энтропии двух независимых источников сообщений их энтропии складываются.
В компьютере наименьшей возможной единицей объемной (геометрической) меры информации является бит. Объем (или емкость) информации вычисляется по количеству двоичных символов 0 и 1, записанных в памяти компьютера. При этом возможно только целое число битов в отличие от вероятностного подхода, где может быть и нецелое число.
Для удобства использования введены также единицы количества информации, превышающие бит. Так, двоичное слово из восьми символов содержит 1 байт информации, 1024 байт составляют килобайт (Кбайт), 1024 Кбайт — мегабайт (Мбайт) и 1024 Мбайт — гигабайт (Гбайт); при этом 1024 = 210
Между объемным и вероятностным количествами информации соотношение неоднозначное. Если сообщение допускает измерение количества информации и объемно и вероятностно, то они не обязательно совпадают. При этом вероятностное количество не может быть больше объемного. В дальнейшем тексте количество информации понимается в объемном значении.
Замечание
Международная система единиц измерения величин СИ (SI) устанавливает специальные приставки для получения кратных и дольных единиц измерения во всех областях науки и техники. Эти приставки имеют полные наименования и сокращенные обозначения и позволяют умножать значение основной единицы на определенную степень числа 10. Для удобства мы будем называть эти приставки десятичными. Приведем наиболее важные десятичные приставки.