Вычисление 16-байтовой контрольной суммы
For j = 0 to 15
С[j] = 0
For i = 0 to N/16
For j = 0 to 15
С[j] = S[ С[j] xor M[i*16+j] ]
Массив S (псевдослучайные числа на основе числа пи):
41, 46, 67, 201, 162, 216, 124, 1, 61, 54, 84, 161, 236, 240, 6, 19, 98, 167, 5, 243, 192, 199, 115, 140, 152, 147, 43, 217, 188, 76, 130, 202,
30, 155, 87, 60, 253, 212, 224, 22, 103, 66, 111, 24, 138, 23, 229, 18, 190, 78, 196, 214, 218, 158, 222, 73, 160, 251, 245, 142, 187, 47, 238, 122,
169, 104, 121, 145, 21, 178, 7, 63, 148, 194, 16, 137, 11, 34, 95, 33,
128, 127, 93, 154, 90, 144, 50, 39, 53, 62, 204, 231, 191, 247, 151, 3,
255, 25, 48, 179, 72, 165, 181, 209, 215, 94, 146, 42, 172, 86, 170, 198,
79, 184, 56, 210, 150, 164, 125, 182, 118, 252, 107, 226, 156, 116, 4, 241,
69, 157, 112, 89, 100, 113, 135, 32, 134, 91, 207, 101, 230, 45, 168, 2,
27, 96, 37, 173, 174, 176, 185, 246, 28, 70, 97, 105, 52, 64, 126, 15,
85, 71, 163, 35, 221, 81, 175, 58, 195, 92, 249, 206, 186, 197, 234, 38,
44, 83, 13, 110, 133, 40, 132, 9, 211, 223, 205, 244, 65, 129, 77, 82,
106, 220, 55, 200, 108, 193, 171, 250, 36, 225, 123, 8, 12, 189, 177, 74,
120, 136, 149, 139, 227, 99, 232, 109, 233, 203, 213, 254, 59, 0, 29, 57,
242, 239, 183, 14, 102, 88, 208, 228, 166, 119, 114, 248, 235, 117, 75, 10,
49, 68, 80, 180, 143, 237, 31, 26, 219, 153, 141, 51, 159, 17, 131, 20;
Хотя в MD2 не было найдено слабых мест, она работает медленнее большинства других предлагаемых хэш-функций.
MD4
Алгоритм MD4 является разработкой Рона Ривеста. Первоначально данный алгоритм был опубликован в октябре 1990 г., незначительно измененная версия была опубликована в RFC 1320 в апреле 1992 г. Кратко рассмотрим основные цели MD4:
некоторые архитектуры процессоров (такие как линия Intel 80xxx) хранят левые байты слова в позиции младших адресов байта (little-endian). Другие (такие как SUN Sparcstation) хранят правые байты слова в позиции младших адресов байта (big endian). Это различие важно, когда сообщение трактуется как последовательность 32-битовых слов, потому что эти архитектуры имеют инверсное представление байтов в каждом слове. Ривест выбрал использование схемы little-endian для интерпретации сообщения в качестве последовательности 32-битных слов. Этот выбор сделан потому, что big-endian процессоры обычно являются более быстрыми.
MD5 является более сложным и, следовательно, более медленным при выполнении, чем MD4. Главные различия между этими двумя алгоритмами состоят в следующем:
1. MD4 использует три цикла из 16 шагов каждый, в то время как MD5 использует четыре цикла из 16 шагов каждый.
2. В MD4 дополнительная константа в первом цикле не применяется. Аналогичная дополнительная константа используется для каждого из шагов во втором цикле. Другая дополнительная константа используется для каждого из шагов в третьем цикле. В MD5 различные дополнительные константы, Т[ i ], применяются для каждого из 64 шагов.
3. MD5 использует четыре элементарные логические функции, по одной на каждом цикле, по сравнению с тремя в MD4, по одной на каждом цикле.
4. В MD5 на каждом шаге текущий результат складывается с результатом предыдущего шага. Например, результатом первого шага является измененное слово А. Результат второго шага хранится в D и образуется добавлением А к циклически сдвинутому влево на определенное число бит результату элементарной функции. Аналогично, результат третьего шага хранится в С и образуется добавлением D к циклически сдвинутому влево результату элементарной функции. MD4 это последнее сложение не включает.
MD5
MD5 (RFC 1321) разработан Роном Ривестом из MIT.
Алгоритм получает на входе сообщение произвольной длины и создает в качестве выхода дайджест сообщения длиной 128 бит. Алгоритм состоит из следующих шагов:

Рис. 1. Логика выполнения MD5
Шаг 1: добавление недостающих битов
Сообщение дополняется таким образом, чтобы его длина стала равна 448 по модулю 512 (длина mod 512 = 448). Это означает, что длина добавленного сообщения на 64 бита меньше, чем число, кратное 512. Добавление производится всегда, даже если сообщение имеет нужную длину. Например, если длина сообщения 448 битов, оно дополняется 512 битами до 960 битов. Таким образом, число добавляемых битов находится в диапазоне от 1 до 512.
Добавление состоит из единицы, за которой следует необходимое количество нулей.
Шаг 2: добавление длины
64-битное представление длины исходного (до добавления) сообщения в битах присоединяется к результату первого шага. Если первоначальная длина больше, чем 264, то используются только последние 64 бита. Таким образом, поле содержит длину исходного сообщения по модулю 264.
В результате первых двух шагов создается сообщение, длина которого кратна 512 битам. Это расширенное сообщение представляется как последовательность 512-битных блоков Y0, Y1, . . ., YL-1, при этом общая длина расширенного сообщения равна L * 512 битам. Таким образом, длина полученного расширенного сообщения кратна шестнадцати 32-битным словам.

Рис. 2. Структура расширенного сообщения
Шаг 3: инициализация MD-буфера
Используется 128-битный буфер для хранения промежуточных и окончательных результатов хэш-функции. Буфер может быть представлен как четыре 32-битных регистра (A, B, C, D). Эти регистры инициализируются следующими шестнадцатеричными числами:
А = 01234567
В = 89ABCDEF
C = FEDCBA98
D = 76543210
Шаг 4: обработка последовательности 512-битных (16-словных) блоков
Основой алгоритма является модуль, состоящий из четырех циклических обработок, обозначенный как HMD5. Четыре цикла имеют похожую структуру, но каждый цикл использует свою элементарную логическую функцию, обозначаемую fF, fG, fH и fI соответственно.

Рис. 3. Обработка очередного 512-битного блока
Каждый цикл принимает в качестве входа текущий 512-битный блок Yq, обрабатывающийся в данный момент, и 128-битное значение буфера ABCD, которое является промежуточным значением дайджеста, и изменяет содержимое этого буфера. Каждый цикл также использует четвертую часть 64-элементной таблицы T[1 ... 64], построенной на основе функции sin. i-ый элемент Т, обозначаемый T[i], имеет значение, равное целой части от 232 * abs (sin (i)), i задано в радианах. Так как abs (sin (i)) является числом между 0 и 1, каждый элемент Т является целым, которое может быть представлено 32 битами. Таблица обеспечивает "случайный" набор 32-битных значений, которые должны ликвидировать любую регулярность во входных данных.
Для получения MDq+1 выход четырех циклов складывается по модулю 232 с MDq. Сложение выполняется независимо для каждого из четырех слов в буфере.
Шаг 5: выход
После обработки всех L 512-битных блоков выходом L-ой стадии является 128-битный дайджест сообщения.
Рассмотрим более детально логику каждого из четырех циклов выполнения одного 512-битного блока. Каждый цикл состоит из 16 шагов, оперирующих с буфером ABCD. Каждый шаг можно представить в виде:
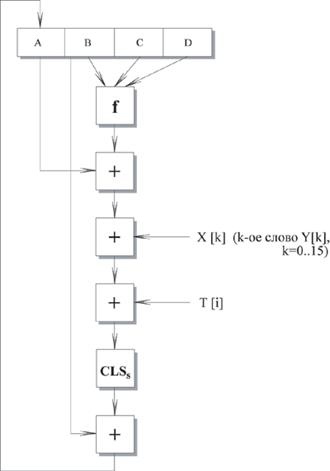
Рис. 4. Логика выполнения отдельного шага
A  B + CLSs (A + f (B, C, D) + X [k] + T [i])
B + CLSs (A + f (B, C, D) + X [k] + T [i])
где
A, B, C, D - четыре слова буфера; после выполнения каждого отдельного шага происходит циклический сдвиг влево на одно слово.
f - одна из элементарных функций fF, fG, fH, fI.
CLSs - циклический сдвиг влево на s битов 32-битного аргумента.
X [k] - M [q * 16 + k] - k-ое 32-битное слово в q-ом 512 блоке сообщения.
T [i] - i-ое 32-битное слово в матрице Т.
+ - сложение по модулю 232.
На каждом из четырех циклов алгоритма используется одна из четырех элементарных логических функций. Каждая элементарная функция получает три 32-битных слова на входе и на выходе создает одно 32-битное слово. Каждая функция является множеством побитовых логических операций, т.е. n-ый бит выхода является функцией от n-ого бита трех входов. Элементарные функции следующие:
fF = (B & C) V (not B & D)
fG = (B & D) V (C & not D)
fH = B Å C Å D
fI = C Å (B & not D)
Массив из 32-битных слов X [0..15] содержит значение текущего 512-битного входного блока, который обрабатывается в настоящий момент. Каждый цикл выполняется 16 раз, а так как каждый блок входного сообщения обрабатывается в четырех циклах, то каждый блок входного сообщения обрабатывается по схеме, показанной на Рис. 4, 64 раза. Если представить входной 512-битный блок в виде шестнадцати 32-битный слов, то каждое входное 32-битное слово используется четыре раза, по одному разу в каждом цикле, и каждый элемент таблицы Т, состоящей из 64 32-битных слов, используется только один раз. После каждого шага цикла происходит циклический сдвиг влево четырех слов A, B, C и D. На каждом шаге изменяется только одно из четырех слов буфера ABCD. Следовательно, каждое слово буфера изменяется 16 раз, и затем 17-ый раз в конце для получения окончательного выхода данного блока.
Можно суммировать алгоритм MD5 следующим образом:
MD0 = IV
MDq+1 = MDq + fI [ Yq, fH [ Yq, f G [Yq, fF [Yq, MDq ] ] ] ]
MD = MDL-1
Где
IV - начальное значение буфера ABCD, определенное на шаге 3.
Yq - q-ый 512-битный блок сообщения.
L - число блоков в сообщении (включая поля дополнения и длины).
MD - окончательное значение дайджеста сообщения.
SHA-1
Безопасный хэш-алгоритм (Secure Hash Algorithm) был разработан национальным институтом стандартов и технологии (NIST) и опубликован в качестве федерального информационного стандарта (FIPS PUB 180) в 1993 году. SHA-1, как и MD5, основан на алгоритме MD4.
Алгоритм получает на входе сообщение длиной до 264 бит и создает на выходе дайджест сообщения длиной 160 бит.
Алгоритм состоит из следующих шагов: