Метод синтеза
Метод синтеза, в отличие от декомпозиции, дает сразу весь набор результирующих декомпозиционных подсхем. Ниже изложен алгоритм синтеза, основанный на идеях Ислура и усовершенствованный Мейером [4] и Дьяковым [6].
Исходными данными для работы алгоритма являются множество атрибутов U и множество функциональных зависимостей F, определенное на U. Результатом работы алгоритма является схема БД в виде набора декомпозиционных подсхем БД = {R1, R2, . . . , RP}, удовлетворяющих следующим условиям.
1. Будем рассматривать такую структуру зависимостей из F+, которые применимы к декомпозиционным подсхемам, и в левой части каждой зависимости находится ключ подсхемы RI . То есть осуществляем переход от множества F к эквивалентному множеству G:
F º G, где G = {KI ®RI ½ RI Í БД , KI – ключ RI}.
Это автоматически по условию достаточности (см. раздел 1.8.2.2) обеспечивает декомпозиции {R1, R2, . . . , RP} выполнимость свойства сохранения функциональных зависимостей.
2. Каждая подсхема RI Í БД должна находиться хотя бы в 3НФ относительно множества функциональных зависимостей F и соответственно G, а может быть и в НФБК, что легко проверить, используя множество G.
3. Синтезируемая БД содержит минимальный набор декомпозиционных подсхем RI, где I = 1, . . . , P. Это условие защищает БД от избыточности.
4. Для любого экземпляра r(БД), удовлетворяющего F, выполняется соотношение
r = pR1 ( r)  . . . pRP ( r). Это условие гарантирует выполнимость свойства соединения без потерь информации.
. . . pRP ( r). Это условие гарантирует выполнимость свойства соединения без потерь информации.
Схема БД, удовлетворяющая условиям 1, 2 и 3 называется полной схемой БД.
Рассматриваемый алгоритм состоит из восьми шагов. На самом деле некоторые шаги можно опустить, о чем будет сказано ниже.
Пример 33. Опишем алгоритм синтеза на простом примере данных из предметной области ПОСТАВКА_ДЕТАЛЕЙ. Однако будем использовать более полный набор атрибутов, чем в методе декомпозиции.
Исходные данные для работы алгоритма:
U = PN, PIM, ST, GOR, DN, DIM, CENA, KOL
Здесь PIM – имя поставщика, DIM – название детали, CENA – цена детали. Остальные атрибуты такие же, как в методе декомпозиции.
На заданном множестве атрибутов, очевидно, будут справедливы зависимости:
F = {PN ® ST, PN ® PIM, PN ® GOR, GOR ® ST, DN ® DIM, DN ® CENA,
(PN, DN) ® KOL}.
Результат работы алгоритма: БД (R1, R2, …, RP).
Шаг 1. Строим расширенное множество зависимостей ℱ по правилу (см. раздел 1.7.1): ℱ= {(Xi ® Ỹi) ç(Xi ® Yi) Î F, Ỹi =Xi+ \ Xi},
где символ “\” означает операцию вычитания атрибутов.
Этот шаг делается для того, чтобы исключить “лишние” (выводимые из других) зависимости с одинаковыми левыми частями. Расширяем каждую зависимость из F, добавляя в правую часть все зависимые атрибуты.
Расширяем первую зависимость из F:
PN+ = PN, PIM, ST, GOR Þ PN ® PIM, ST, GOR.
Расширяем вторую зависимость из F. Так как левая часть этой зависимости PN (совпадает с левой частью первой зависимости), то и правая часть также будет совпадать (что обозначено многоточием) с правой частью первой расширенной зависимости:
PN+ = . . . . . . . . . . Þ PN ® . . .
Аналогично для третьей зависимости:
PN+ = . . . . . . . . . . Þ PN ® . . .
и так далее:
GOR+ = GOR, ST Þ GOR ® ST;
DN+ = DN, DIM, CENA Þ DN ® DIM, CENA;
DN+ = . . . . . . . . . Þ DN ® . . .;
(PN, DN)+ = PN, DN, PIM, ST, GOR, DIM, CENA, KOL Þ (PN, DN) ® U\(PN, DN).
Тогда расширенное множество зависимостей будет таким
ℱ = {PN ® (PIM, ST, GOR), PN ® . . ., PN ® . . ., GOR ® ST, DN ® (DIM, CENA),
DN ® . . ., (PN, DN) ® U\(PN, DN)}.
Шаг 2. Отбрасывая “лишние” зависимости (с многоточиями в правой части), получим условно или псевдонеизбыточное покрытие расширенного множества зависимостей:
ℱ 0 = (PN ® (PIM, ST, GOR), GOR ® ST, DN ® (DIM, CENA), (PN, DN) ® U\(PN, DN)}
Шаг 3. Если среди оставшихся зависимостей нет зависимости с полным набором атрибутов U, то добавляем тривиальную зависимость U ® Æ(правая часть – пустое множество). Этот шаг делается для того, чтобы гарантированно обеспечить выполнимость свойства соединения без потерь информации для результирующей декомпозиции [6].
В рассматриваемом примере такая зависимость есть (PN, DN) ® U\(PN, DN). Поэтому тривиальную зависимость добавлять не надо.
Шаг 4. Разбиваем оставшиеся зависимости на классы эквивалентности (см. раздел 1.7.3) и в каждом классе оставляем одного представителя.
Это делается с целью минимизации количества результирующих декомпозиционных подсхем (таблиц БД).
В рассматриваемом примере нет эквивалентных зависимостей. Поэтому каждая зависимость является единственным представителем своего класса эквивалентности.
Шаг 5. Преобразуем оставшиеся зависимости к элементарному виду, то есть без лишних атрибутов слева (см. раздел 1.7.2). Этот шаг можно опустить, и, если останутся неэлементарные зависимости, то это обязательно проявится на последующих шагах синтеза, как показано в примере 36.
Шаг 6. Ранжируем оставшиеся зависимости по следующему правилу:
rang (XI ® YI) > rang (XJ ® YJ), если (XI È YI) Ì (XJ È YJ), то есть минимальный ранг имеет зависимость с полным набором атрибутов. Ранги зависимостей указаны в таблице 1.
Таблица 1. Ранги функциональных зависимостей
| X ® Y | X È Y | rang |
| PN ® PIM, ST, GOR | PN, PIM, ST, GOR | |
| GOR ® ST | GOR, ST | |
| DN ® DIM, CENA | DN, DIM, CENA | |
| (PN, DN) ® U\(PN, DN) | U |
Шаг 7. Строим ранжированную диаграмму зависимостей, на которой выполняем операцию транзитивной редукции зависимостей с большим рангом на зависимости с меньшим рангом, которая заключается в следующем [6].
Двигаясь по диаграмме снизу – вверх (от зависимостей с большим рангом к зависимостям с меньшим рангом), для каждой текущей зависимости фиксируем атрибуты ее правой части и исключаем из правых частей всех зависимостей, расположенных выше по цепочке вхождений, те атрибуты, которые содержатся в правой части текущей зависимости. Для тривиальной зависимости исключаем атрибуты из левой части.
Операцию транзитивной редукции можно считать обратной операции расширения функциональных зависимостей. При расширении мы как бы “утяжеляем” правые части зависимости, а при транзитивной редукции – “облегчаем” их.
На рисунке 2 показана диаграмма зависимостей для рассматриваемого примера.

Рисунок 2 – Результат выполнения операции транзитивной редукции на
ранжированной диаграмме зависимостей
Шаг 8. Учитывая на диаграмме не вычеркнутые атрибуты (выделены жирным шрифтом), получаем результирующую декомпозицию в виде четырех отношений (левая часть каждой зависимости на диаграмме определяет первичный ключ соответствующего отношения):
R1 = PN, DN, KOL
R2 = DN, DIM, CENA
R3 = PN, PIM,GOR
R4 = GOR, ST
Легко показать, что все отношения находятся в нормальной форме Бойса-Кодда. Следовательно, полученная база данных состоит из четырех таблиц и также находится в нормальной форме Бойса-Кодда.
Пример 34. Рассмотрим более сложный пример формальных данных.
Пусть U = AEKGINPRSTV и F = {N ® A, NG ® K, NK ® T, NK ® I, K ® R,
NV ® E, NEV ® K, NV ® S, N ® P}
Спроектируем реляционную базу данных методом синтеза.
Шаг 1.Расширяем зависимости из F:
N+ = NAP Þ N ® AP;
NG+ = NGKATIRP Þ NG ® KATIRP;
NK+ = NKATIRP Þ NK ® ATIRP;
NK+ = … Þ NK ® … (зависимость совпадает с предыдущей);
K+ = KR Þ K ® R;
NV+ = NVAEKSPIRT Þ NV ® AEKSPIRT;
NEV+ = NEVAKSPIRT Þ NEV ® AKSPIRT;
NV+ = … Þ NV ® …;
N+ = … Þ N ® …;
Получаем расширенное множество зависимостей:
ℱ = {N ® AP, NG ® KATIRP, NK ® ATIRP, NK ® …, K ® R,
NV ® AEKSPIRT, NEV ® AEKSPIRT, NV ® …, N ® …}
Шаг 2. Отбрасывая одинаковые зависимости (с многоточиями в правой части), получим условно или псевдонеизбыточное множество зависимостей:
ℱ 0 = {N ® AP, NG ® KATIRP, NK ® ATIRP, K ® R,
NV ® AEKSPIRT, NEV ® AKSPIRT}
Шаг 3. Поскольку полученное множество зависимостей не содержит зависимости с полным набором атрибутов, то добавляем тривиальную зависимость U ® Æ. Это делается для того, чтобы результирующая декомпозиция обладала свойством соединения без потерь информации.
Мейер показал [4], что, если некоторая подсхема схемы базы данных R содержит универсальный ключ, или суперключ (не обязательно минимальный), то результирующая декомпозиция будет обладать свойством соединения без потерь информации относительно заданного множества F-зависимостей, и обратно. Как будет продемонстрировано ниже многочисленными примерами, декомпозиционная подсхема, полученная из тривиальной зависимости U ® Æ, всегда содержит суперключ или его часть (как в примере 38). Кроме того, дополнительная подсхема играет еще одну важную роль, а именно, она обеспечивает взаимосвязь подсхем (таблиц базы данных). Таким образом, выполнимость свойства соединения без потерь информации обеспечивается добавлением лишней подсхемы, содержащей, как правило, универсальный ключ.
Однако наличие суперключа является необходимым, но недостаточным условием, то есть наличие суперключа в какой-либо декомпозиционной подсхеме не гарантирует во всех случаях выполнимости свойства соединения без потерь информации. Этот факт подтверждает пример 37. Поэтому рекомендуется всегда проводить дополнительное исследование результирующей декомпозиции, как это сделано в примерах, приведенных ниже.
Шаг 4.Разбиваем оставшиеся зависимости на классы эквивалентности и в каждом классе оставляем одного представителя. Среди оставшихся зависимостей имеется две эквивалентные зависимости, выделенные жирным курсивом. В принципе можно удалить любую из них. Однако предпочтительно удалить ту, которая содержит в левой части больше атрибутов. Это объясняется тем, что каждая зависимость в методе синтеза дает отношение (таблицу), причем слева стоит ключ. Связь по ключу с другой таблицей в схеме данных будет проще, если ключ содержит как можно меньше атрибутов. Поэтому в качестве представителя рассматриваемого класса эквивалентности оставляем зависимость NV ® AEKSPIRT.
Шаг 5. Преобразуем оставшиеся зависимости к элементарному виду, то есть без лишних атрибутов слева. Этот шаг можно опустить. Однако заметим, что все оставшиеся зависимости в рассматриваемом примере являются элементарными.
Шаг 6. Ранжируем оставшиеся зависимости (см. таблицу 2).
Таблица 2. Ранги функциональных зависимостей
| X ® Y | X È Y | rang |
| N ® AP | NAP | |
| NG ® KATIRP | NGKATIRP | |
| NK ® ATIRP | NKATIRP | |
| NV ® AEKSPIRT | NVAEKSPIRT | |
| K ® R | KR | |
| U ® Æ | U |
Шаг 7. Строим ранжированную диаграмму зависимостей, на которой выполняем операцию транзитивной редукции зависимостей с большим рангом на зависимости с меньшим рангом
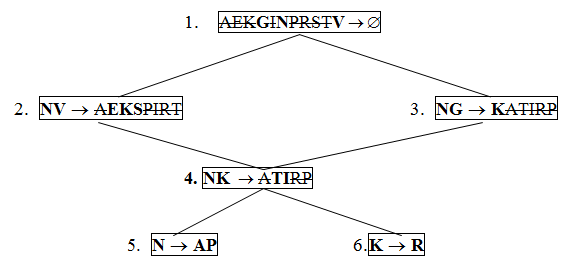
Рисунок 3 – Результат выполнения операции транзитивной редукции на ранжированной диаграмме зависимостей
Шаг 8. Учитывая на диаграмме не вычеркнутые атрибуты (выделены жирным шрифтом), получаем результирующую декомпозицию в виде шести отношений:
R1 = GNV R3 = NGK R5 = NAP
R2 = NVEKS R4 = NKTI R6 = KR
Отметим, что в примере 33 подсхема R1 = PN, DN, KOL содержит суперключ (PN, DN), так как (PN, DN)+ = PN, DN, PIM, ST, GOR, DIM, CENA, KOL = U, а в данном примере подсхема R1 = GNV содержит суперключ, так как
GNV+ = GNVKTIREASP = U.
В примерах 33 и 34 метод синтеза был рассмотрен подробно. В реальных условиях проектирование часто приходится многократно повторять, поскольку сразу все тонкости учесть не всегда возможно. В этом случае можно некоторые шаги алгоритма синтеза опустить, тем самым ускорив проектирование. Кроме того, вместо имен атрибутов удобно использовать их буквенные или числовые обозначения, например, так, как это сделано в таблице 3 примера 35.
Для уменьшения количества атрибутов неключевые атрибуты целесообразно обозначать одной буквой, как это сделано в таблице 3. Тем самым при проектировании можно значительно сократить количество используемых атрибутов, что позволяет выполнить проектирование базы данных вручную даже при большом количестве атрибутов.
Отдельные обозначения следует ввести только для тех неключевых атрибутов, которые участвуют в функциональных связях с другими неключевыми атрибутами, как это сделано в примере 45.
Пример 35. Спроектируем ускоренным синтезом базу данных для предметной области ВСТУПИТЕЛЬНЫЕ ЭКЗАМЕНЫ В ВУЗ.
Исходными данными для проектирования являются множество атрибутов U и множество функциональных зависимостей F, которые справедливы на множестве атрибутов.
Если атрибутов достаточно много, например, больше тридцати, то рекомендуется их искусственно уменьшить, переобозначив и связав их с сущностями, как показано в таблице 3.
Сущностями являются АБИТУРИЕНТЫ, ПРЕПОДАВАТЕЛИ, СПЕЦИАЛЬНОСТИ и ЭКЗАМЕНЫ.
В таблице 3 первичные ключи сущностей выделены.
Таблица 3. Сущности и их атрибуты
| Сущности | Атрибуты сущностей | Первичный ключ | Обозначение |
| АБИТУРИЕНТЫ | НомерАбитур | да | А |
| ФиоАбитур | B | ||
| Адрес | |||
| Телефон | |||
| Льгота | |||
| ПРЕПОДАВАТЕЛИ | НомерПрепод | да | С |
| ФиоПрепод | D | ||
| Должность | |||
| СПЕЦИАЛЬОСТИ | КодСпец | да | E |
| НазваниеСпец | K | ||
| ПроходнойБалл | |||
| ЭКЗАМЕНЫ | НомерЭкзам | да | M |
| Предмет | N | ||
| ДатаЭкзам |
Таким образом, имеем множество атрибутов
U = ABCDEKMN, на котором справедливы зависимости
F = {A → BE, C→ D, E → K, M → N}, так как первичный ключ функционально определяет все атрибуты сущности (см. раздел 1.3.1).
Выполним ускоренный синтез базы данных.
Строим расширенное множество зависимостей
ℱ = {A → BEK, C→ D, E → K, M → N}
Поскольку в расширенном множестве нет одинаковых зависимостей, то условно неизбыточное покрытие ℱ0 совпадает с ℱ.
Эквивалентных зависимостей нет.
Поскольку нет зависимости с полным набором атрибутов, добавляем тривиальную зависимость U ® Æ.
Строим диаграмму зависимостей (рисунок 4), в которой учитываем непосредственное вхождение атрибутов нижестоящей зависимости в вышестоящую зависимость. Например, атрибуты зависимости E ® K непосредственно входят в зависимость A ® BEK, а атрибуты зависимости A ® BEK, в свою очередь, непосредственно входят в тривиальную зависимость. Атрибуты зависимостей M ® N и C ® D непосредственно входят только в тривиальную зависимость U ® Æ. Такая же диаграмма получится, если ранжировать зависимости.
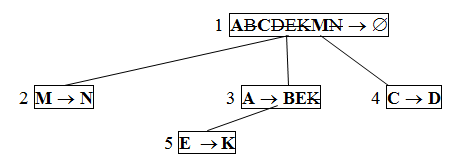
Рисунок 4 – Результат выполнения операции транзитивной редукции на диаграмме зависимостей
Выполняем на диаграмме операцию транзитивной редукции. Учитывая на диаграмме не вычеркнутые атрибуты (выделены жирным шрифтом), получаем результирующую декомпозицию:
R1 = ACM R3 = ABE R5 = EK
R2 = MN R4 = CD
Подсхема R1 = ACM содержит суперключ, так как ACM+ = ACMBEDKN = U.
Перейдя к реальным данным, получим следующий набор таблиц проектируемой базы данных:
R1 (Абитур_Препод_Экзам) = (НомерАбитур, НомерПрепод, НомерЭкзам);
R2 (Экзамены) = (НомерЭкзам, Предмет, ДатаЭкзам);
R3 (Абитуриенты) = (НомерАбитур, ФиоАбитур, Адрес, Телефон, Льгота,
КодСпец);
R4 (Преподаватели) = (НомерПрепод, ФиоПрепод, Должность)
R5 (Специальности) = (КодСпец, НазваниеСпец, ПроходнойБалл);
При изложении алгоритма синтеза было сказано, что проверку зависимостей на элементарность (шаг 5) можно опустить, и, если при этом останутся неэлементарные зависимости, то это обязательно проявится на последующих шагах. Как? Покажем это на следующем примере.
Пример 36. Рассмотрим на условиях примера 23, к чему может привести отказ от проверки зависимостей на элементарность.
Как было получено в примере 23, множество функциональных зависимостей
F = {L ® KA, A ® DOXZC, DEM ® K, D ® EK} справедливо на множестве атрибутов
U = ACDEKLMOXZ.
Выполним ускоренный синтез.
Строим расширенное множество зависимостей:
ℱ= {L ® KADOXZCE , A ® DOXZCEK, DEM ® K, D ® EK}
Анализируем множество ℱ. Оно не содержит эквивалентных зависимостей, но содержит зависимость DEM ® K, которую требуется проверить на элементарность. Опускаем эту проверку и продолжаем синтез.
Очевидно, условно неизбыточное покрытие ℱ0 совпадает с ℱ. В множестве ℱнет зависимости с полным набором атрибутов, поэтому добавляем тривиальную зависимость U ® Æ.
Строим диаграмму зависимостей, на которой выполняем операцию транзитивной редукции зависимостей (рисунок 5).
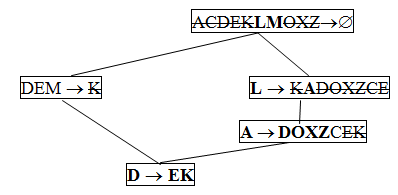
Рисунок 5 - Результат выполнения операции транзитивной редукции на диаграмме
зависимостей
В результате выполнения операции транзитивной редукции, как видно из рисунка 5, зависимость DEM ® K “осталась” без правой части. Так случилось потому, что эта зависимость не элементарная. Для проверки снова обратимся к исходному множеству зависимостей F = {L ® KA, A ® DOXZC, DEM ® K, D ® EK}.
В примере 23 было показано, что зависимость DEM ® K не элементарная, и ее можно заменить зависимостью D ® K. Тогда множество F-зависимостей можно заменить множеством
F1 = {L ® KA, A ® DOXZC, D ® K, D ® EK}.
Расширяем множество F1:
ℱ1 ={L ® KADOXZCE , A ® DOXZCEK, D ® KE , D ® EK}.
Получили две одинаковые зависимости (выделены), одна из которых, очевидно, “лишняя”. Поэтому условно неизбыточное покрытие будет таким:
ℱ10 ={L ® KADOXZCE , A ® DOXZCEK, D ® KE}.
Так как среди оставшихся зависимостей нет зависимости с полным набором атрибутов, то добавляем тривиальную зависимость U ® Æ.
На рисунке 6 показана модифицированная диаграмма зависимостей, на которой выполнена операция транзитивной редукции.
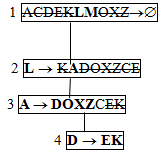
Рисунок 6 – Модифицированная диаграмма зависимостей
Результирующая декомпозиция будет такой (первичные ключи выделены):
R1 = LM; R2 = LA; R3 = ADOXZ; R4 = DEK.
Подсхема R1 = LM содержит суперключ LM, так как LM+ = LMKADOXZCE = U.
Как было сказано выше, наличие суперключа хотя бы в одной подсхеме результирующей декомпозиции является необходимым, но недостаточным условием, то есть суперключ есть, но свойство соединения без потерь информации не выполняется. Это может случиться тогда, когда в множестве F выявляются несколько возможных суперключей, которые, естественно, функционально определяют друг друга. Поясним эту ситуацию на следующем примере.
Пример 37. Пусть множество функциональных зависимостей
F = {C ® A, A ® E, KG ® CD, CD ® KG, EK ® B, BG ® C, AC ® E} справедливо на множестве атрибутов U = ABCDEKG.
Из расширенного множества ℱ, приведенного ниже, будет видно, что KG и CD – суперключи, которые функционально определяют друг друга.
Выполним ускоренный синтез.
Расширяем множество F:
ℱ ={C ® AE, A ® E, KG ® CDAEB , CD ® KGAEB, EK ® B, BG ® CAE, AC®E}.
Получили два класса эквивалентности: (C ® AE, AC®E) и (KG ® CDAEB и
CD ® KGAEB). В каждом классе оставляем одного представителя, причем в классе эквивалентности для суперключей небезразличен выбор представителя. Попробуем выбрать представителем зависимость KG ® CDAEB. Тогда условно неизбыточное покрытие будет таким: ℱ0 ={C ® AE, A ® E, KG ® CDAEB, EK ® B, BG ® CAE}.
Тривиальную зависимость добавлять не надо, так как зависимость KG ® CDAEB содержит полный набор атрибутов U.
На рисунке 7 показана диаграмма зависимостей, на которой выполнена операция транзитивной редукции.
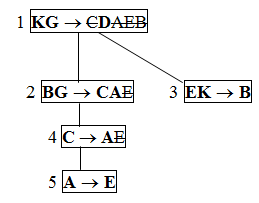
Рисунок 7 – Диаграмма зависимостей с корневой вершиной KG ® CDAEB
Результирующая декомпозиция будет такой (первичные ключи выделены):
R1 = KGD; R2 = BGC; R3 = EKB; R4 = CA; R5 = AE.
Подсхема R1 = KGD содержит суперключ KG, так как KG+ = KGCDAEB = U.
Однако проверка показала, что свойство соединения без потерь информации не выполняется.
Если же в классе эквивалентности (KG ® CDAEB и CD ® KGAEB) оставить вторую зависимость CD ® KGAEBв качествепредставителя класса, то диаграмма зависимостей будет такой, как показано на рисунке 8.

Рисунок 8 – Диаграмма зависимостей с корневой вершинойCD ® KGAEB
После выполнения на диаграмме операции транзитивной редукции зависимостей получим результирующую декомпозицию в виде:
R1 = CDKG; R2 = BGC; R3 = EKB; R4 = CA; R5 = AE.
Нетрудно проверить, что такая декомпозиция обладает свойством соединения без потерь информации.
В данном случае мы имеем два суперключа CD и KG, которые функционально определяют друг друга:
CD+ = KGAEB = U и KG+ = CDAEB = U.
Что делать, если ни одна из подсхем результирующей декомпозиции не содержит суперключа, то есть не выполнено условие необходимости. Рассмотрим такой пример.
Пример 38.. Пусть множество функциональных зависимостей
F = {AB ® C, DE ® A, G ® L, KA ® LG, C ® KDG} справедливо на множестве атрибутов U = ABCDELKG.
Выполним ускоренный синтез.
Расширяем множество F:
ℱ ={AB ® CKDGL, DE ® A, G ® L, KA ® LG, C ® KDGL}.
Поскольку расширенное множество не содержит “лишних” зависимостей с одинаковой левой частью, то условно неизбыточное покрытие ℱ0 совпадает с ℱ.
Так как среди оставшихся зависимостей нет зависимости с полным набором атрибутов, то добавляем тривиальную зависимость U ® Æ.
На рисунке 9 показана диаграмма зависимостей, на которой выполнена операция транзитивной редукции.
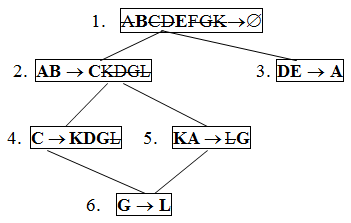
Рисунок 9 – Диаграмма зависимостей
Результирующая декомпозиция будет такой (первичные ключи выделены):
R1 = BE; R2 = ABC; R3 = DEA; R4 = CKDG; R5 = KAG; R6 = GL
Проверка показала, что свойство соединения без потерь информации не выполняется. Проанализируем результирующую декомпозицию на наличие суперключа:
BE+ = BE ≠ U; ABC+ = ABCKDL ≠ U; CKDG+ = CKDGL ≠ U; DEA+ = DEA ≠ U;
KAG+ = KAGL ≠ U; GL+ = GL ≠ U.
Видно, что ни одна декомпозиционная подсхема не содержит суперключа. Что делать? Очевидно, нужно какую-нибудь подсхему дополнить атрибутами до суперключа, тем самым выполнив условие необходимости. Практика показывает, что легче всего суперключ можно найти из зависимости, включающей полный набор атрибутов. В данном примере из зависимости, которая определяет подсхему R1. Добавив в нее атрибут D, получим суперключ BED, так как BED+ = BEDACKGF = U. Тогда R1 = BED и теперь свойство соединения без потерь информации будет выполняться.
Выполнив проектирование базы данных методом синтеза, нужно проанализировать полученные результаты. При этом можно воспользоваться следующими рекомендациями.
1. Прежде, чем выполнять проектирование, желательно уменьшить количество атрибутов, например, как это сделано в таблице 3.
2. При выполнении проектирования проверку функциональных зависимостей на элементарность можно опустить. Это обязательно проявится на диаграмме при выполнении операции транзитивной редукции зависимостей. Например, в правой части неэлементарной зависимости будут вычеркнуты все атрибуты, как в примере 36. Тогда нужно проверку этой зависимости на элементарность выполнить.
3. Свойство соединения без потерь информации выполняется для результирующей декомпозиции, если обеспечено условие необходимости (наличие суперключа в какой-нибудь декомпозиционной подсхеме [4]). Обычно суперключ остается после выполнения операции транзитивной редукции в зависимости с полным набором атрибутов, если такая зависимость есть, или в добавленной тривиальной зависимости U ® Æ. Если условие необходимости все же не выполнено, то нужно добиться его выполнения, например, как это сделано в примере 38.
4. Наличие суперключа в какой-нибудь декомпозиционной подсхеме является необходимым, но не достаточным условием выполнимости свойства соединения без потерь информации, то есть суперключ присутствует, а декомпозиция не обладает этим свойством. Такая ситуация может возникнуть, если имеется несколько возможных суперключей, которые, естественно, функционально определяют друг друга. Тогда при построении расширенного множества такие зависимости войдут в один класс эквивалентности, и потребуется дополнительные усилия по выбору представителя класса эквивалентности, как в примере 37.