Классификация инструментальных средств для работы со знаниями.
Обсуждение технологических аспектов разработки сложных программных систем, проведенное выше, показывает, что наиболее проработанным этапом здесь является реализация программных проектов. По идеям и методам этот этап близок к автоматизации программирования — одной из основных проблем использования средств вычислительной техники. Здесь уже в течение многих лет применяется обширный арсенал языков программирования высокого уровня, ориентированных на удобную и эффективную реализацию различных классов задач, а также широкий спектр трансляторов, обеспечивающих получение качественных исполнительных программ. Все шире используются на современном этапе и методы автоматического синтеза программ. Уже стало обычным применение языково-ориентированных редакторов и специализированных баз данных. И можно сказать, что в рамках технологии программирования уже практически сформировалась концепция окружения разработки сложных программных продуктов, которая и определяет инструментальные средства, доступные разработчикам.
Необходимость использования средств автоматизации программирования прикладных систем, ориентированных на знания, и в частности ЭС, была осознана разработчиками этого класса программного обеспечения ЭВМ уже давно. По существу, средства поддержки разработки интеллектуальных систем в своем развитии прошли основные стадии, характерные для систем автоматизации программирования,
Оценивая данный процесс с сегодняшних позиций, можно указать в этой области две тенденции. Первая из них как бы повторяет «классический» путь развития средств автоматизации программирования: автокоды — языки высокого уровня — языки сверхвысокого уровня — языки спецификаций. Условно эту тенденцию можно назвать восходящей стратегией в области создания средств автоматизации разработки интеллектуальных систем. Вторая тенденция, нисходящая, связывается со специальными средствами, уже изначально ориентированными на определенные классы задач и методов ИИ. В конце концов, обе эти тенденции, взаимно обогатив друг друга, должны привести к созданию мощного и гибкого инструментария интеллектуального программирования. Но для настоящего этапа в этой области, по нашему мнению, характерна концентрация усилий в следующих направлениях:
1. Разработка систем представления знаний (СПЗ) путем прямого использования широко распространенных языков обработки символьной информации и, все чаще, языков программирования общего назначения.
2. Расширение базисных языков ИИ до систем представления знаний за счет специализированных библиотек и пакетов.
3. Создание языков представления знаний (ЯПЗ), специально ориентированных на поддержку определенных формализмов, и реализация соответствующих трансляторов с этих языков.
На начальном этапе развития ИИ языков и систем, ориентированных специально на создание прикладных систем, основанных на знаниях, не существовало. С одной стороны, в то время еще не оформился сам подход, в котором центральное место отводилось бы изложению теории в форме программ, а с другой — сама область ИИ только зарождалась как научное направление. Немаловажным было и то, что появившиеся к тому времени универсальные языки программирования высокого уровня казались адекватным инструментом для создания любых, в том числе и интеллектуальных, систем. Однако сложность и трудоемкость разработки здесь настолько велики, что практически полезные интеллектуальные системы становятся недоступными для реализации. Учитывая вышесказанное, были разработаны языки и системы обработки символьной информации, которые на несколько десятилетий стали основным инструментом программирования интеллектуальных систем.
До недавнего времени наиболее популярным базовым языком реализации систем ИИ вообще и ЭС, в частности, был ЛИСП [McCarthy, 1978]. Ниже кратко рассматривается эволюция ЛИСПа, а затем обсуждаются альтернативы этому языку, существовавшие и существующие в области реализации систем, ориентированных на знания. Результаты этого краткого обзора суммированы в виде схемы развития средств автоматизации программирования интеллектуальных систем на рис. 1.
Как известно, язык ЛИСП был разработан в Стэнфорде под руководством Дж. Маккарти в начале 60-х годов и не предназначался вначале для программирования задач ИИ. Это был язык, который должен был стать следующим за фортраном шагом на пути автоматизации программирования.
По первоначальным замыслам новый язык должен был иметь средства работы с матрицами, указателями и структурами из указателей и т. п. Предполагалось, что первые реализации будут интерпретирующими, но в дальнейшем будут созданы компиляторы. Как отмечает сам автор языка в обзоре [McCarthy, 1978], к счастью, для столь амбициозного проекта не хватило средств. К тому же к моменту создания первых ЛИСП-интерпретаторов в практику работы на ЭВМ стал входить диалоговый режим, и режим интерпретации естественно вписался в общую структуру диалоговой работы.
Примерно тогда же окончательно сформировались и принципы, положенные в основу языка ЛИСП: использование единого спискового представления для программ и данных; применение выражений для определения функций; скобочный синтаксис языка. Процесс разработки языка завершился созданием версии ЛИСП 1.5 [McCarthy, 1978], которая на многие годы определила пути его развития.
На протяжении всего существования языка было много попыток его усовершенствования за счет введения дополнительных базисных примитивов и/или управляющих структур. Однако, как правило, все эти изменения не прививались в качестве самостоятельных языков, так как их создатели оставались в «лисповской» парадигме, не предлагая нового взгляда на программирование.
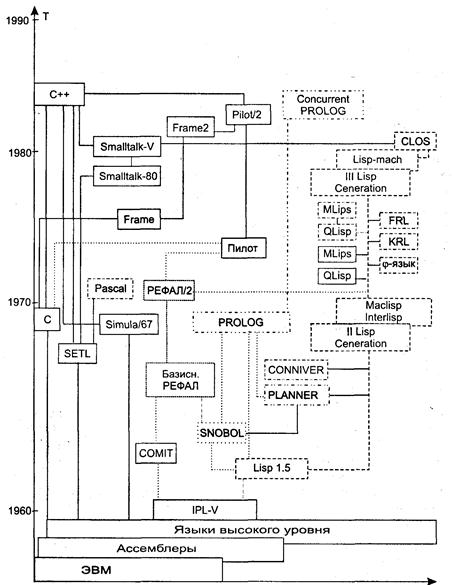
Рис. 1. Эволюция средств представления знаний
После разработки в начале 70-х годов таких мощных ЛИСП-систем, как MacLisp и Interlisp [Moon, 1973; Teitelman, 1974], попытки создания языков ИИ, отличных от ЛИСПа, но на той же парадигме, по-видимому, сходят на нет. И дальнейшее развитие языка идет, с одной стороны, по пути его стандартизации (таковы, например, Standart Lisp, Franz Lisp и Common Lisp), а с другой — в направлении создания концептуально новых языков для представления и манипулирования знаниями, погруженных в ЛИСП-среду [Barr et al., 1982].
К концу 80-х годов ЛИСП был реализован на всех классах ЭВМ, начиная с персональных компьютеров и кончая высокопроизводительными вычислительными системами. Новый толчок развитию ЛИСПа дало создание ЛИСП-машин, которые и в настоящее время выпускаются рядом фирм США, Японии и Западной Европы.
Из предыдущего может сложиться впечатление, что язык ЛИСП (а вернее его современные диалекты) — единственный язык ИИ. В действительности, конечно, это не так. Уже в середине 60-х годов, то есть на этапе становления ЛИСПа, разрабатывались языки, предлагающие другие концептуальные основы. Наиболее важными из них в области обработки символьной информации являются, по нашему мнению, СНОБОЛ [Griswold, 1978], разработанный в лабораториях Белла, и язык РЕФАЛ [Турчин, 1968], созданный в ИПМ АН СССР.
Первый из них (СНОБОЛ) — язык обработки строк, в рамках которого впервые появилась и была реализована в достаточно полной мере концепция поиска по образцу. С позиций сегодняшнего дня можно сказать, что язык СНОБОЛ был одной из первых практических реализации развитой продукционной системы. Наиболее известная и интересная версия этого языка — СНОБОЛ-IV [Грисуолд и др., 1980]. Здесь, на наш взгляд, техника задания образцов и работа с ними существенно опередили потребности практики. Может быть именно это, а также политика активного внедрения ЛИСПа помешали широкому использованию языка СНОБОЛ в области ИИ.
В основу языка РЕФАЛ положено понятие рекурсивной функции, определенной на множестве произвольных символьных выражений. Базовой структурой данных этого языка являются списки, но не односвязные, как в ЛИСПе, а двунаправленные. Обработка символов ближе, как мы бы сказали сегодня, к продукционному формализму. При этом активно используется концепция поиска по образцу, характерная для СНОБОЛа. Таким образом, РЕФАЛ вобрал в себя лучшие черты наиболее интересных языков обработки символьной информации 60-х годов;
В настоящее время можно говорить о языке РЕФАЛ второго [Климов и др., 1987] и даже третьего поколения. Реализован РЕФАЛ на всех основных типах ЭВМ и активно используется для автоматизации построения трансляторов, для построения систем аналитических преобразований, а также, подобно ЛИСПу, в качестве инструментальной среды для реализации языков представления знаний [Хорошевский, 1983].
В начале 70-х годов появился еще один новый язык, способный составить конкуренцию ЛИСПу при реализации систем, ориентированных на знания, — язык ПРОЛОГ [Clocksin et al., 1982]. Он не дает новых сверхмощных средств программирования по сравнению с ЛИСПом, но поддерживает другую модель организации вычислений. Подобно тому, как ЛИСП скрыл от программиста устройство памяти ЭВМ, ПРОЛОГ позволил ему не заботиться (без необходимости) о потоке управления в программе. ПРОЛОГ предлагает такую парадигму мышления, в рамках которой описание решаемой задачи представляется в виде слабо структурированной совокупности отношений. Это удобно, если число отношений не слишком велико и каждое отношение описывается небольшим числом альтернатив. В противном случае ПРОЛОГ-программа становится весьма сложной для понимания и модификации. Возникают и проблемы эффективности реализации языка, так как в общем случае механизмы вывода, встроенные в ПРОЛОГ, обеспечивают поиск решения на основе перебора возможных альтернатив и декларативного возврата из тупиков. ПРОЛОГ разработан в Марсельском университете в 1971 г. [Colmerauer, 1983]. Однако популярность он стал приобретать лишь в начале 80-х годов, когда благодаря усилиям математиков был обоснован логический базис этого языка, а также в силу того, что в японском проекте вычислительных систем V поколения ПРОЛОГ был выбран в качестве базового для машины вывода. В настоящее время ПРОЛОГ завоевал признание и на американском континенте, хотя уступает в популярности ЛИСПу и даже специальным продукционным языкам, широко используемым при создании ЭС.
Мы рассмотрели языки общего назначения для задач ИИ. Вместе с тем в рамках развития средств автоматизации программных систем, ориентированных на знания, были языки, сыгравшие важную роль в эволюции основных языков ИИ. В первую очередь среди них необходимо выделить языки, ориентированные на программирование поисковых задач. Это ПЛЭНЕР и различные его модификации [Пильщиков, 1983], КОННАЙВЕР [Sussman et al., 1976], а также языки, выросшие из потребностей известной планирующей системы QA4 [Sacerdoti et al., 1976]. Все эти языки функционируют в ЛИСП-среде и создавались как расширения базового языка. Для них, кроме свойств ЛИСПа, характерны следующие черты: представление данных в виде произвольных списковых структур; развитые методы сопоставления образцов; поиск с возвратами и вызов процедур по образцу. Заметим, что в конечном счете ни один из них не стал универсальным языком программирования ИИ. Однако выработанные здесь решения были использованы и в ЛИСПе, и в ПРОЛОГе, и в современных продукционных языках. Важно и то, что языки этой группы способствовали переосмыслению самого понятия программы. В области ИИ это послужило толчком к развитию объектно-ориентированного программирования и разработке языков представления знаний первого поколения.
В 70-х годах в программировании вообще и программировании задач ИИ, в частности, центр тяжести стал смещаться от процедурных к декларативным описаниям. К этому же времени в ИИ сформировались и концепции представления знаний на основе семантических сетей и фреймов. Естественно, что появились и специальные языки программирования, ориентированные на поддержку этих концепций. Но из десятков, а может и сотен языков представления знаний (ЯПЗ) первого поколения лишь несколько сыграли заметную роль в программной поддержке систем представления знаний. Среди таких ЯПЗ явно выделяются KRL, FRL, KL-ONE и некоторые другие [Хорошевский, 1990]. Характерными чертами этих ЯПЗ были: двухуровневое представление данных (абстрактная модель предметной области в виде иерархии множеств понятий и конкретная модель ситуации как совокупность взаимосвязанных экземпляров этих понятий); представление связей между понятиями и закономерностей предметной области в виде присоединенных процедур; семантический подход к сопоставлению образцов и поиску по образцу.
Суммируя вышесказанное, можно отметить, что на первом этапе была сформирована значительная коллекция методов представления знаний и соответствующих ЯПЗ. Все это способствовало формированию новой стадии исследований в области ИИ, которая характеризуется переходом от экспериментальной программной проверки идей и методов к созданию практически значимых инструментов.
В силу ограниченного объема книги мы не сможем здесь рассмотреть даже наиболее распространенные языки и системы представления знаний. Поэтому ниже приведены лишь некоторые замечания относительно одного из самых распространенных ЯПЗ — OPS5 (Official Production System, version 5) [Brownston et al., 1985], который претендовал в начале 80-х годов на роль языка-стандарта в области представления знаний для ЭС.
OPS5 — один из многочисленных на сегодняшний день ЯПЗ для ЭС, поддерживающих продукционный подход к представлению знаний. OPS5- прогpaммa, в общем случае, содержит секцию деклараций, где описываются используемые объекты и определяются введенные пользователем функции, и секцию продукций, основу которой составляют правила. OPSS-объекты описываются с помощью фреймов-экземпляров, прототипы которых задаются в виде определенных структур данных, опирающихся на небольшое число встроенных типов. Во время исполнения программы обрабатываемые данные помещаются в рабочую память, а правила — в память продукций. Модуль вывода решений в OPSS-системе состоит из трех основных блоков; отождествления, где осуществляется поиск подходящих правил; выбора исполняемого правила из конфликтного множества правил и собственно исполнителя выбранного правила. Непосредственно в OPS5 поддерживается единственная стратегия вывода решений — вывод, управляемый целями. Вместе с тем OPS5 — достаточно гибкий язык, в котором имеются явные средства не только для описания данных, но и средства определения управления над этими данными.
Анализ формализмов представления знаний и методов вывода решений позволяет сформулировать следующие требования к ЯПЗ:
- наличие простых и вместе с тем достаточно мощных средств представления сложно структурированных и взаимосвязанных объектов;
- возможность отображения описаний объектов на разные виды памяти ЭВМ;
- наличие гибких средств управления выводом, учитывающих необходимость структурирования правил работы решателя;
- «прозрачность» системных механизмов для программиста, предполагающая возможность их доопределения и переопределения на уровне входного языка;
- возможность эффективной реализации.
Конечно, перечисленные требования во многом противоречивы. Но удачные языки и системы представления знаний, как правило, появляются лишь тогда, когда в рамках разумного компромисса учтены все эти требования.
2. Инструментальные пакеты для ИИ
Развитые среды автоматизации программирования на базе языков символьной обработки являются необходимым технологическим уровнем систем поддержки разработки прикладных интеллектуальных систем. Как правило, такие среды покрывают (и то частично) подсистему автоматизации проектирования и программирования. Вот почему следующим этапом в развитии инструментальных средств стала ориентация на среды поддержки разработок интеллектуальных систем.
Анализ существующих инструментальных систем показывает, что сначала в области ИИ более активно велись работы по созданию интеллектуальных систем автоматизированного синтеза исполнительных программ. И это естественно, если иметь в виду, что инструментарий ИИ является, по существу, эволюционным развитием систем автоматизации программирования. При этом основная доля мощности и интеллектуальности такого инструментария связывалась не с его архитектурой, а с функциональными возможностями отдельных компонентов той или иной технологической среды. Большое значение при разработке инструментария для ИИ уделялось и удобству сопряжения отдельных компонентов. Пожалуй, именно здесь были получены впечатляющие результаты и именно здесь наиболее широко использовались последние достижения теории и практики программирования, такие, например, как синтаксически-ориентированное редактирование и инкрементная компиляция. Вместе с тем подавляющее большинство современных инструментальных систем «не знают», что проектирует и реализует с их помощью пользователь. И с этой точки зрения можно сказать, что все такие системы являются не более чем «сундучками» с инструментами, успех использования которых определяется искусством работающего с ними мастера. Примерами подобных сред служит подавляющее большинство инструментальных пакетов и систем-оболочек для создания экспертных систем типа EXSYS [EXSYS, 1985], GURU [MDBS, 1986] и др. [Harmon, 1987]. Однако не они определяют на сегодняшний день уровень достижений в этой области.
К первому эшелону большинство специалистов относит системы ART [ART, 1984], KEE [Florentin, 1987] и Knowledge Craft [CARNEGIE, 1987]. Заметим, что в последнее время в класс самых мощных и развитых систем вошла и среда G2 [CATALYST, 1993]. Все эти системы, во-первых, отличает то, что это, безусловно, интегрированные среды поддержки разработки интеллектуальных (в первую очередь, экспертных) систем. И вместе с тем для этих систем характерно не эклектичное объединение различных полезных блоков, но тщательно сбалансированный их отбор, что позволило сделать первые шаги от автоматизации программирования систем ИИ к технологическим системам поддержки проектирования сначала экспертных, а затем и других интеллектуальных систем.
Остановимся чуть подробнее на двух системах из «большой тройки» ~ ART и KEE, а в заключение кратко охарактеризуем систему G2. Сравнение основывается, главным образом, на работах [Wall et al., 1986; Richer, 1986; Gillmore et al., 1985] и на информации, полученной от дилеров этих систем.
В середине 80-х годов система ART была одной из самых современных интегрированных сред (ИС), поддерживающих технологию проектирования систем, основанных на правилах. В ней существует ясное и богатое разнообразие типов правил. Различные типы правил элегантно вводятся с помощью мощного механизма «точек зрения» (Viewpoint). Этот механизм фактически является очень близким к системе, основанной на истинности предположений (truth maintanance system) [de Kleer, 1989], которая, по-видимому, является развитием идей KEEWorlds+ в системе KEE. По существу, ART является пакетом разработчика. При этом возможные ограничения в использовании ART вызваны не свойствами самой системы, а философией базового метода представления знаний.
ART объединяет два главных формализма представления знаний: правила для процедурных и фреймоподобные структуры для декларативных знаний. Главным является формализм продукционных правил. Декларативные знания описываются через факты и схемы [schemata] и в некоторых случаях через образцы [patterns]. Кроме факторов числовой неопределенности, которые связываются с индивидуальными фактами, в ART различаются факты, которые явно принимаются за ложные, и факты, истинность которых неизвестна. Возможно использование логических зависимостей, которые позволяют изменить факты позже, если обнаружится, что они на самом деле оказались ложными. Механизм Viewpoint допускает образование нескольких конкурирующих миров, где пробуются альтернативные решения.
Схема предусматривается в ART в качестве макроформы для выражения таксономических знаний в структурированном виде, но ни метод, ни активные значения или выход в базовый язык в этом декларативном представлении не допускаются. ART обеспечивает 11 системно-определенных свойств, наследование которых поддерживается системой автоматически. Допускается множественное наследование. Однако средства задания активных значений, указания ограниченней на слот и привязки процедурных знаний к слотам здесь отсутствуют. Таким образом, роль компонента, основанного на фреймах, является чисто описательной. Ограничения и значения по умолчанию могут быть обеспечены в правилах, хотя их было бы легко установить непосредственно с помощью процедурно-ориентированного фреймового формализма. Наследование, определяемое пользователем, не допускается, но тоже может быть смоделировано посредством правил [Wallet, 1986]. Согласно концепции фирмы Inference Corporation это является преимуществом, так как статическое наследование предусматривает мощную прекомпиляцию эффективного кода.
Продукционные знания описываются с помощью правил пяти видов: правила выводов, продукционные правила, гипотетические правила, правила ограничений и правила полаганий. Правила вывода добавляют факты в базу знаний, в то время как продукционные правила изменяют факты в рабочей памяти (например, значение атрибута объекта). Гипотетические правила позволяют в ART использовать возможности формирования гипотез и представляются в следующей , форме: «ЕСЛИ это случилось, ТО рассматривать это как гипотезу». Правила ограничений описывают ситуацию, которая никогда не может появиться при правильной точке зрения на действительность. Правила полаганий используются для предположений (которые принимаются за правильные) о точках зрения (гипотезах). При подтверждении гипотезой некоторого условия она принимается за правильную, объединяется со всеми породившими ее гипотезами и становится новым корнем в древовидной структуре. Другие, несовместимые, гипотезы отбрасываются.
Вызов процедур, определенных пользователем, может быть использован как в левых, так и в правых частях правил ART. Образны (patterns) используются в условной части правил. Они должны быть сопоставлены с фактами рабочей памяти. Образцы могут включать переменные и логические связки, обеспечивающие сочетание фрагментов модели (И, ИЛИ, НЕ, СУЩЕСТВУЕТ, ДЛЯ ВСЕХ).
ART предлагает традиционные модели вывода: «от фактов к цели» и «от цели к фактам». Они могут объединяться в мощный механизм истинности, основанный на предположениях, который допускает аргументацию типа ЧТО ЕСЛИ. Кроме того, в составе ART используются и классические правила типа OPS.
Графическое окружение ART хорошо развито. Интерфейс ARTStudio включает в себя базу знаний с демонстрацией гипотез, утилиты отладчика запускаемых программ, систему подсказок, доступную в любое время, систему меню и графический пакет ARTist (ART linage Syntesis Tool) с оконным редактором. ART предлагает редактор базы знаний, но не дает редактора схем, подобного внутреннему графическому редактору KEE [Wall et al., 1986; Richer, 1986], обсуждаемому ниже. Как указывается в работе [Gillmore et al., 1985], это может стать причиной ошибок при «глубоком» редактировании разрабатываемых баз знаний.
ART позволяет создавать доступные правилам меню и управлять окнами пользовательского интерфейса, а также создавать сами окна. Графические конструкции описываются с помощью схем и ссылаются на правила. Это обеспечивает функционирование по принципу управления обращениями к данным.
ART часто представляют в качестве лучшей ИС для создания экспертных систем, но следует понимать, что хорошо эта среда отвечает лишь всем требованиям подхода поверхностных знаний. Благодаря компилятору правил система вывода в ART является быстрой по своей природе. Главные стратегии структуры управления поиском решений обеспечиваются, и некоторая гибкость в управлении поиском остается инженеру по знаниям. Чисто декларативные таксономические фреймы языка интегрируются с системой правил, но в ART не существует действительно процедурных фреймов, которые могли бы позволить объединить предметные описания с продукционными. В этом отношении объектно-ориентированное программирование с образцами и возможностями моделирования могло бы быть более полезным. Нельзя сказать, что подход, основанный на моделях, не осуществим в ART. Однако кажется, что другие ИС более эффективны для этих целей.
Первые версии ART опирались на язык ЛИСП, последние реализованы непосредственно на С. Это увеличивает эффективность периода исполнения ART. Введены в новые версии и некоторые другие усовершенствования. Они касаются в основном выразительной силы 4юрмализма, основанного на фреймах, и увеличивают адекватность ART по отношению к методу аргументации, основанному на модели. Имеется информация, что в ART включен и объектно-ориентированный подход.
Теперь рассмотрим основные свойства системы КЕЕ и типы задач, которые «подходят» для этой среды. КЕЕ фактически является большим набором хорошо интегрированных ИИ-парадигм. Этот пакет включает продукционные правила, основанный на фреймах язык с наследованиями, логически-ориентированные утверждения, объектно-ориентированные парадигмы с сопутствующими сообщениями и обеспечивает доступ в базовую LISP-систему. Кроме того, КЕЕ предлагает средства для организации и объединения знаний в специфические компоненты и явного структурирования процесса аргументации. Преимущества КЕЕ заключаются также в мощности и дружественности пользовательского интерфейса.
Главное отличие между формализмом представления знаний КЕЕ и ART заключается в способе, которым эти ИС связывают фреймы и правила. КЕЕ является средой, в основе которой лежат фреймы, в то время как в ART — правила. Фреймы в КЕЕ называются элементами (units) и вводятся в более широком смысле, чем в ART. Здесь фреймы могут иметь процедурную роль и дают возможность построения поведенческих моделей объекта и моделей экспертизы. С этой целью к слотам могут привязываться активные значения и методы. Активные значения могут выборочно активизировать системы правил. Таким образом, язык фреймов КЕЕ позволяет представлять поведение независимых сложных компонент в рамках подхода, основанного на модели, что обеспечивает разделение знаний на проблемно-ориентированные фрагменты. При этом каждый компонент знаний может быть активирован по требованию.
Описание объектов и правил в КЕЕ представляется в виде иерархий фреймов. Доступны два основных отношения: классы/подклассы и классы/примеры. Каждый объект представляется слотами; в системе различаются индивидные (собственные) и коллективные слоты. Первые используются для описания атрибутов и свойств класса, рассматриваемого в качестве объекта, а вторые описывают родовые свойства членов класса. Слоты могут иметь различные аспекты, которые, в свою очередь, могут иметь множественные значения. На них могут накладываться ограничения, которые могут использоваться в качестве автоматических утилит для проверки целостности знаний. Этим КЕЕ отличается от ART, где ограничения могут выражаться только с помощью правил. Со слотами могут быть связаны активные значения. Формализм продукционных правил в КЕЕ тоже хорошо разработан. Использование переменных и вызов LISP-функций допускается как в исполняемых, так и в условных частях.
КЕЕ предлагает несколько методик для моделирования рассуждений. Конечно, при этом имеется базовый поисковый механизм, но КЕЕ позволяет также трансформировать неявные знания во фреймы и в решетки наследования, что дает средства для моделирования операций аргументации.
КЕЕ (версия 3.0) обеспечивается системой, основанной на предположении истинности выполнения, называемой KEEWorld. Согласно заявлениям фирмы IntelliCorp, она обеспечивает поддержку 4)ундаментальных методов поиска в пространстве состояний. Мощность КЕЕ проявляется при решении задач, где процесс аргументации может трансформироваться, выполняться и управляться с помощью фреймовых компонент. Решетка наследования фреймов позволяет установить несколько видов зависимостей между объектами. Система снабжена возможностями автоматического восстановления неявной информации. Утверждается, что эта информация может быть представлена фреймами [Fikes et al., 1985]. КЕЕ обеспечена эффективными возможностями восстановления и автоматической проверки информации. Для этой цели существует логический язык TellandAsk, который используется для определений и восстановления фактов в базе знаний КЕЕ.
Пользовательский интерфейс КЕЕ очень гибкий и тщательно проработанный. Он включает мощный редактор, программу просмотра базы знаний, поясняющие сообщения и т. д. Известно, что он превосходит по мощности интерфейс ART [Wall et al., 1986; Richer, 1986]. КЕЕ обеспечивает пользователя графическими средствами KEEpictiires и Activelmages для построения графических представлений. Последние могут быть привязаны к фреймовым слотам, и тогда изменение значения слота приводит к изменению «картинки».
Следует отметить и недавнюю эволюцию системы. КЕЕ 2.1 не имел гипотетической системы или системы, основанной на предположении об истинности выполнения. В КЕЕ 3.0 эти новые возможности доступны. А его открытая архитектура является важным фактором в процессе настройки и расширения, так как части КЕЕ написаны в самом КЕЕ. С одной стороны, это полезно для подтверждения гибкости КЕЕ и способности к развитию. С другой — это может привести к неэффективности исполняющей системы. Дополнительно фирма IntelliCorp уже разработала пакет специализированных программ для КЕЕ. Одна из таких программ — SIMKIT. Она спроектирована для поддержки моделирования в КЕЕ.
Таким образом, КЕЕ является развитой системой, основанной на фреймах, где хорошо сбалансированы формализмы представления как декларативных, так и процедурных знаний. Доступны в системе и методы явного управления и структурирования процесса аргументации. Благодаря этому КЕЕ является подходящим для решения задач в рамках подхода, основанного на модели. Важнейшими при разработке интеллектуальных прикладных систем являются вопросы формирования и отладки баз знаний. Но здесь КЕЕ, ART и многие другие инструментальные пакеты, к сожалению, идут по пути обычных систем автоматизации программирования. Пользователю предоставляется мощный графический редактор правил, используемый для начального ввода продукций и коррекции их в процессе отладки, и средства графической трассировки вывода решений, которые должны позволить инженеру знаний ориентироваться во взаимодействии сотен и тысяч правил.
Инструментальная среда G2 — разработка фирмы Gensym Corp. — является развитием известной экспертной системы реального времени PICON. По утверждению официального дилера этой фирмы в России Э. В. Попова, G2 является самой мощной из сред для систем реального времени среди всех инструментов данного класса. Система G2 реализована на всех основных вычислительных платформах, включая рабочие станции Sun, HP9000, RS/6000 и ПЭВМ, работающие под управлением Windows NT. Возможна работа с системой в режиме клиент—сервер в сети Ethernet.
Основные функциональные возможости G2 связаны с поддержкой процессов слежения за множеством (порядка тысяч) одновременно изменяющихся параметров и обработкой изменений в режиме реального времени; проверкой нештатных ситуаций на управляемых объектах и принятием решений как в режиме ассистиро-вания оператору, так и в автоматическом режиме. Функциональные возможности системы обеспечиваются быстрым выполнением распараллеливающихся операций, доступными в режиме on-line данными, блоками темпорального выво-. да (включая ссылки на прошлое поведение и поведение управляемого объекта во времени, интеграцию с подсистемами динамического моделирования и процедурными знаниями о времени), специальной техникой вывода решений в режиме реального времени (включая стандартные forward и backward рассуждения, а также event-driven выводы, сканирование датчиков для определения ситуаций, требующих немедленного вмешательства в процесс управления, механизмы фокуси-рования на определенном подмножестве знаний с использованием метазнаний и мощной подсистемой real-time truth maintenance). Все это дает возможность прикладным системам, разработанным с использованием G2, поддерживать на RISC-архитектурах обработку 1000 правил/с реального уровня сложности. Указанные параметры производят серьезное впечатление, и, хотя доступной технической информации по системе G2 явно недостаточно для окончательных выводов о ее применимости во всем спектре заявленных приложений, можно предположить, что система G2 действительно была одной из первых инструментальных сред, поддерживающих разработку интегрированных интеллектуальных систем.
В заключение настоящего параграфа остановимся на первых попытках интеллектуализации инструментальных средств. Следует сразу сказать, что здесь достаточно четко просматриваются два направления: снизу(применение методов ИИ для разработки программного обеспечения) и сверху (переход к системам поддержки разработки баз знаний, основывающихся, в свою очередь, на метазнаниях).
Результаты, полученные с использованием методов ИИ в различных областях человеческой деятельности, привели разработчиков МО к идее использования интеллектуальных систем в программировании. Проект «Ассистент программиста» в Массачусетском технологическом институте и проект «Пси» в Стэнфордском университете были первыми шагами в этом направлении [Waters, 1985; Green, 1977], В этих проектах предпринимались попытки промоделировать знания программиста, используемые для понимания, проектирования, реализации и сопровождения ПО. Предполагалось, что эти знания могут быть использованы, например, экспертной системой для частичной автоматизации процесса разработки ПО, однако существенных результатов в этой части, по-видимому, получено не было.
Методы ИИ могут значительно увеличить мощность существующих инструментальных средств и в области разработки, оценки и проверки требований. Действительно, часто пользователь не знает тех возможностей и особенностей, которые он хотел бы иметь от программной системы, и процесс разработки требований напоминает процесс приобретения знаний. Понятно, что при этом соответствующие инструментальные средства могут использоваться при формировании пользователем своих требований. Вот почему ниже приводится краткий обзор средств приобретения знаний и сопровождения баз знаний, дополняющий аналогичный материал предыдущих глав, но с акцентом на инструментальных компонентах.
Исторически впервые автоматическое извлечение из экспертов конструктов и создание репертуарных решеток, необходимых для построения поля знаний [Гав-рилова и др., 1988], было реализовано в системе PLANET [Shaw, 1982; Shaw et al., 1984J. Ряд алгоритмов и программ PLANET был впоследствии использован при создании системы ETS [Boose, 1985a; Boose, 19850; Boose, 1985с; Boose, 1986], обеспечивающей не только автоматическое создание репертуарной решетки, но и преобразование ее в традиционные для ЭС формы представления БЗ. Потомками ETS являются система NeoETS [Boose et al., 1986] и интегрированная среда для извлечения экспертных знаний AQUINAS [Boose et al., 1987]. Дальнейшим развитием системы PLANET является интегрированная среда KITTEN [Gaines et al., 1986; Gaines et al., 1987], поддерживающая ряд методов извлечения знаний.
Перечисленные выше системы поддержки процессов приобретения знаний, как правило, ориентированы на отдельные фазы всего технологического цикла. Одной из методологий, ориентированных на «интегрированные» средства поддержки разработки, справедливо считается KADS, рассмотренная ранее. В этой системе сделана, пожалуй, первая попытка объединения достижений «классической» технологии программирования и методов ИИ.
Программные агенты и мультиагентные системы
Проблематика интеллектуальных агентов и мультиагентных систем (MAC) имеет уже почти 40-летнюю историю [Городецкий и др., 1998; Тарасов, 1998] и сформировалась на основе результатов, полученных в рамках работ по распределенному искусственному интеллекту (DAI), распределенному решению задач (DPS) и параллельному искусственному интеллекту (PAI) [Demazeau et al., 1990; Пэра-нек, 1991; Rasmussen et al., 1991]. Но, пожалуй, лишь в последнее 10-летие она выделилась в самостоятельную область исследований и приложений и все . больше претендует па одну из ведущих ролей в рамках интеллектуальных информационных технологий. Спектр работ по данной тематике весьма широк, интегрирует достижения в области компьютерных сетей и открытых систем, искусственного интеллекта и информационных технологий и ряда других исследований, а результаты уже сегодня позволяют говорить о новом качестве получаемых решений.
Понятно, что в рамках данного издания мы не сможем даже обозреть все направления и результаты в области MAC. Поэтому далее сконцентрируемся лишь на тех разделах, которые имеют непосредственное отношение к теме настоящей книги. С учетом сделанных замечаний и с позиций сегодняшнего дня все исследования в этой области можно выделить в две основные фазы: первая охватывает период с 1977 г. по настоящее время, а вторая — с начала 1990 г. по настоящее время.
Работы первого периода концентрировались на исследовании так называемых «смышленых» (smart) агентов, которые были начаты в конце 1970-х годов и продолжаются все 1980-е годы вплоть до наших дней. Первоначально эти работы были сосредоточены на анализе принципов взаимодействия между агентами, на декомпозиции решаемых задач на подзадачи и распределении полученных задач между отдельными агентами, координации и кооперации агентов, разрешении конфликтов путем переговоров и т. п. Цель таких работ — анализ, спецификация, проектирование и реализация систем агентов. На этом же уровне активно велись работы по теории, архитектурам и языкам для программной реализации агентов. Примерно с 1990 г. стало ясно, что программные агенты могут использоваться в широком спектре применении. Однако потенциал агентных технологий, по-видимому, стал в значительной мере осознан не только разработчиками, но и инвесторами после известного отчета консультативной фирмы Ovum [Ovum, 1994], которая предсказала, что сектор рынка для программных агентов в США и Европе вырастет, по крайней мере, до $3,9 billion к 2000 г. в противовес 1995 г., когда он оценивался в $476 million.
В настоящее время множество исследовательских лабораторий, университетов, фирм и промышленных организаций работают в этой области, и список их постоянно расширяется. Он включает мало известные имена и небольшие коллективы, уже признанные исследовательские центры и организации (например, университет Карнеги Мэллон (CMU) и 4'ирма General Magic), а также огромные транснациональные компании (такие как Apple, AT&T, ВТ, Daimler-Benz, DEC; PIP, IBM, Lotus, Microsoft, Oracle, Sharp и др.). Областями практического использования агентных технологий являются управление информационными потоками (workflow management) и сетями (network management), управление воздушным движением (air-traffic control), информационный поиск (information retrieval), электронная коммерция (e-commerce), обучение (education), электронные библиотеки (digital libraries) и многие-многие другие приложения.
Существует несколько причин, почему необходимы и полезны программные агенты, MAC и, более общо, агентные технологии. Основная из них в том, что агенты автономны и могут выполняться в фоновом (background) режиме от лица пользователя при решении разных задач, наиболее важными из которых являются сбор информации, ее фильтрация и использование для принятия решений. Таким образом, основная идея программных агентов — делегирование полномочий. Для того чтобы реализовать эту идею, агент должен иметь возможность взаимодействия со своим владельцем или пользователем для получения соответствующих заданий и возвращения полученных результатов, ориентироваться в среде своего выполнения и принимать решения, необходимые для выполнения поставленных перед ним задач.
К построению агентно-ориентированиых систем можно указать два подхода: реализация единственного автономного агента или разработка мультнагептной системы. Автономный агент взаимодействует только с пользователем и реализует весь спектр функциональных возможностей, необходимых в рамках агентно-ориентированной программы. В противовес этому MAC являются программно-вычислительными комплексами, где взаимодействуют различные агенты для решения задач, которые трудны или недоступны в силу своей сложности для одного агента. Часто такие мультиагентные системы называют агентствами (agencies), в рамках которых агенты общаются, кооперируются и договариваются между собой для поиска решения поставленной перед ними задачи.
Агентные технологии обычно предполагают использование определенных типологий агентов и их моделей, архитектур MAC и опираются на соответствующие агентные библиотеки и средства поддержки разработки разных типов мульти-агентных систем.
Основные понятия
Существует несколько подходов к определению понятий в данной предметной области. По-видимому, одним из наиболее последовательных в этом вопросе является международная ассоциация FIPA (Foundation for Intelligent Physical Agents), каждый документ которой содержит толковый словарь терминов, релевантных данному документу [FIPA, 1998]. И вместе с разными исследователями, представлен в работе [Franklin et al., 1996]. В настоящем издании будем придерживаться следующей концепции по этому поводу. |
Агент — это аппаратная или программная сущность, способная действовать в интересах достижения целей, поставленных перед ним владельцем и/или пользователем [Wool-dridgeetal., 1995].
Таким образом, в рамках МАС-парадигмы программные агенты рассматриваются как автономные компоненты, действующие от лица пользователя.
Как следует из приведенной таблицы, собственно целесообразное поведение появляется только на уровне интеллектуальных агентов [Пономарева и др., 1999; Хорошевский, 1999]. И это не случайно, так как для него необходимо не только наличие целей функционирования, но и возможность использования достаточно сложных знаний о среде, партнерах и о себе. С точки зрения целей настоящей Книги, наибольший интерес представляют интеллектуальные и действительно интеллектуальные (см. табл. 9.1) агенты. Понятно, что все характеристики более «простых» типов агентов при этом наследуются.
Иногда агентов определяют через свойства, которыми они должны обладать. Учитывая то, что нас, в первую очередь, интересуют интеллектуальные агенты, приведем типовой список свойств, которыми такие агенты должны обладать [Wooldridge et al., 1995; FIPA, 1998]:
автономность (autonomy, autonomious теМ йрактичесИ! ВО BG@X работах, где даются, например, определения понятия агента и его базисных свойств, общим местом стало замечание об отсутствии единого мнения по этому поводу [Franklin et al., 1996; Belgrave, 1996; Nwana, 1996]. Фактически, используя понятие «агент», каждый автор или сообщество определяют своего агента с конкретным набором свойств в зависимости от целей разработки, решаемых задач, техники реализации и т. п. критериев. Как следствие, в рамках данного направления появилось множество типов агентов, например: автономные агенты, мобильные агенты, персональные ассистенты, интеллектуальные агенты, социальные агенты и т. д. [Nwana, 1996], а вместо единственного определения базового агента — множество определений производных типов.
Учитывая вышесказанное, понятие агента целесообразно трактовать как мета-имя или класс, который включает множество подклассов. Ряд определений агентов, данных
· functioning) — способность функционировать без вмешательства со стороны своего владельца и осуществлять контроль внутреннего состояния и своих действий;
· социальное поведение (social ability, social behaviour) — возможность взаимодействия и коммуникации с другими агентами;
· реактивность (reactivity) — адекватное восприятие среды и соответствующие реакции на ее изменения;
· активность (pro-activity) — способностьгенерировать цели и действовать рациональным образом для их достижения;
· базовые знания (basic knowledge) — знания агента о себе, окружающей среде, включая других агентов, которые не меняются в рамках жизненного цикла агента;
· убеждения (beliefs) — переменная часть базовых знаний, которые могут меняться во времени, хотя агент может об этом не знать и продолжать их использовать для своих целей;
· цели (goals) — совокупность состояний, на достижение которых направлено текущее поведение агента;
· желания (desires) — состояния и/или ситуации, достижение которых для агента важно;
· обязательства (commitments) — задачи, которые берет на себя агент по просьбе и/или поручению других агентов;
· намерения (intentions) — то, что агент должен делать в силу своих обязательств и/или желаний.
Иногда в этот же перечень добавляются и такие свойства, как рациональность (retionality), правдивость (veracity), благожелательность (benevolence), а также мобильность (mobility), хотя последнее характерно не только для интеллектуальных агентов.
В зависимости от концепции, выбранной для организации MAC, обычно выделяются три базовых класса архитектур [Wray et al., 1994; Wooldridge et. al., 1995; Nwana, 1996]:
· архитектуры, которые базируются на принципах и методах работы со знаниями (deliberative agent architectures);
· архитектуры, основанные на поведенческих моделях типа «стимул-реакция»
· (reactive agent architectures);
· гибридные архитектуры (hybrid architectures).
Наиболее «трудными» терминологически в этой триаде являются архитектуры первого типа. Прямая калька — делиберативные архитектуры — неудобна для русскоязычного произношения и не имеет нужной семантической окраски для русскоязычного читателя. Сам термин был введен в работе [Genesereth et al., 1987] при обсуждении архитектур агентов.
Архитектуру или агентов, котореля. Сам термин был введен в работе [Genesereth et al., 1987] при обсуждении архитектур агентов.
Архитектуру или агентов, которые используют только точное представление картины мира в символьной форме, а решения при этом (например, о действиях) принимаются на основе формальных рассуждений и использования методов сравнения по образцу, принято определять как делиберативные.
Таким образом, в данном случае мы имеем дело с «разумными» агентами и архитектурами, имеющими в качестве основы проектирования и реализации модели, методы и средства искусственного интеллекта. В работе [Тарасов, 1998] таких агентов предлагается называть когнитивными, что не вполне правильно, так как при этом неявно предполагается, что «рассуждающие» агенты познают мир, в котором они 4)ункционируют. Нам представляется, что для русского языка более удобным и адекватным были бы термины «агент, базирующийся на знаниях» или «интеллектуальный агент», а также «архитектура интеллектуальных агентов». Именно этих терминов мы и будем придерживаться в данном издании. Первоначально идея интеллектуальных агентов связывалась практически полностью с классической логической парадигмой ИИ. Однако по мере развития исследований в этой области стало ясно, что такие «ментальные» свойства агентов, как, например, убеждения, желания, намерения, обязательства по отношению к другим агентам и т. п., невыразимы в терминах исчисления предикатов первого порядка. Поэтому для представления знаний агентов в рамках данной архитектуры были использованы специальные расширения соответствующих логических исчислений [.Поспелов, 1998], а также разработаны новые архитектуры, в частности архитектуры типа BDI (Belief-Desire-Intention). Один из конкретных примеров архитектуры этого класса обсуждается ниже.
Принципы реактивной архитектуры возникли как альтернативный подход к архитектуре интеллектуальных агентов. Идея реактивных агентов впервые возникла в работах Брукса, выдвинувшего тезис, что интеллектуальное поведение может быть реализовано без символьного представления знаний, принятого в классическом ИИ [Brooks, 1991]. Таким образом [Connah, 1994]:
Реактивными называются агенты и архитектуры, где нет эксплицитно представленной модели мира, а функционирование отдельных агентов и всей системы осуществляется по правилам типа ситуация—действие. При этом под ситуацией понимается потенциально сложная комбинация внутренних и внешних состояний.
Вообще говоря, данный подход ведет свое начало с работ по планированию поведения роботов, которые активно велись в ИИ в 70-х годах. Простым примером реализации реактивных архитектур в этом контексте можно считать системы, где реакции агентов на внешние события генерируются соответствующими конечными автоматами. Широко известным примером системы с реактивной архитектурой является планирующая система STRIPS [Fikes, 1971], где использовался логический подход, расширенный за счет ассоциированных с действиями предусловий и пост-условий. Позже в рамках реактивных архитектур были разработаны и другие системы, но, как правило, они не могли справиться с задачами реального уровня сложности.
Учитывая вышесказанное, многие исследователи считают, что ни первый, ни второй подходы не дают оптимального результата при разработке агентов и MAC [Wray et al., 1994]. Поэтому попытки их объединения предпринимаются постоянно и уже привели к появлению разнообразных гибридных архитектур. По сути дела, именно гибридные архитектуры и используются в настоящее время во всех, сколько-нибудь значимых проектах и системах.
Мы рассмотрели основные подходы к разработке мультиагентных систем. Архитектуры MAC и их характеристики, широко используемые в настоящее время, представлены в табл.
Таблица. Архитектуры MAC и их характеристики